Sorting
df = df.sort_values(by=['Col_A', 'Col_B']).reset_index(drop=True)
df = df.sort_values(by='Col_A', ascending = False)
nunique() vs unique() vs value_counts()

df['Col_A'].nunique()
- It calculates the number of unique Col_A

df['Col_A'].unique()
- It shows all unique Col_A rows
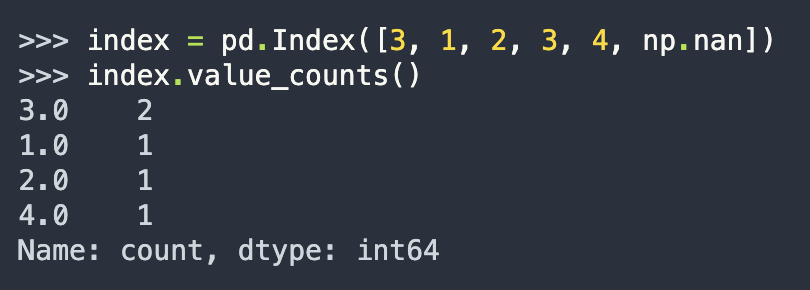
df['Col_A'].value_counts()
- It returns a series of containing counts of unique values.
Drop column
df = df.drop(columns=['Col_A,', 'Col_B'])
Min & Max of the date
df['Col_date'] = pd.to_datetime(df['Col_date'])
min_date = df['Col_date'].min()
max_date = df['Col_date'].max()
duration = max_date - min_date
| Detail | Date |
|---|
| Min_Date | 2022-01-01 |
| Start_Date | 2023-12-31 |
| Duration | 729 days |
.groupby()
df['time'] = pd.to_datetime(recent['time'])
df['Year'] = df['time'].dt.year
df['Quarter'] = df['time'].dt.to_period('Q')
quarterly_sub = df.groupby(['Year', 'Quarter'])['user_id'].nunique().reset_index()
quarterly_sub['Quarter'] = quarterly_sub['Quarter'].astype(str)
quarterly_sub.columns = ['Year', 'Quarter', '# of sub_user']
print(quarterly_sub)
| Year | Quarter | # of sub_user |
|---|
| 2022 | 2022Q1 | 17628 |
| 2022 | 2022Q2 | 15280 |
| 2022 | 2022Q3 | 10722 |
| 2022 | 2022Q4 | 14757 |
| 2023 | 2023Q1 | 24983 |
| 2023 | 2023Q2 | 17241 |
| 2023 | 2023Q3 | 21180 |
| 2023 | 2023Q4 | 23342 |
- It groups the df by the Year and Quarter cols, and then it counts the # of unique user_id values in each group. This calculation determines how many distinct users perfromed the action logged in 'time' within each quarter.
- It converts it into a string for easier readability and use in displays or reports.
.astype()
df.astype(dtype, copy=True, errors='raise')
drop_duplicates() vs .duplicated()
df.drop_duplicates(subset=None, *, keep='first', inplace=False, ignore_index=False)
df.drop_duplicates(subset=['Col_A'])
- It returns dataframe with duplicate rows removed.
df.duplicated(subset=None, keep='first')
df.dulicated()
