[딥러닝/BERT] BERT(Bi-directional Encoder Representations from Transforms)에 대해 알아보기 2. Pre-training & Fine-tuning
사전 훈련(Pre-traininng)
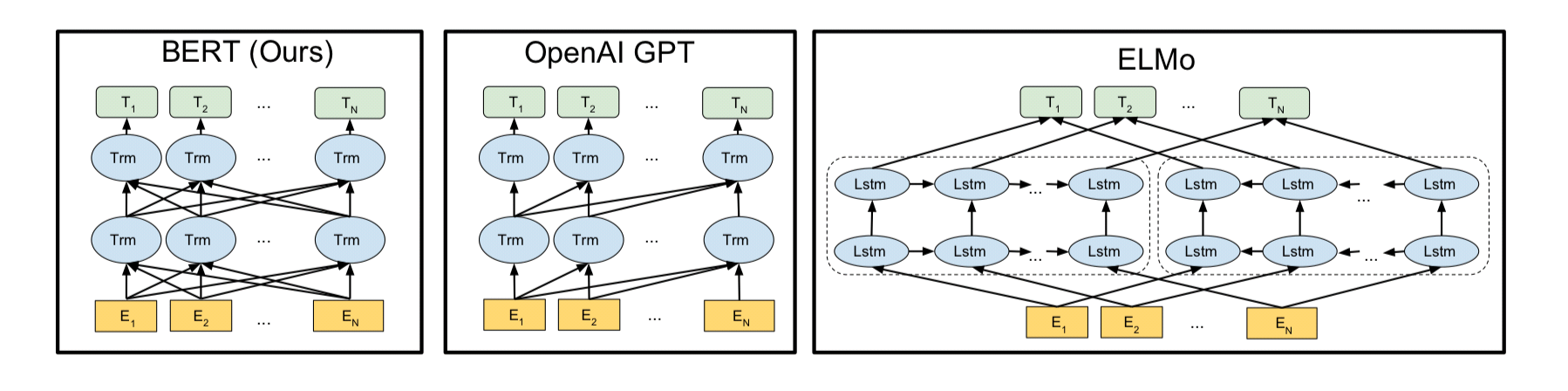
- BERT 는 MLM을 통해 양방향성 모델
- ELMo 는 정방향 LSTM과 역방향 LSTM을 각각 훈련시키는 방식으로 양방향으로 양방향 언어 모델
- GPT-1은 트랜스포머의 디코더를 이전 단어들로부터 다음 단어를 예측하는 방식으로 단방향 언어 모델
- 데이터들을 임베딩하여 훈련시킬 데이터를 모두 인코딩하면, 사전훈련 차례이다. 레이블이 없는 방대한 텍스트 데이터로 사전 훈련된다. ex)위키백과의 대규머 텍스트 코퍼스
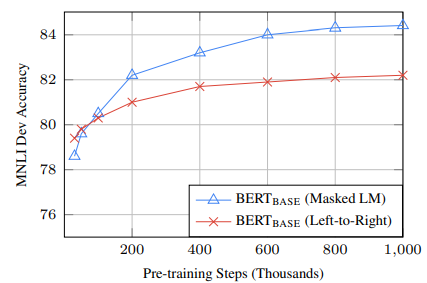
*기존의 방식(왼->오, 예측할 단어의 좌우 문맥을 고려하여 예측)과 달리 MLM이 더 좋은 성능
- Masked Laguage Model(MLM) : 문장에서 무작위로 단어를 마스킹하고, 마스킹된 단어를 예측하도록 함.
- 80% 단어 MASK 변경
The man went to the store -> The man went to the [MASK]- 10% 단어 Randon 변경
The man went to the store -> The man went to the dog- 10% 단어들은 동일
The man went to the store -> The man went to the store.
- 이유는 [MASK]만 사용할 경우에는 [MASK] 토큰이 파인 튜닝 단계에서는 나타나지 않으므로 사전 학습 단계와 파인 튜닝 단계에서의 불일치가 발생한다. 이 문제를 완화하기 위해 선택된 15% 단어들은 모든 토큰을 [MASK]로 사용하지 않는다.
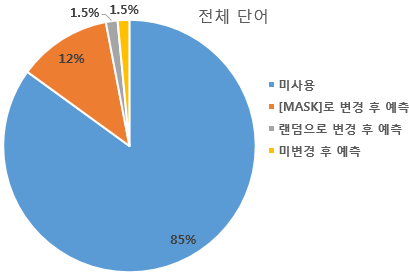
- 전체 단어의 85%는 마스크드 언어 모델의 학습에 사용되지 않는다. 마스크드 언어 모델의 학습에 사용되는 단어는 전체 단어의 15%
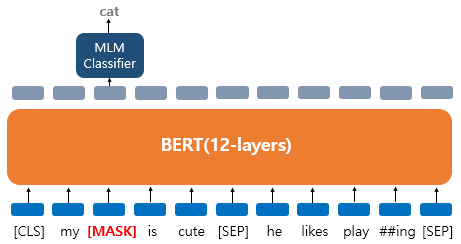
- 'My dog is cute. he likes playing' 문장에 대해서 BERT의 입력으로 사용되고 'dog' 토큰은 [MASK]로 변경되었다.
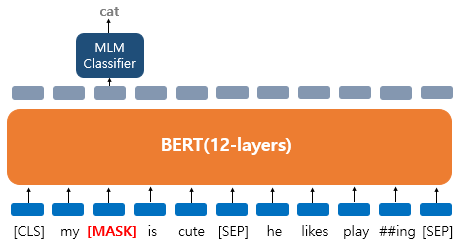
- 'dog' 토큰이 [MASK]로 변경되어서 BERT 모델이 원래 단어를 맞추려고 하는 모습을 보여준다. 출력층에 있는 다른 위치의 벡터들은 예측과 학습에 사용되지 않고, 오직 'dog' 위치의 출력층의 벡터만 예측과 학습에 사용된다.
- 구체적으로 BERT의 손실 함수에서 다른 위치에서의 예측은 무시한다. 출력층에서는 예측을 위해 단어 지합의 크기만큼의 밀집층(Dense layer)에 소프트맥스 함수가 사용된 1개의 층을 사용하여 원래의 단어가 무엇인지를 맞추게 된다.
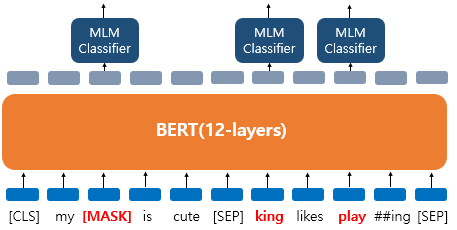
*'dog' -> [MASK], 'he' -> 'king', 'play'는 변경 x, 예측에 사용
- 랜덤 단어 'king', 변경되지 않은 단어 'play'에 대해서도 원래 단어가 무엇인지를 예측해야 한다.('play'도 변경 된건지 아닌건지 모르므로 단어 예측해야함)
- Next Sentence Prediction(NSP) : 두 문장이 주어졌을 때, 두 번째 문장이 첫번째 문장의 다음 문장인지를 맞추는 훈련. 두 문장 간 관련이 고려되야 하는 NLI와 QA의 파인 튜닝을 위해 두 문장의 연관을 맞추는 학습을 진행한다.
- 이어지는 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence - 이어지지 않는 경우
Sentence A : The man went to the store.
Sentence B : Dogs are cute.
Label = NotNextSentence
- 이어지는 경우
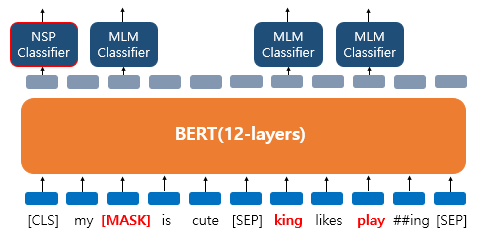
- 첫번째,두번째 문장 끝 [SEP] 그리고 두 문장이 실제 이어지는 문장인지 아닌지를 [CLS] 토큰의 위치의 출력층에서 이진 분류 문제를 풀도록 한다. [CLS] 토큰은 BERT가 분류 문제를 풀기 위해 추가된 특별 토큰이다. 그리고 마스크드 언어 모델과 다음 문장 예측은 따로 학습하는 것이 아닌 loss를 합하여 학습이 동시에 이루어 진다.
- 다음 문장 예측이라는 태스크를 학습하는 이유는 QA(Quenstion Answering), NLI(Natural Language Inference)와 같이 두 문장의 관계를 이해하는 것이 중요한 태스크가 있기 때문이다.
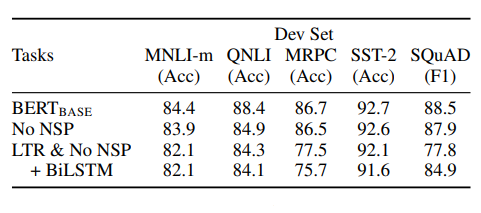
*No NSP는 MLM만 적용한 경우, LTR&No NSP는 MLM과 NSP를 둘다 적용하지 않은 기존의 좌우 모델을 사용한 경우 이다. BERT-Base(MLM+NSP)의 모델이 뛰어난 성능을 보여준다.
파인튜닝(Fine-tuning)
- 특정 작업 데이터 : 사전 훈련된 BERT 모델을 가져와, 특정 작업에 맞는 레이블이 있는 데이터셋으로 추가 훈련한다. ex) 감정 분석, 질문 답변, 텍스트 분류 등의 작업
- 파라미터 재조정 : 모델의 파라미터가 특정 작업에 맞게 조정. 사전 훈련에서 학습한 일반적인 언어 패턴을 바탕으로, 특정 작업에 필요한 더 세부적인 정보를 학습하는 것
- 훈련 과정
- 입력 데이터 준비 : 특정 작업에 맞는 입력 데이터 준비 ex) 텍스트 분류 작업에서는 텍스트와 그에 해당하는 레이블(긍/부정)을 준비
- 모델 훈련 : 준비된 데이터로 모델을 훈련. 이 과정에서 파라미터가 업데이트 된다.
전이학습(Transfer Learning)
학습된 언어 모델을 전이학습시켜 실제 NLP Task를 수행하는 과정(실질적인 성능이 관촬된는 부분)
개체명 인식(Named Entity Recognition, NER)이나 QA문제는 알고리즘이나 언어모델을 만들어야 했다. 기존의 언어모델(스스로 라벨링)은 준지도 학습, 전이 학습(라벨이 주어지는)은 지도 학습이다. 전이 학습은 BERT 언어모델에 NLP Task를 위한 추가적인 모델을 쌓는 부분이다.
