Decision Tree(의사결정나무)란?
ML 알고리즘 중 직관적으로 이해하기 쉬운 알고리즘
데이터를 여러 등급으로 분류 하는 지도 학습 방법 중 하나
데이터에 있는 규칙을 학습을 통해 자동으로 찾아 Tree 기반의 분류 규칙을 만듦
데이터를 어떤 기준을 가지고 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 성능을 좌우함
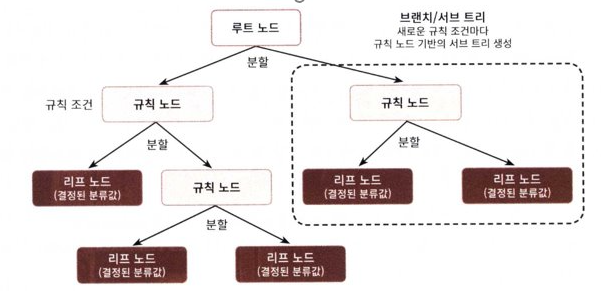
- 트리의 구조
규칙 노드(Decision Node): 규칙 조건
리프 노드(Leaf Node): 결정된 클래스 값
서브 트리(Sub Tree): 새로운 규칙 조건마다 규칙 노드 기반의 서브 트리 생성
- Decision Tree의 특징

참고
지니 계수와 엔트로피는 실제로 큰 차이 없이 비슷한 트리를 생성함. 지니 계수가 조금 더 계산이 빠르기 때문에 기본값으로 좋으나, 다른 트리가 만들어지는 경우 지니 불순도가 가장 높은 클래스를 한쪽 가지로 고립시키는 경향이 있는 반면 엔트로피는 조금 더 균형 잡힌 트리를 생성
Scikit-Learn 패키지
-
DecisionTreeClassifier 클래스
분류를 위한 클래스 -
DecisionTreeRegressor 클래스
회귀를 위한 클래스 -
사이킷런의 결정 트리 구현은 CART(Classification And Regression Trees) 알고리즘 기반
CART는 이진 트리만 사용하며 리프 노프 외의 모든 노드는 자식 노드를 두 개씩 가질수 있음
(즉, 질문의 대답을 Yes or No로 대답)
ID3 같은 알고리즘은 둘 이상의 자식 노드를 가진 결정 트리를 만들수 있음 -
CART는 분류뿐만 아니라 회귀에서도 사용될 수 있는 트리 알고리즘
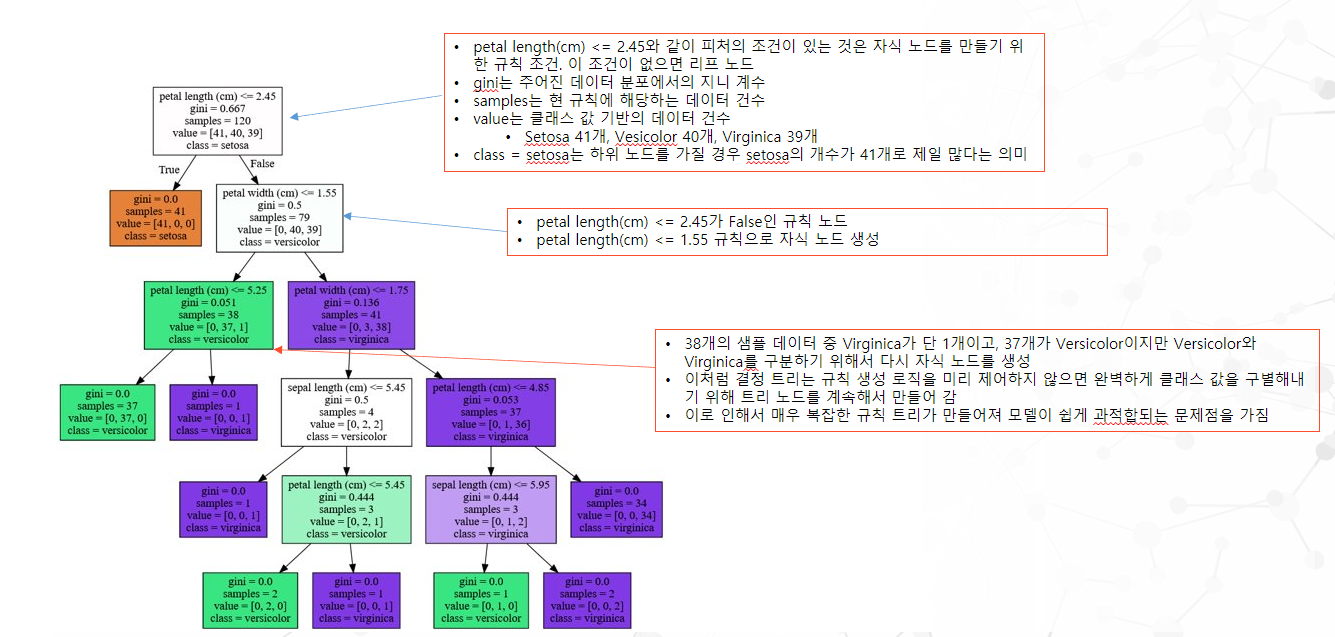
실습예제 - Iris
- Iris 데이터를 이용한 Decision Tree 적용
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings # 경고문 무시
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=42)# iris 데이터 불러온 뒤, train data와 test data로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=42)
# DecisionTreeClassifier 학습
dt_clf.fit(X_train, y_train)# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일 생성
from sklearn.tree import export_graphviz
export_graphviz(dt_clf, out_file='tree.dot', class_names = iris_data.target_names,
feature_names=iris_data.feature_names, impurity=True, filled=True)
# 생성된 tree.dot 파일을 Graphviz 읽어서 시각화
with open("./tree.dot") as f:
dot_graph = f.read()
import graphviz
graphviz.Source(dot_graph)Iris 데이터 Graphviz를 사용한 시각화
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)
- 실행결과
Feature importances:
[0.025 0. 0.555 0.42]
sepal length (cm) : 0.025
sepal width (cm) : 0.000
petal length (cm) : 0.555
petal width (cm) : 0.420
# 출력값은 feature 순서대로 할당되며 값이 높을수록 해당 feature의 중요도가 높다는 의미
(petal_length가 가장 중요도 높음)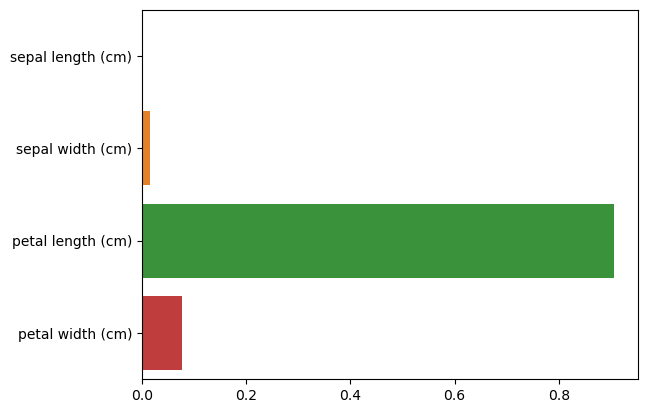

공부 기록