이전 포스트에서 다뤘던 spark 세션을 띄우고자 했지만, 실패한 것에 해결에 대한 기록
pyspark --master yarn --num-executors 5 명령어를 이용하여 YARN으로 PySpark를 실행하였지만, 이건 pyspark kernel이 아니라 Python 3 이었다.
단일 노드에서 spark를 사용하는 로컬 세션을 생성했던 것이었다.
어쩐지 경로 보려고 tab키를 눌렀는데, 로컬 경로가 나왔었다.
해결
크게는 2가지 pyspark 세션 생성. python 버전을 낮추는 것이었다.
해결 과정
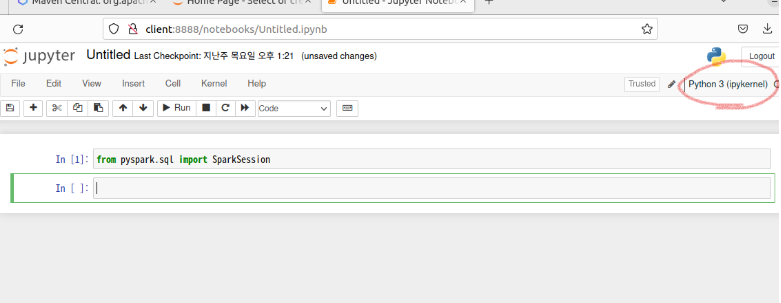
- Pyspark 커널 만들기
pyspark를 CLI환경이 아니라 Jupyter를 사용해서 작업 환경을 만들고 싶었기 때문에
PySpark 커널의 명령 줄 인수, 사용할 프로그래밍 언어, 추가 메타데이터, 환경 변수 등을 정의하였다.
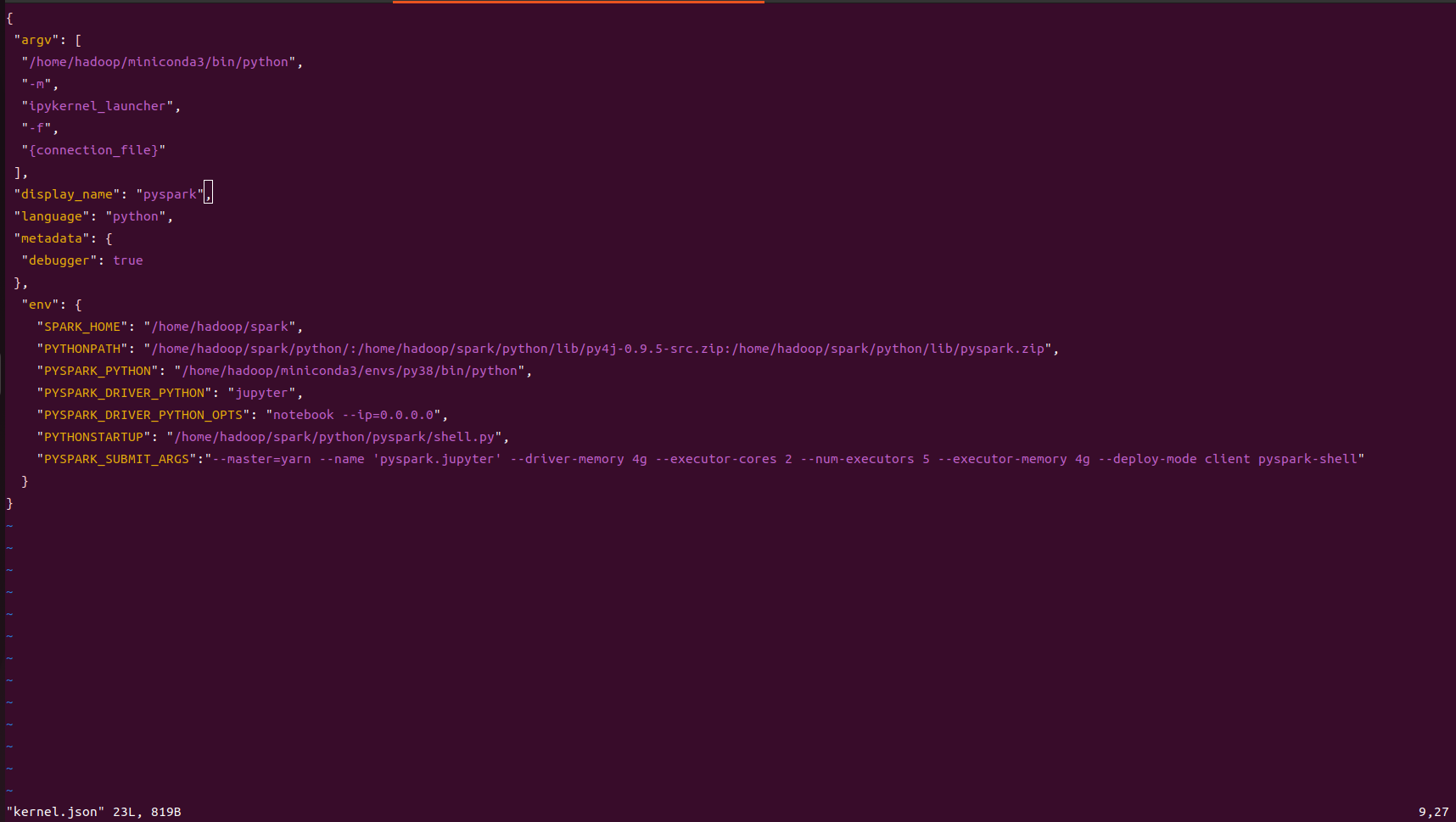

- shell.py 만들기
Pyspark 실행 환경을 설정하고 초기화 하는 코드를 가지고 있는 py파일
import atexit
import os
import platform
import warnings
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
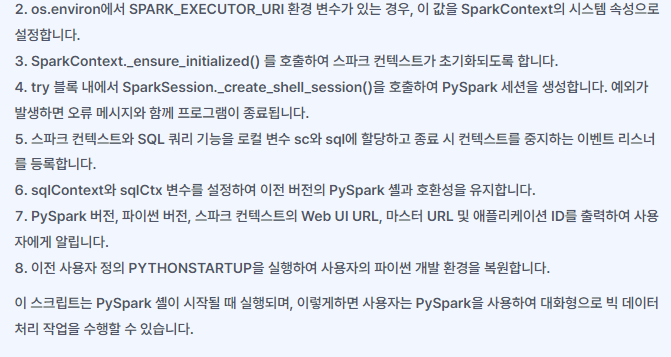
if os.environ.get("SPARK_EXECUTOR_URI"):
SparkContext.setSystemProperty("spark.executor.uri", os.environ["SPARK_EXECUTOR_URI"])
SparkContext._ensure_initialized() # type: ignore
try:
spark = SparkSession._create_shell_session() # type: ignore
except Exception:
import sys
import traceback
warnings.warn("Failed to initialize Spark session.")
traceback.print_exc(file=sys.stderr)
sys.exit(1)
sc = spark.sparkContext
sql = spark.sql
atexit.register((lambda sc: lambda: sc.stop())(sc))
# for compatibility
sqlContext = spark._wrapped
sqlCtx = sqlContext
print(r"""Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version %s
/_/
""" % sc.version)
print("Using Python version %s (%s, %s)" % (
platform.python_version(),
platform.python_build()[0],
platform.python_build()[1]))
print("Spark context Web UI available at %s" % (sc.uiWebUrl))
print("Spark context available as 'sc' (master = %s, app id = %s)." % (sc.master, sc.applicationId))
print("SparkSession available as 'spark'.")
# The ./bin/pyspark script stores the old PYTHONSTARTUP value in OLD_PYTHONSTARTUP,
# which allows us to execute the user's PYTHONSTARTUP file:
_pythonstartup = os.environ.get('OLD_PYTHONSTARTUP')
if _pythonstartup and os.path.isfile(_pythonstartup):
with open(_pythonstartup) as f:
code = compile(f.read(),_pythonstartup, 'exec')
exec(code)
- Python 버전 낮추기
💡 Tip
venv는 설치된 파이썬 버전으로만 가상환경을 생성할 수 있습니다.
예를 들어, 여러분이 시스템에 Python 3.9 버전을 설치했는데
3.8 버전으로 프로젝트를 진행하고자 한다면 venv로는 이 문제를 해결할 수 없습니다.
파이썬 3.8 버전도 여러분의 PC에 설치를 해야합니다.
이와 달리 아나콘다의 conda는 아나콘다 배포판의 파이썬이 3.9 버전이라고 하더라도
3.8 버전으로 가상환경을 만들 수 있습니다.
python 3.10 버전을 사용중이었는데, Spark와 호환이 안된다는 에러 문구가 나와 가상환경을 이용하여 3.8버전으로 낮춰주었다.
conda create -n py38 python=3.8 # py38 이름을 가진 가상환경을 만들어 python 3.8버전 설치
conda env list 가상환경 생성되었나 확인
conda activate py38 py38 가상환경 접속
.bashrc 수정
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook --ip=0.0.0.0'
export PKG_CONFIG_PATH="/path/to:$PKG_CONFIG_PATH"이후에는 py38 가상환경으로 접속하여 notebook --ip=0.0.0.0 명령어를 통해
스파크를 실행하는데 성공하였다.
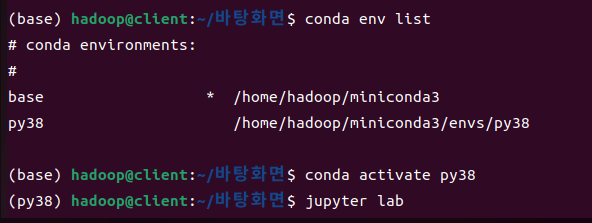
해결한 후 화면
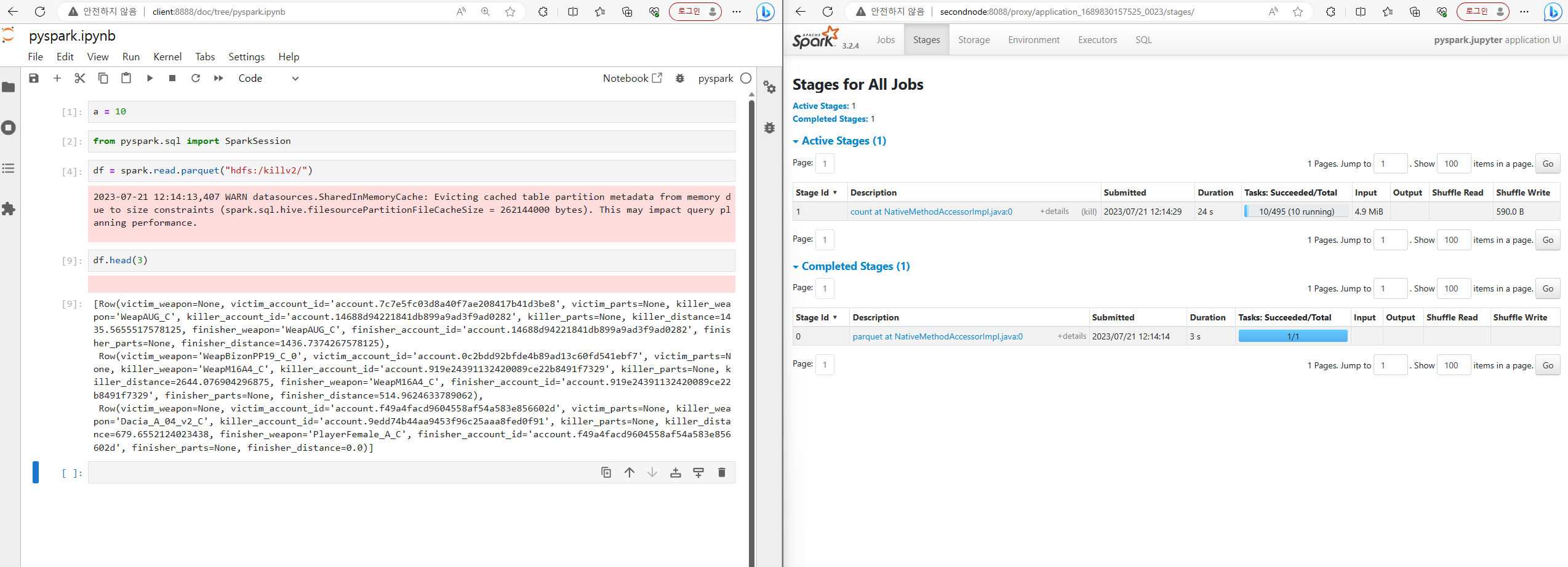
배틀그라운드 데이터 하둡에 저장하기
팀원들이 개인 pc나 kict 인프라를 통해 적재해온 배틀그라운드 로그 데이터를
client pc에 모두 옮겨담았다.
hdfs dfs -put ./hdfs/b/parquets/killv2/* /killv2 명령어를 사용하여 client 로컬에 있던 파일들을 모두 하둡에 저장하였다.
- 저장

(base) hadoop@client:~/hdfs/b/parquets/killv2$ ls -l | grep "^-" | wc -l
193595개의 파케이 파일을 업로드하여 데이터 준비를 마쳤다.
