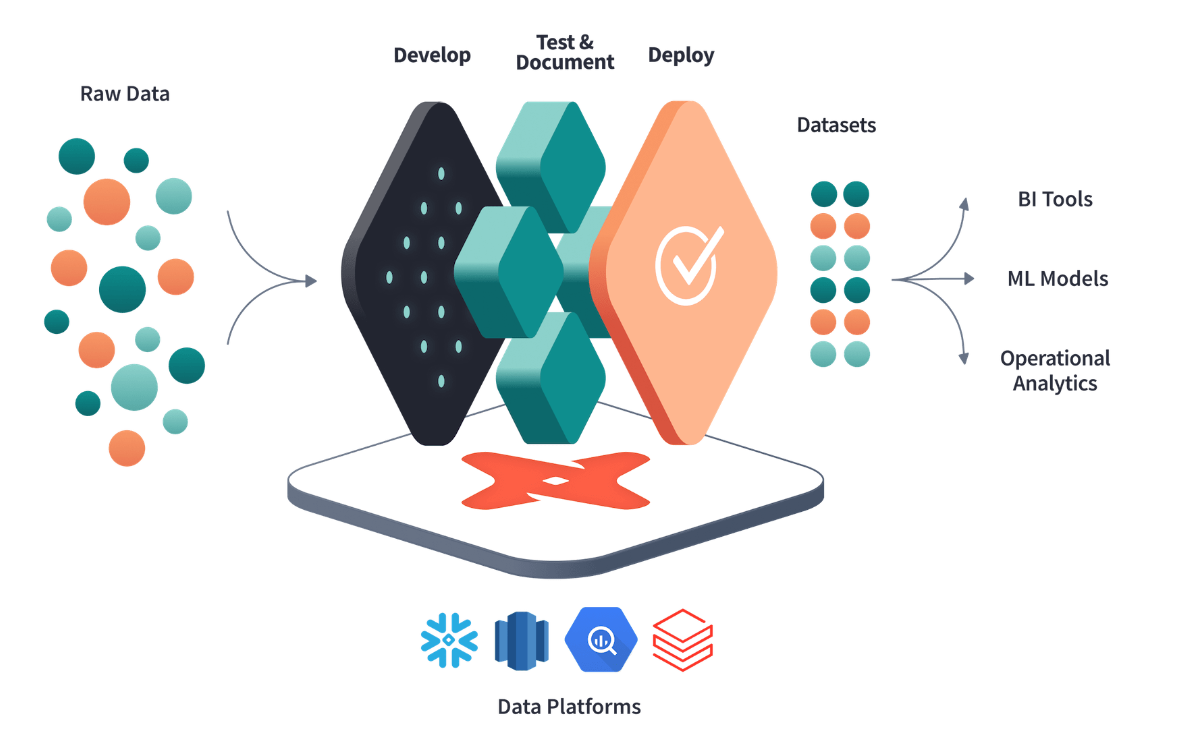
Intro
스노우플레이크 데이터 웨어하우스를 구축을 했다면 dbt와 연동을 시켜 데이터 변환하는 작업을 수행하였다. dbt는 데이터 가공에 있어 transformation에 집중되어있다. 나눈 스노우플레이크 내에서 데이터를 처리하는 방법을 사용하였다. Raw 데이터를 올린 이후에 쿼리로 변경하거나 테이블 생성시 Snowsight UI에서 직접 변경하는 방법도 있다. 하지만 SQL 기반으로 데이터를 처리하는 것의 안 좋은 점은 코드로 관리가 안된다는 것이다. 쿼리로 진행시 ad-hoc 한 쿼리가 많이 생기고 나중에 재사용할 때 다시 작성하는 경우도 있고 쿼리를 수정해도 버전 관리 문제로 쿼리의 히스토리도 파악하기 어려워진다. 또한, 성능이나 안정성을 고려해서 SQL 을 작성하다보니 가독성이 떨어지고 유지보수 또한 어려워지는 상황이 발생한다. 그래서 이러한 쿼리들을 통합하고 정형화하는 방법을 사용해보고자 dbt 사용을 하게 되었다. dbt를 사용하면 SQL 쿼리 코드 관리, 코드 재사용 용이, 또한 많은 데이터가 저장되면 누가 어떤 걸 만들었고, 어떻게 관리되고 있는지 모니터링이 안되기에 오너쉽 관리를 통한 히스토리 추적이 가능하다.
dbt 란?
특징
- DBT는 ELT의 T(Transform)를 담당한다.
- 코드 재사용이 가능하다. DBT는 데이터 모델이라는 것을 통해 결과물을 정의하면서 여러 패키지들을 재사용한다.
- 연동하는 과정에는 CLI 와 dbt Cloud 두 가지 방법이 있다.
- Git을 통해 버전관리가 가능하고 팀에서 협력하여 작업을 할 수 있다.
- select문을 작성함으로써 모듈화된 SQL 모델을 만들 수 있다. dbt에서는 이러한 select문을 table, view로 변환해서 만들어주는 역할을 한다.
- 데이터 계보를 통해 데이터의 흐름을 시각화하여, 데이터 버전관리 및 의존성 파악 문제를 해결한다.
- 사용자는 SQL만 알아도 쉽게 이용할 수 있고, yaml 파일만 이용하면 어떤 테이블이든 테스트, 문서화등의 작업을 쉽게 할 수 있다.
Materialization 란?
✅ 갑자기 뜬금없이 단어 설명이 나와서 의문일 수 있다. 입력 데이터(테이블)들을 연결해서 새로운 데이터(테이블)를 생성하는 것. 여기서 transformation 이나 clean-up 을 수행한다. SQL 모델을 물리적으로 저장하는 방식을 의미하며 총 4가지의 방식이 있다.
1. View
데이터를 잘 사용하지 않는 경우, 모델 결과를 DB의 테이블에 저장
{{
config(
materialized='table',
sort='timestamp',
dist='user_id')
}}
select *
from ...
--- target directory log
-- target/run/{project_name}/models/{schema}/{model_name}.sql
create or replace transient table {table_name} as (
...
)2. Table
데이터를 반복해서 자주 사용하는 경우
{{
config(
materialized='view',
indexes=[{'columns': ['col_a'], 'cluster': 'cluster_a'}]) }}
indexes=[{'columns': ['symbol']}])
}}
select ...3. Incremental(Table Appends)
Fact 테이블, 과거 레코드를 수정할 필요가 없는 경우
{{ config( materialized='incremental', unique_key='date_day', incremental_strategy='delete+insert', ... ) }} select ... -- target directory 로그 -- target/run/{project_name}/models/{schema}/{model_name}.sql insert into {table_name} as (...) (...)
4. Ephemeral(CTE)
한 SELECT에서 자주 사용되는 데이터를 모듈화 하는데 사용
구성
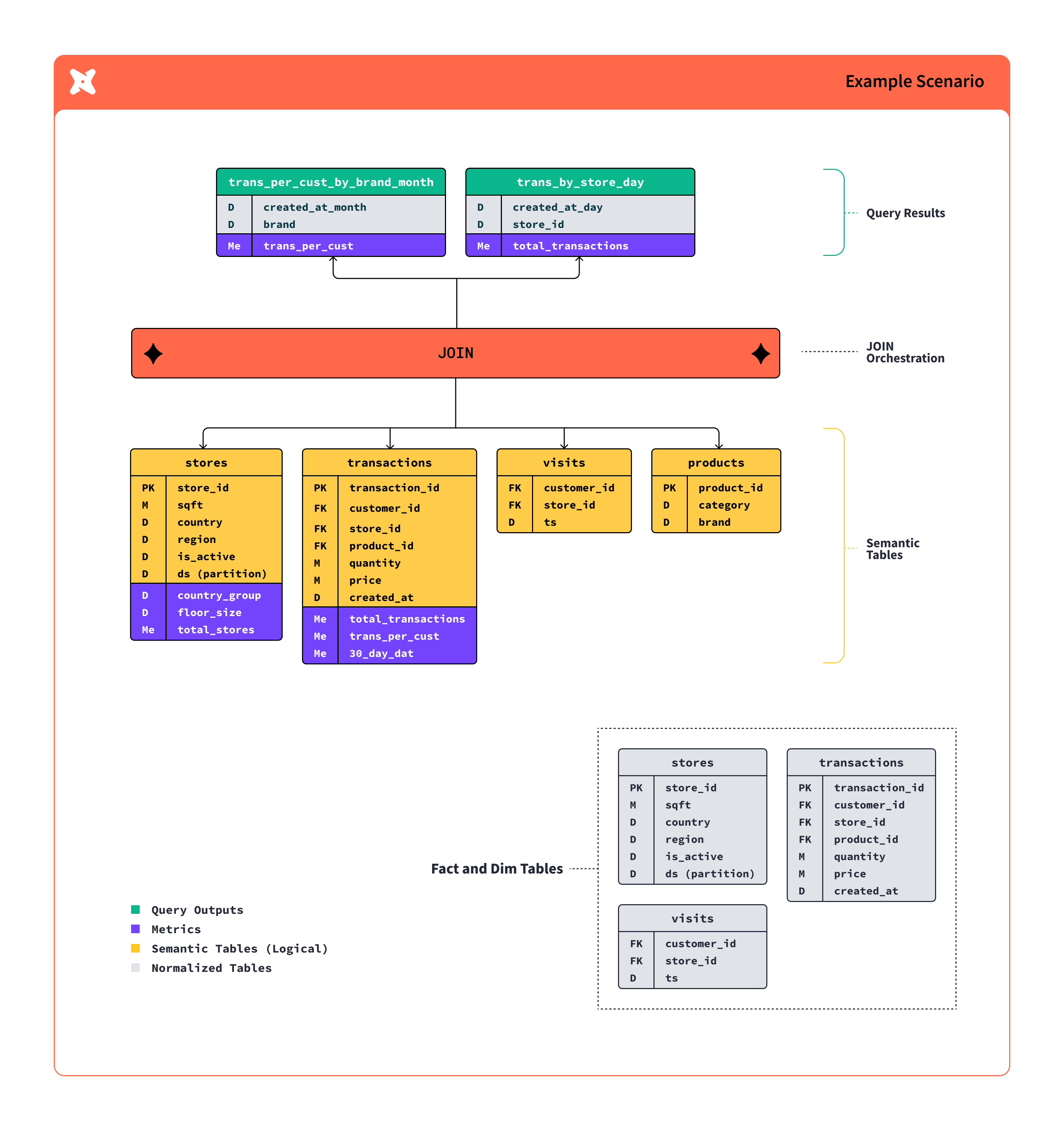
- Models
- 테이블들을 몇 개의 티어로 관리 -> 일종의 CTAS 및 Lineage 트래킹
- Table, view, CTE 의 형태로 존재.
- 입력, 중간, 최종 테이블을 정의하는 곳
- raw -> staging(src) -> core
1. 스테이징 모델
- 목적 : 원본 데이터를 가장 가까운 형태로 반영하며, 복잡한 변환을 최소화한다. 주로 데이터 타입 변경, 컬럼 이름 변경, 기본 계산 등 간단한 변환만 적용한다.
- 특징 : 일반적으로 뷰 형태로 물리화(materialize)되며, 다른 계층의 모델이 참조할 수 있도록 최신 데이터에 대한 접근을 제공한다.
2. 마트 모델
- 목적 : 최종적으로 비즈니스 정의 엔터티를 구성하여 최종 사용자가 대시보드나 앱을 통해 접근할 수 있도록 한다.
- 특징 : 성능이 중요하므로 주로 테이블 형태로 물리화되며, 필요에 따라 incremental model로 설정될 수 있다. 모델 설계시 너무 많은 조인을 피하고, 필요하다면 중간 계층에서 디자인을 재검토해야 한다.
3. View vs Table
- ✅ 스테이징 모델에서는 데이터를 신속하게 반영하고 최신 상태를 유지할 필요가 있기 때문에 주로 뷰로, 마트 모델에서는 데이터의 접근 속도를 빠르게 하고 시스템 부하를 최소하하는 것이 중요하므로 테이블로 한다.
- View
- 장점 : 저장 공간 절약(실제 데이터 저장 x), 데이터 일관성(기반 데이터가 변경될 때 뷰를 통해 조회하는 데이터도 실시간으로 갱신되어, 항상 최신 데이터를 유지)
- 단점 : 성능 저하(매번 쿼리를 실행, 대용량 데이터 처리시 성능 저하)
- Table
- 장점 : 성능 향상(데이터를 사전에 계산하여 저장하기에, 조회 시 빠른 응답 속도), 부하 감소(빈번한 쿼리 실행으로 인한 DB 부하 감소)
- 단점 : 저장 공간 사용, 데이터 갱신 지연(기반 데이터가 변경되어도 테이블은 자동으로 갱신x, 정기적인 갱신이 필요함)
dbt Models : Input
- 입력(raw)과 중간(staging,src) 데이터 정의
- raw는 CTE로 정의
- staging은 View로 정의
dbt Models : Output
- 최종(core) 데이터 정의
- core는 table로 정의
결론적으로 모든 models폴더 밑에 sql파일로 존재한다.
- 기본적으로 SELECT + Jinja 템플릿과 매트로
- 다른 테이블들을 사용 가능(reference) -> 이를 통해 linage파악
- Snapshots : 변경 가능한 테이블의 상태를 캡쳐하여 데이터 변경 이력 추적(주로 Fact Table)
- seeds : DataPlarform(snowflake)에 로드할 수 있는 초기 csv 데이터 적재
- Tests : 프로젝트 모델 테스트하는 SQL QUERY
- macros : 여러번 재사용할 수 있는 코드 블록
- docs : build할 수 있는 문서
- sources : data load tool, data warehouse에 로드된 데이터 이름 지정 및 설명
- exposures : 프로젝트의 다운스트림 사용을 정의 및 설명
- metrics : 프로젝트에 대한 메트릭 정의
- analysis : 프로젝트에서 분석 SQL QUERY를 구성하는 방법
구조화
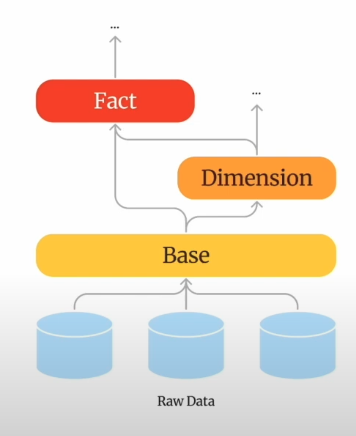
1. Raw(Source)
- 데이터 인프라가 Data Warehouse에 적재한 원천 데이터
2. Base Layer
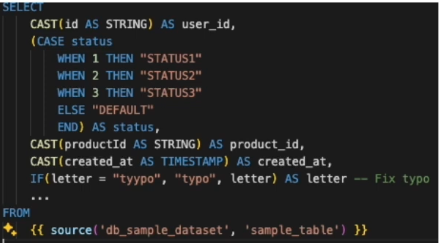
- staging layer에서 처리된 데이터를 기반으로 하여 추가적인 데이터 통합, 변환, 집계를 수행하는 선택적 레이어이다. 중간 결과물을 생성하여 데이터 마트 또는 분석 모델로의 데이터 흐름을 최적화하는 역할
- 스테이징 모델은 'stg'를 사용하여 파일 이름을 지정하고, 'base' 베이스 모델을 구분한다. 베이스 모델은 스테이징 폴더 내에 위치하고 이 모델들은 동일한 소스에서 나온 여러 스테이징 모델들이 혼자서는 큰 유용성을 발휘하지 못해 여러 스테이징 모델을 조합하여 하나의 베이스 모델로 만든다.(Base Layer는 프로젝트의 요구에 따라 구성될 수 있으며, 모든 DBT 프로젝트에 반드시 필요한 것은 아니다.)
- 원천 데이터를 한 번 가공한 기본 데이터(DBT의 staging이라고 볼 수 있음). 여기서 가공은 "필요한 컬럼들 SELECT, 문제 있는 데이터의 수정, 데이터 타입의 Casting(FLOAT -> INT, STRING -> INT)" 등을 의미
- 소스 데이터에 변경이 생기더라도 스테이징 레이어를 수정함으로써 다운스트림 모델로 변경사항이 자동으로 흘러가게 되어 수동 개입 없이도 일관성을 유지할 수 있다.
- Join이나 Aggregation과 같은 별도의 연산을 하지 않고 원천 데이터와 1:1로 최대한 매핑되는 구조
- 스테이징 레이어는 기본적이고 필수적인 역할, 베이스 레이어는 요구사항에 맞게 추가적인 단계라고 생각하면된다.
- 필요한 컬럼들은 Rename,Type Casting, 문제 있는 데이터의 수정 등을 해서 이후 모델링 과정(Dimension Layer, Fact Layer)에서 통일성과 효율성 챙기기
- userId > user_id, id 류는 string type 등
- 물리적 테이블이 아닌 view로 materialize
3. Dimension Layer
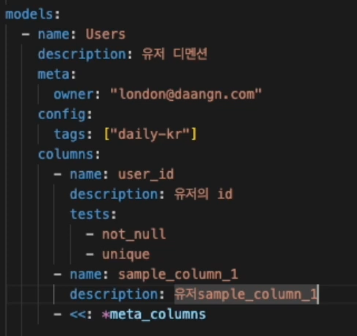
- User, Product와 같은 특정 개체의 속성값을 갖고 있는 계층
- JOIN, WHERE 등 복잡한 연산이 들어갈 수 있음
- 개체의 속성을 표현하기 때문에 많은 컬럼 + 개체의 수만큼의 row 수 => table로 materialize
- 'int_' 를 사용한 인터미디어트 모델은 마트 폴더 내에 위치한다. 데이터 마트 모델이 복잡하고 중첩된 구조로 되어 있어 읽기 어려운 경우, 일부 로직을 하나 이상의 인터미디어트 모델로 분리하여 가독성을 향상시킨다.
- 데이터의 최신화가 필요하기 때문에 주기적으로 계산되도록 구성했고, dbt tags로 최신화 주기를 자동 조정할 수 있도록 구성
- 자주, 전사적으로 사용되는 Dimension들에 대해서는 데이터 가치화팀에서 직접 관리하고, 각 로직이나 컬럼들에 대한 컨텍스트를 최대한 담음
4. Fact Layer
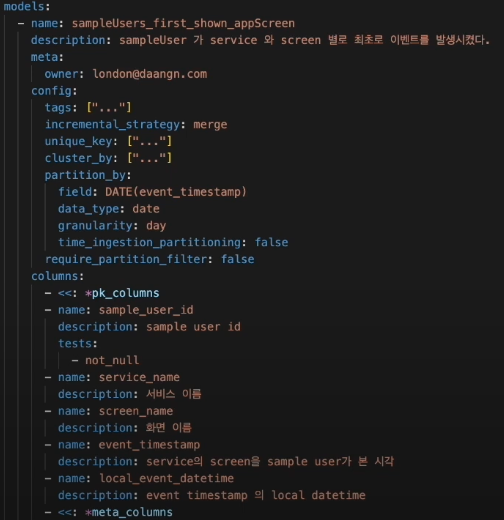
- "어떠한 X가 Y했다" 를 담고 있는 레이어이며, 사용자의 행동 데이터, 객체의 생성 및 변화 이벤트가 포함된다. 예를 들어, "유저가 피드를 보고 결제했다"와 같은 행동을 예시로 들 수 있다.
- Fact에도 복잡한 연산이 들어갈 수 있고 시간 흐름에 따라 데이터가 지속해서 추가 돼서 데이터 크기가 큼
- 데이터 크기가 크고, 시간 단위로 데이터를 나눌 수 있기 때문에 데이터 조회와 적재 효율성에서 이점을 얻기 위해 incremental로 materialize
- One big fact table로 만들어서 fact만 사용해도 충분할 수 있도록 필요한 컬럼들을 다 추가했음
- Dimension layer와 동일하게 dbt tags로 데이터 최신화 주기를 자동 조정할 수 있도록 구성
사용법
설치
1. DBT Cloud
✅ DBT를 편리하게 사용하기 위해서 웹 IDE를 제공해주는 서비스이다. DBT CLI를 통해 할 수 있는 모든 기능을 할 수가 있고 job 기능을 이용해서 ingestion 파이프 라인 구축이 가능하다.
2. DBT CLI
✅ 파이썬 패키지로 DBT설치. DBT에서 제공하는 모든 기능을 사용할 수 있지만, 실제 production 운영을 하기 위해선 수동으로 모든 세팅을 해주어야하는 단점이 있다. 무료이긴 하나 아주 복잡한 과정을 거치기에 중간에 포기함..
SQL
SELECT
seller_id AS user_id,
price,
created_at,
IF(code = 10, True, False) AS is_something,
...
TIMESTAMP('{{ var("target_date") }}') AS update_scheduled_at,
CURRENT_TIMESTAMP() AS last_updated_at
FROM {{ ref('db_sample_table') }} AS sample_table --reference
LEFT JOIN {{ ref('db_another_table') } AS another_table --reference
ON sample_table.id = another_table.category_id
WHERE {{ db_partition_filter_by('created_at') }} -- macro
AND type = 'Sample Type'
AND code IN (10, 20, 30, 55)
AND user_id IS NOT NULL;- ref로 sql내에서 다른 모델 의존할 수 있도록 구성
- 이때, 모델들이 서로 참조할 때 cyclic한 상황이 발생하지 않도록 방어 로직 작성
- 모델의 특성에 따라 자주 사용되는 함수,기능 들은 필요한 macros들을 만들어서 sql내에서 사용
macros
- 스냅샷을 자동으로 찍어줌. 빅쿼리의 쿼리가 날아갈 때 커스텀할 라벨을 달아줌
yaml
- yaml, sql에 config 정의만으로 저장 방식, 파티셔닝, 클러스터링 방식을 쉽게 정의 가능
- yaml에서 모델의 버전 지정 가능
- materialization, partitioning, clustering, versioning 등을 관리
참고 자료
https://velog.io/@juliy9812/dbt-%EA%B0%9C%EB%85%90
https://www.youtube.com/watch?v=m9lGtlxRJC4&ab_channel=%EB%8D%B0%EC%9D%B4%ED%84%B0%EC%95%BC%EB%86%80%EC%9E%90
https://www.getdbt.com/blog/modular-data-modeling-techniques
