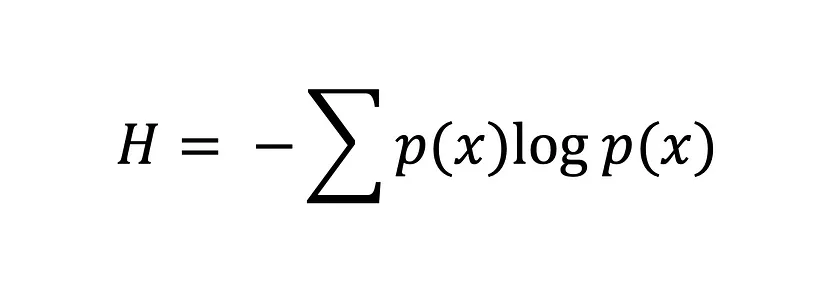
크로스 엔트로피(Cross-entropy)
-
예측된 확률 분포와 실제 분포 간의 차이를 측정하기 위한 손실함수 역할.
-
두 가지 확률 분포가 얼마나 비슷한지를 수리적으로 나타내는 개념. 두 확률 분포 간의 차이를 정량화하여 수적 척도로 타나낸다.
-
손실 함수의 일종으로 예측과 실제 목표값 간의 차이 측면에서 모델이 얼마나 잘 수행되는지를 측정 가능하다.
-
학습에서의 목표는 엔트로피 손실을 최소화 하는 것이다. 우리는 경사하강법과 같은 최적화 알고리즘을 통해 모델의 가중치(weight)와 편향(bias) 를 조정하여 달성한다.

-
p(x) 는 실제 레이블(정답 레이블)이고, 이는 원-핫 인코딩 된 벡터로 주어진다. q(x)는 모델이 예측한 각 클래스의 확률이다. softmax 함수를 통해 계산된다.
-
위의 수식에서 보는 것처럼 확률분포 q(x)의 확률분포 q(x)에 가깝게 접근 시키는 것이 학습 원리이다. 이 교차 엔트로피가 낮아지는 쪽으로 모델의 추정 확률분포 q(x)를 꾸준히 개선해야 한다.
-
Transformer 디코더는 주로 seq2seq 문제, 기계 번역에서 사용된다. 디코더의 출력은 단어(또는 토큰)의 시퀀스이며, 각 단어는 소프트맥스 함수로 확률 분포를 가지게 된다. 크로스 엔트로피 손실 함수는 이 확률 분포와 실제 정답 시퀀스 간의 차이를 측정한다.
예시코드
import torch
import torch.nn as nn
import torch.nn.functional as F
# 디코더의 출력 예시: [batch_size, seq_len, vocab_size]
decoder_output = torch.randn(32, 10, 1000) # (batch_size, seq_len, vocab_size)
# 실제 정답 레이블 예시: [batch_size, seq_len]
# 여기서 각 값은 정답 단어의 인덱스입니다.
target = torch.randint(0, 1000, (32, 10)) # (batch_size, seq_len)
# 소프트맥스 함수를 사용하여 각 위치에서의 확률 분포 계산
# PyTorch의 CrossEntropyLoss는 소프트맥스 함수를 내부적으로 포함하고 있으므로, 별도로 소프트맥스를 적용할 필요는 없습니다.
loss_fn = nn.CrossEntropyLoss()
# CrossEntropyLoss는 입력의 차원과 타겟의 차원이 달라야 하므로, 디코더 출력을 [batch_size * seq_len, vocab_size]로 변환
# 그리고 타겟은 [batch_size * seq_len]으로 변환
decoder_output = decoder_output.view(-1, decoder_output.size(-1))
target = target.view(-1)
# 크로스 엔트로피 손실 계산
loss = loss_fn(decoder_output, target)
print(f"Loss: {loss.item()}")
- 여기서 중요한 것은 nn.CrossEntropyLoss() 는 입력과 타켓의 차원이 다를 때 잘 동작한다. 입력은 모델의 로짓(logits)으로 [batch_size * seq_len, vocab_size] 크기를 갖고, 타켓은 [batch_size * seq_len] 크기를 갖는다. 그리고 내부적으로 소프트맥스 함수를 포함하고 있으므로, 별도로 소프트맥스를 적용할 필요가 없다. 예를들어, 입력 텐서는 [32, 10, 1000], 타겟 텐서는 [32, 10] 이다.
디코더에서 크로스 엔트로피 손실 함수 적용
- 디코더의 마지막 선형 레이어 출력(로짓) : 소프트맥스 함수를 적용하기 전의 값으로, 차원은 [batch_size, seq_len, vocab_size] 이다.
- 소프트맥스 함수 적용 후: 로짓을 소프트맥스 함수를 통해 확률 분포로 변환하며, 차원은 여전히 [batch_size, seq_len, vocab_size]이다.
- 크로스 엔트로피 손실 함수 : PyTorch의 nn.CrossEntropyLoss는 로짓을 입력으로 받아 내부적으로 소프트 맥스 함수를 적용한 후 손실을 계산한다.
- 모델의 로짓(logits)이란, 신경망의 마지막 레이어에서 활성화 함수(softmax, sigmoid)를 적용하기 전의 선형 변환 출력이다. 로짓은 클래스에 대한 비활성화된 점수라고 할 수 있으며, 이 점수들을 소프트 맥수 함수를 통해 확률로 변환할 수 있다. 보통 실수 값의 벡터로 표현된다. 디코더는 [batch_size, seq_len, vocab_size] 차원의 텐서를 출력한다. 각 시퀀스의 각 위치마다, 디코더는 vocab_size만큼의 로짓을 생성한다. 여기서 vocab_size 는 모델이 예측할 수 있는 전체 단어(또는 토큰)의 개수이다. 예를들어, vocab_size가 10,000이라면, 디코더는 각 시퀀스의 위치마다 10,000개의 로짓 값을 출력한다. 수 많은 예측 단어의 갯수를 열(low)값에 나열한다.
여기서 실제 정답 시퀀스는 원-핫 인코딩된 벡터로 표현되고, 각 위치에서 정답 단어만 1이고 나머지는 0이다. 이후 모델이 예측한 확률 분포(소프트맥스 적용된 로짓)와 실제 정답 레이블(원-핫 인코딩 된 벡터)을 비교하여 크로스 엔트로피 손실을 계산한다. 이 손실 값을 최소화 하도록 모델을 학습시키는게 목표이다. 이후 최종 출력은 각 시퀀스 위치마다 모든 가능한 단어에 대한 확률 분포(by 소프트맥스)이다.
One-Hot encoding vector 와 모델의 예측 확률 분포의 생성위치는 어디이며, 또 어디서 어떻게 계산될까? 원-핫 인코딩 벡터는 데이터 준비 과정에서 생성된다. 각 단어의 인덱스를 어휘 크기만큼의 벡터로 변환하는 과정이다. 예측 확률 분포는 디코더의 마지막 레이어에서 로짓을 출력한다. 이 로짓은 소프트맥스 함수에 의해 확률 분포로 변환된다. 그리고 나서 두 값을 비교하여 엔트로피 손실 함수 계산에 사용된다.
logits = torch.randn(32, 10, 1000)
probabilities = F.softmax(logits, dim=-1)
print(probabilities.shape) # torch.Size([32, 10, 1000])
print(probabilities[0][0]) # 첫 번째 시퀀스의 첫 번째 단어에 대한 확률 분포왜 마지막 차원에만 함수를 적용할까? dim=-1 은 소프트맥스 함수가 적용될 차원을 지정한다. 여기선 vocab_size = 1000 에 적용한다는 소리이다. 시퀀스 위치마다 1000개의 로짓 값이 존재한다. probabilities의 차원은 [32,10,1000]이며, 각 마지막 차원(1000개의 값)은 0에서 1사이의 값으로 변환되고, 합이 1이 된다. vocab_size에만 함수가 적용되는 이유는 각 단어에 대한 확률 분포를 생성하기 위해서이다. 각 시퀀스 위치에서 다음 단어로 어떤 단어가 올 확률이 가장 높은지를 예측할 수 있다. batch_size와 seq_len은 확률로 나타나지 않음.
결론
- 크로스 엔트로피 손실 함수는 모델의 예측 확률 분포와 실제 정답 레이블 간의 차이를 측정하여 손실 값을 계산한다. 디코더 출력의 시퀀스 위치마다 단어의 확률 분포를 예측하고, 이를 실제 정답 시퀀스와 비교하여 손실을 계산한다.
- 데이터 준비 단계에서 생성된 원-핫 인코딩 벡터와 소프트맥스 함수로부터 나온 확률분포(로짓)을 비교하여 크로스 엔트로피 손실 값을 계산한다.
