데이터 정확도는 의학 분야가 아닌 이상 50~60%면 잘 나온 것. 특히 스포츠는 50%만 나와도 선방
클라우드 컴퓨팅
실무에서 대용량의 데이터를 사용하는 방법.
대용량 데이터를 분석하기 위해 고성능의 컴퓨터가 필요할 경우 시간 단위로 가상환경을 통해 분석하는 서비스.
데이터 분석은 고사양 컴퓨터를 제공하는 경우가 적은 만큼 임대 즉, 호스팅을 사용. Docker를 사용해 접속, 서비스를 제공.
sklearn에서 성능을 평가하는 기능이 있음(분석의 단위가 아닌 하드웨어 성능)
KNN(지도학습) 마무리
성능평가(모델 성능, HW 메모리 성능 평가)
군집(비지도학습)
k-means 클러스터링
군집 모델 구현
n_clusters : 군집의 갯수, n_init : 초기 중심위치 수, random_state : 시드 값 고정(재현성)
연구 목적이 아닌 실무에서 random_state는 배제
군집
분류와 달리 정답(종속변수) 레이블이 없는 문제.
- 분류 : KNN
- 군집 : KMeans
데이터를 몇 개의 묶음(클러스터, Cluster)으로 나눌 것인지를 하이퍼 파라미터러 결정하며 이 값이 KMeans의 값이됨.
데이터 전처리 단계에서 라벨링을 위해 사용하기도 함.
군집화 모델 구현
n_clusters : 군집의 갯수, n_init : 초기 중심위치 수, random_state : 시드 값 고정(재현성)
연구 목적이 아닌 실무에서 random_state는 배제
데이터 표준화
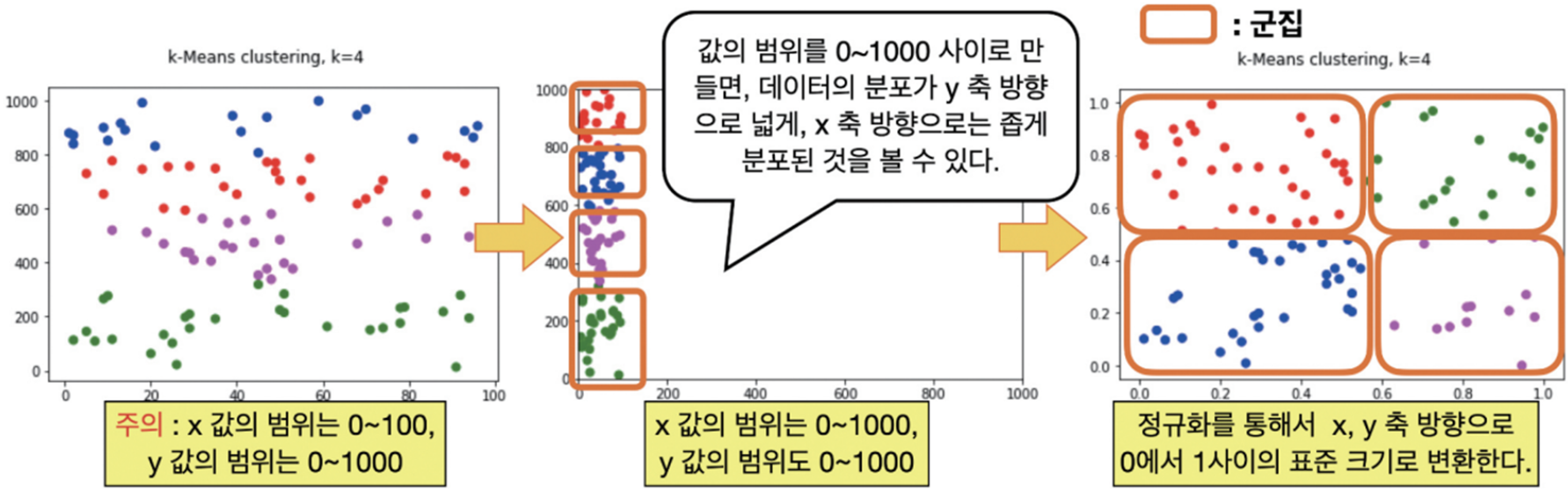
스케일링 결과를 군집화
n_clusters : 군집의 갯수, n_init : 초기 중심위치 수, random_state : 시드 값 고정(재현성)
연구 목적이 아닌 실무에서 random_state는 배제
군집 결과를 DF로 구성 및 시각화
군집 평가
Inertia
KMeans 클러스터링의 성능 지표
각 샘플과 중점이 이동하는 자취 사이의 평균 제곱거리 측정 값
Inertia 값은 클러스터 수와 반비례 관계
클러스터 수를 늘려가면서 반복적으로 실행하면 값이 점점 작아진다
클러스터 수가 늘어감에 Inertia가 급격히 감소하고 어느 지점부터는 완만하게 감소하는 지점이 생기는데 이 지점이 최적 클러스터 수를 의미(=엘보우(Elbow))
엄연히 주관인 만큼 분석가마다 차이가 발생할 수 있음
실루엣 점수(계수)
각 군집간의 거리가 얼마나 효율적으로 분리됐는지를 나타내는 지표
효율적 분리 : 어떤 한 점이 다른 군집과는 멀리 떨어져 있고, 동일 군집끼리는 서로 가깝게 잘 뭉쳐있음을 의미
개별 데이터가 같은 군집과는 얼마나 가깝고, 다른 군집의 데이터와는 얼마나 멀리 분리되어 있는가를 나타내는 값
sklearn은 전체 실루엣 점수의 평균값을 반환하는 silhouette_score() 함수를 제공
리턴값은 -1~1의 범위를 가지며 1에 가까울 수록 좋은 군집으로 판단
0인 경우는 클러스터가 겹치는 것을 의미
음수값은 일반적으로 샘플이 잘못된 클러스터에 할당되었음을 의미
실루엣 방법은 점수가 나오는 만큼 비교적 더 정확함
최종 군집 평가
실루엣 점수가 가장 높은 N개의 군집으로 클러스터링 수행
