Colab/27-뉴스기사_분류모델.ipynb
토큰화(Tokenizer)
학습을 위해 문장을 토큰 단위로 분할. (띄어쓰기 등 - 한글은 띄어스기 만으로는 단어 분할이 안됨)
데이터를 동일한 길이로 맞추기 (padding)
최대 단어수를 갖고 있는 문장을 기준으로 그보다 적은 단어를 갖고 있는 문장은 최대 단어수와 동일해 질 때까지 0으로 채워넣는다.
Embedding층을 사용하기 위해서는 시퀀스 데이터(여기서는 문장을 나타냄)의 길이가 전부 동일해야 한다.
길이를 맞추기 위해 pad_sequences() 함수 사용
- 데이터가 지정해준 길이보다 짧은 경우 0으로 채워 넣으며, 긴 경우는 잘라낸다.
- 단어의 뒤에 패딩을 추가하고 싶다면, padding 인자를 post로 지정한다.
Embedding(임베딩)은 문장의 길이를 동일하게 맞추는 것
padding에는 pre(앞에 0)와 post(뒤에 0)가 존재
- pre-padding일 경우에는 앞단에 0이 채워져 마지막 단어로 제로 패딩이 입력으로 들어가는 일 없이 올바른 시퀀스 모델링이 진행
- post-padding일 경우에는 뒷단에 0이 채워져 마지막 단어로 제로 패딩이 입력으로 사용
레이블(종속변수)에 대한 one-hot-encoding
명목형 처리(더미변수/카테고리화)
더미변수는변수의 값이 최소 2개를 초과할 경우 수행. 아니면 단순 category 타입으로 변경.
범주형(명목형) 데이터(카테고리가 1~3등급)를 각 카테고리별로 나누어 표현 - 명목형은 계산할 수 있는 값이 아니기 때문
명목형 변수 : 변수의 값이 고유한 순위가 없는 범주를 나타내는 경우 해당 변수
ex) 태아의 성별, 위암 등급, 승무원의 등급
명목형 확인을 위해서는 데이터의 종류가 몇 가지인지 확인.
즉, 명목형으로 의심되면 일단 value_counts()로 확인.
type, shape, info 등을 사용해 객체 형태 및 정보를 확인 가능.
sigmoid는 이항분류, softmax는 다항분류(one-hot-encoding-즉, 더미변수화)
종속변수 카테고리의 기준
탐색적 데이터 분석에서 사용하기 위해 카테고리화를 진행 - (단, 통계에서는 카테고리 형식으로 데이터를 분석하지 않고 int 형식으로 사용)
정석대로라면 카테고리로 변경하지 않음.
단, 탐색적 데이터 분석을 한다면 명목형 변수를 제거해야 하는데 명목형을 카테고리로 변경하면 자동으로 제거해주기 때문에 카테고리 형식으로 변환 후 진행.
category 대신 더미변수로 변경하면 int로 돌아오므로 더미변수화를 추천.
RNN, LSTM, GRU 비교
검증되지 않은 데이터에 대해서는 RNN이 정확도가 높다.
하지만, 학습 속도, 예측 결과를 포함한 전반적인 평가에서는 GRU가 가장 만족스러운 결과를 도출.
GRU 최고.
GRU >> LSTM >>> RNN
IMDB GRU, (RNN, LSTM)
RNN은 순서와 맥락을 고려하지는 않음
-> 일치하는 단어가 얼마나 있는가를 확인
#01. 텍스트 분석 알고리즘
1. 텍스트 분석을 위해 개선된 알고리즘의 종류
GRU
이게 최고임
- 게이트 메커니즘이 적용된 RNN의 일종으로 LSTM에서 영감을 받았으며 더 간략한 구조를 갖는다.
- 한국인 조경현 박사님이 제안한 방법
RNN
- Embedding층은 단순하게 데이터의 표현을 학습하여 데이터 사전을 구축하는 것
- 하지만 유사한 의미의 단어를 비슷한 공간에 매핑할 수 있지만, 시퀀스 데이터의 중요한 특성인 순서와 맥락까지 고려한 것은 아니다.
- 순환 신경망은 이 문제를 해결하기 위해 고안된 층
- 완전연결층, 컨볼루션 신경망의 반대되는 개념.
- 완전연결층과 컨볼루션 신경망은 피드 포워드 네트워크(feed-forward network)라고 표현
- 피드 포워드 네트워크는 신경망이 가지는 모든 출력값이 마지막층인 출력층을 향한다.
- 하지만 순환 신경망은 각 층의 결과값이 출력층을 향하면서도 동시에 현재 층의 다음 계산에 사용된다.
LSTM
- RNN의 그래디언트 손실문제를 보완한 방법
- 정보를 여러 시점에 걸쳐 나르는 장치(‘Cell state’)가 추가되었다.
- 이로 인해 그래디언트를 보존할 수 있어 그래디언트 손실 문제가 발생하지 않도록 도와준다.
2. 텍스트 분석 알고리즘 적용하기
전체 소스코드는 지금까지의 예제들과 동일하게 진행된다.
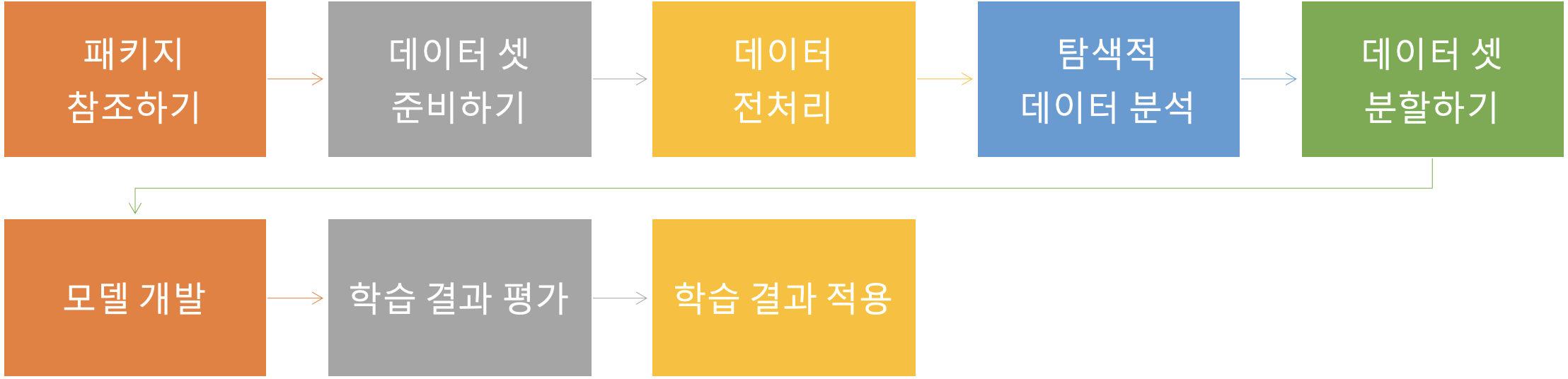
💡 패키지 준비 → 데이터셋 준비 → 데이터 전처리 → 탐색적 데이터 분석(문자열 토큰화, 데이터를 동일한 길이로 맞추기) → 데이터 셋 분할 → 모델 개발(정의+학습) → 학습 결과 평가 → 학습결과 적용이 과정에서 학습 모델을 정의하는 부분에서 적용할 알고리즘만 변경하면 되기 때문에 여기서는 RNN을 먼저 적용해 본 후, 학습 모델을 LSTM과 GRU로 각각 변경하여 다시 학습을 수행해 보도록 한다.
학습 시간이 매우 오래 걸리는 예제이므로 가급적 GPU가 탑재된 컴퓨터에서 실습하는 것이 좋다.
모델 정의(GRU)
정석대로라면 1차는 LSTM, 2차는 GRU로 실행하면 정확성이 높지만 시간이 오래 걸림.
return_sequences 파라미터가 True로 지정되면 모든 학습 시점의 은닉 상태를 출력해 준다. False인 경우는 마지막 시점의 은닉 상태만 출력한다. (기본값=False)
dropout은 지정된 비율만큼 학습을 건너뛰게 하는 파라미터. 이 파라미터를 사용하게 되면 과거 학습정보를 잃어버릴 확률이 높아지고 그에 따라 모델 성능이 나빠질 가능성이 있다.
dropout은 무작위로 건너뛰는 비율로 학습 속도는 향상되지만 과거 학습 정보를 잃어버릴 확률이 높아져 모델의 성능 저하가 발생할 수 있음.
recurrent_dropout(순환드롭아웃)은 과거 학습정보를 잃어버리는 문제를 해결하기 위해 적용하는 옵션.
Embedding층은 모델의 첫 번째 층으로만 사용할 수 있으며, 주로 순환 신경망과 연결하여 사용.
filter가 클수록, kernel_size가 작을 수록 모델이 성능이 개선됨.
단, 학습 시간도 오래 걸림.
activation : 다중분류 = softmax, unit 10, 이진분류 = sigmoid, unit 1/0 - 주로
relu
loss : 다중분류 = categorical_crossentropy, 이진분류 = binary_crossentropy
Sequential : 모델을 하나 하나 차례로 집어 넣는다
Dense : 완전 연결 층
optimizer : 경사하강법 변화 버전(sgd, adam 등등)
metrics : 평가지표(학습 판단 기준) mse, mae, acc 등
output_dim : 작아질 수록 정확도 하락, 성능 상승
학습하기
- epochs는 많아도 크게 상관이 없음(단, 너무 크면 오래 걸리고 검증 오차가 증가)
- callback을 사용해 모델의 학습 방향, 저장 시점, 학습 정지 시점 등에 관한 상황을 모니터링
- EarlyStopping 콜백과 같이 patience 인자를 지정하여, 지정된 기간 동안
평가지표에서 성능 향상이 일어나지 않으면 학습률을 조정하는 콜백 - ReduceLROnPlateau EarlyStopping 콜백과 같이 patience 인자를 지정하여, 지정된 기간 동안
평가지표에서 성능 향상이 일어나지 않으면 학습률을 조정하는 콜백 - ModelCheckpoint 지정한 평가지표를 기준으로 가장 뛰어난 성능을 보여주는 모델을 저장 할 때 사용
자연어 모델 평가/특징
자연어 처리는 학습한 데이터 내에서는 정확성이 준수하지만 학습하지 못한 데이터 내에서는 정확성이 떨어짐.
즉, 자연어 처리는 학습 데이터 양에 따라 성능이 좌우됨.
