Spark 설치
wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz 해서 다운로드 받기
tar xzf spark-3.2.4-bin-hadoop3.2.tgz 압축 해제
mv ./spark-3.2.4-bin-hadoop3.2 ./spark 이름 바꾸기
conf 파일 업로드
/home/hadoop/spark/conf 경로에 강사님이 올려주신 파일 3개 넣기
- Fillzilla 이용

bash.rc 설정
- 스파크 환경변수, 실행경로 설정
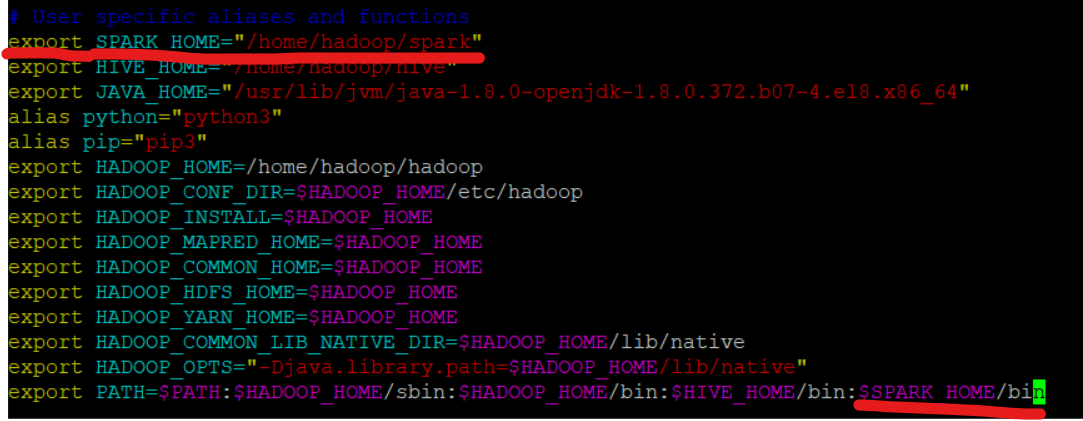
설정후 source ~/.bashrc써서 적용시키기
spark 실행
pyspark 명령어를 실행
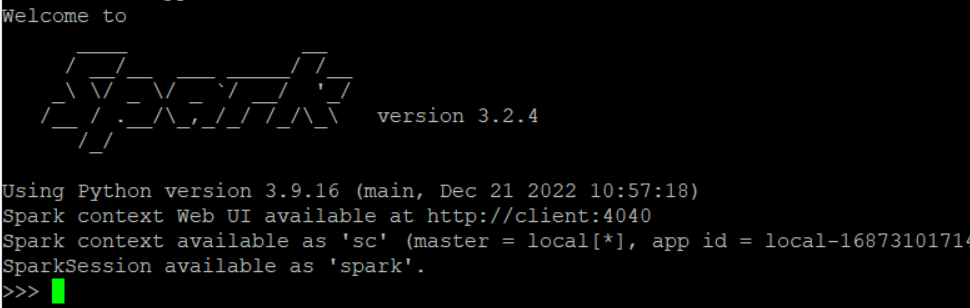
exit()로 나오고 다음 세팅 준비
jupyter 세팅
pip install jupyter #주피터 설치
jupyter notebook --generate-config jupyter notebook --generate-config- jupyter notebook --generate-config 명령어를 실행하면 기본값으로 설정된 Jupyter Notebook 설정 파일(jupyter_notebook_config.py)이 생성
- 이 파일이 생성되면 사용자는 해당 파일을 편집하여 Jupyter Notebook의 IP 주소, 포트 번호, 실행 모드(인라인 플롯 등), 보안 설정(비밀번호, SSL, 토큰 등) 및 기타 설정을 변경할 수 있음
jupyter 실행
ipython 실행
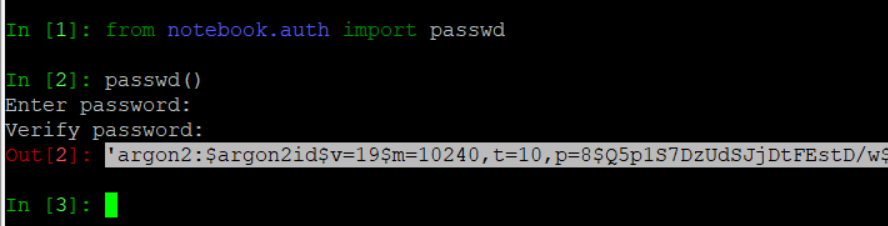
from notebook.auth import passwd
- 자신의 노트북 암호 만들기
passwd()- 자신의 원하는 암호 입력 / 입력하고 나오는 문자열 복사해두기(이후에 편집기에서 넣어야 됨)
vim ~/.jupyter/jupyter_notebook_config.py편집기 아래와 같이 수정
136번 줄 : 모든 도메인에서 접속 가능하도록 설정
450번 줄 : 노트북 디렉토리 설정
458번 줄 : 주피터 노트북이 시작될 때 웹 브라우저를 자동으로 열지 않도록 함
469번 줄 : 주피터 노트북에 암호를 설정 (아까 복사해둔 문자열 복사)




작업폴더 만들기
mkdir workspace
pyspark --master yarn --num-executors 3
- pyspark --master yarn --num-executors 3 명령어는
- pyspark: PySpark 명령어로, PySpark 애플리케이션을 실행한다.
- PySpark은 Apache Spark를 사용하여 파이썬으로 효율적인 빅 데이터 처리를 가능하게 해준다.
- --master yarn: 이 옵션은 애플리케이션의 클러스터 관리자를 YARN(Yet Another Resource Negotiator)으로 설정합니다.
- YARN은 클러스터에서 자원 관리를 담당하며, 맵리듀스 및 다양한 애플리케이션 프레임워크가 하둡에서 실행될 수 있도록 한다.
- --num-executors 3: 이 옵션은 클러스터에서 사용할 Spark Executor의 개수를 3으로 설정한다.
- Executor는 Spark 애플리케이션에서 작업 작업(load data, process, store)을 수행하는 프로세스
- pyspark: PySpark 명령어로, PySpark 애플리케이션을 실행한다.
nohup pyspark --master yarn --num-executors 3 &
- nohup: 터미널이 종료된 후에도 계속 실행되도록 설정, 터미널과의 연결이 끊겨도 프로세스가 중단되지 않음
- &: 주어진 명령어를 백그라운드에서 실행
위 명령어 실행 후 화면에 아래와 같은 것이 보이면 http://client:8888로 들어간다.

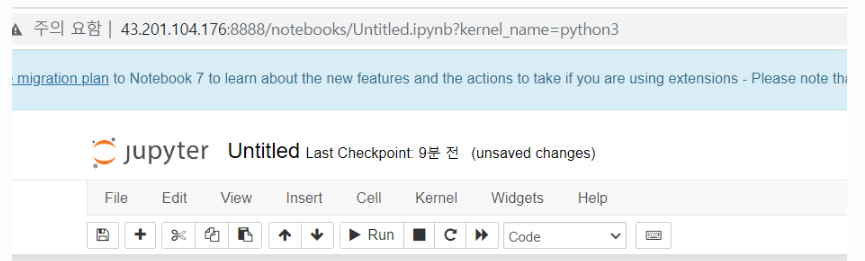
이후, 아래 명령어 실행
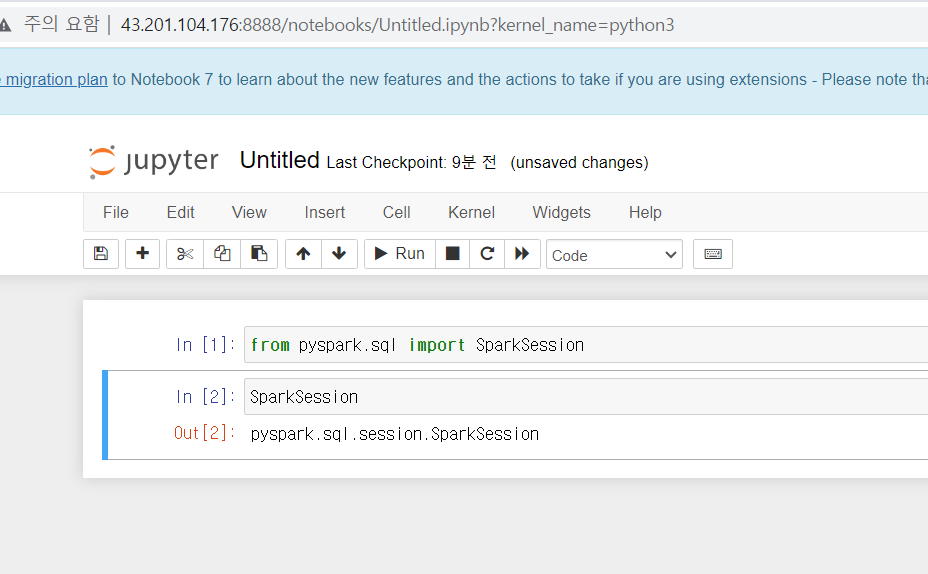
from pyspark.sql import SparkSession
SparkSession
- SparkSession은 Apache Spark 애플리케이션을 시작하는데 필요한 프로그래밍 진입점(entry point)이다.
- 이를 통해 DataFrame과 Dataset의 생성과 작업을 관리하고, cluster manager와 application name, executor memory, number of executor cores 등의 Spark 애플리케이션 설정을 구성할 수 있다.
- 또한, SparkSession은 다양한 데이터 소스와 직접 연결할 수 있는 read 및 write 메서드를 지원한다.
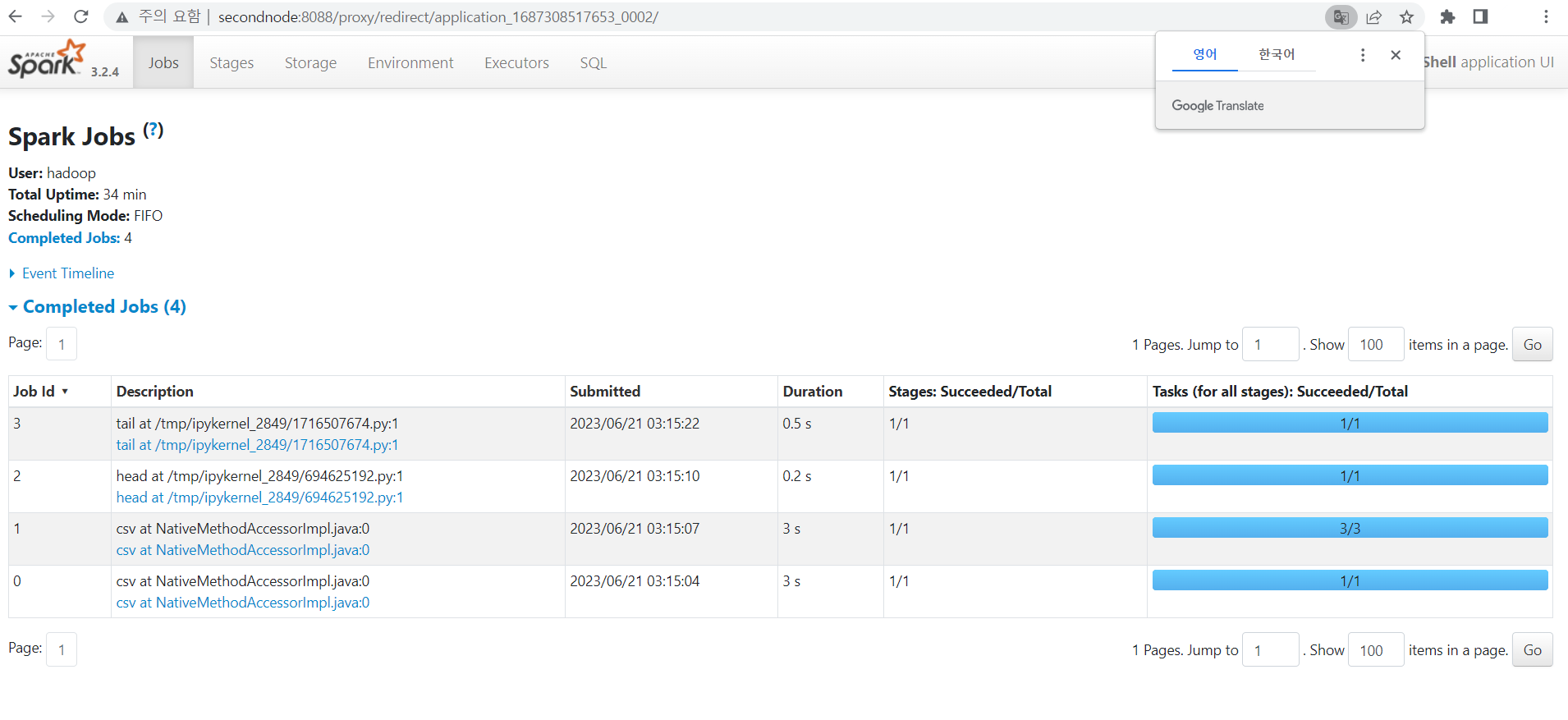
- secondnode:8088이나 client 퍼블릭v4 ip주소(탄력적 ip설정했다면 탄력적ip):4040를 보면 아래와 같은 화면을 볼 수 있음
jupyter Directory에 spark 예제.ipynb와 hflight.csv 파일 업로드


참고
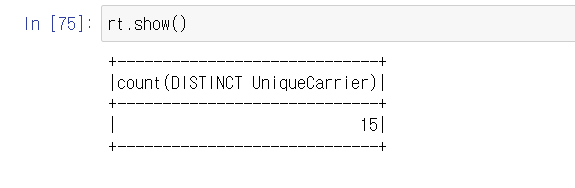
- spark는 코드를 다 만들고 실행하면 실행 계획만!
- show나 action을 통해 실행이 일어남!

용어 정리
다음시간에 사용할 파일
Parquet이란?
- 대량의 데이터를 효율적으로 저장하고 처리하기 위한 열 지향(컬럼 기반) 파일 형식이다. Parquet 파일은 대규모 데이터 처리를 위해 설계되었으며, Hadoop 기반의 분산 데이터 처리 시스템인 Apache Hadoop, Apache Spark, Apache Hive 등에서 널리 사용된다.
Parquet은 다양한 데이터 처리 작업에 적합한 형식을 제공한다. 일반적으로 데이터 웨어하우스, 비즈니스 인텔리전스 및 대규모 분석 시나리오에서 사용되며, 특히 대규모 데이터 세트에서의 쿼리 성능을 향상시킬 수 있다. Parquet 파일은 데이터를 컬럼 기반으로 저장하므로 필요한 컬럼만 읽거나 필터링할 수 있어서 읽기 작업의 효율성을 높인다. 또한 압축 및 직렬화 알고리즘을 사용하여 저장 공간을 절약하고 데이터 전송 속도를 높일 수 있다.
