먼저 이 글의 경우 제가 주로 사용할 데이터만을 타겟으로 WER을 측정해 대략적인 성능을 알아 본것이기에 절대적인 성능 비교가 아님을 알립니다.
해당 비교를 하게 된 이유는 50분짜리 토론회의 스크립트를 구성해야하는 일이 있어 시작하게 되었습니다.
유튜브 자막(CC) 스크립트를 복사하는 방법으로 스크립트를 만들었지만 해당 유튜브 자막이 한국어에 대해선 조금 부정확하여 좀 더 한국어에 특화된 STT 모델은 사용하면 유튜브 뉴스나, 토론회 등을 쉽게 글로 보고 요약까지 해볼 수 있지 않을까? 하는 아이디어에서 비교가 시작되었습니다.
유튜브에서 제공하는 자동 자막(Closed Captions, CC) 기능은 Google의 자체 개발한 음성 인식 모델을 기반으로 합니다. Google은 세계 최고의 기술 기업 중 하나로, 다양한 AI 기술과 자연어 처리(NLP) 및 음성 인식(STT) 분야에서 최첨단 모델을 개발하고 있습니다.
Google 에서 자체 개발한 음성 인식 모델이라고 하는데 한국어에 대한 WER(Word Error Rate)을 공식 발표하지 않아 어느 정도인지 알기 어려웠습니다.
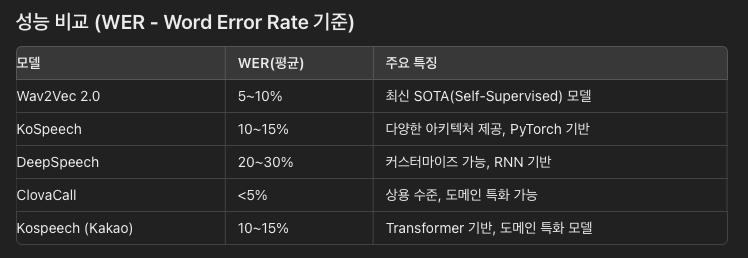
위 표는 현재 발표된 5개의 모델에서 발표한 한국어 기준 WER 평균값입니다.
해당 표 역시 각자 자신의 기준을 통해서 WER 평균을 발표한 것이기 떄문에 절대적인 신뢰를 가진다고 보긴 어렵습니다.
그래서 한번 제가 사용할 노이즈와 무의미한 필러등이 많은 토론회 음성 자료를 가지고 비교를 해보았습니다.
Ground_truth (원본의 데이터를 직접 여러번 듣고 작성한 스크립트입니다.) 와 비교군을 가지고 WER 측정을 통해 비교하였습니다.
발음이 뭉개지는 경우도 있어 사실상 Ground_Truth가 100% 신뢰할 수도 없는 상태로 기본적으로 WER 이 매우 높게 나올 것으로 생각했습니다.
또한 여러개의 데이터를 통해 평균을 낸 값이 아닌 특정 부분만을 캐치한 1개의 자료를 사용하였습니다.
사용한 자료
데이터에 사용된 youtube 토론회 자료입니다.
저는 youtube에서 흔히 보이는 비디오를 활용할 수 있는 STT Model을 찾고 있었기 때문에 노이즈(사운드겹침)와 의성어(아삭아삭 등), 의태어(뺑뺑 등), 무의미한 필러(그, 어, 음 등) 등이 많이 사용되는 토론회를 타겟으로 진행해보았습니다.
다음은 토론회의 중간 데이터를 무작위로 뽑아 3분간의 대화 내용을 발췌한 내용으로 해당 자료를 Ground_truth 기준을 잡고 WER을 측정해보았습니다.
에서는 그 공장 정비 시기를 조정해서 또 공업 용수를 절감했고 참 어렵게 했던 그 제한 급수가 실시됐던 그 완도의 다섯개의 도서지역의 경우는 정말 좀 최소한으로라도 병급수를 지원하고 그 이후에 지하 저류지 설치 해수 담수화하는 선박을 투입해서 진짜 가뭄 극복을 위해서 최 최선을 다했습니다. 여기서 하나 좀 중요한게 국가와 지자체가 그때 협의해서 농업용수하고 발전용수까지도 용수로 대체를 해서 네 아마 전국적인 모법 사례로 지금 남겨졌는데요. 이 만약에 주암댐의 물이 공급이 중단될 경우 지금 영산강 섬진강 유역 주민 한 백육십칠만명이 식수를 공급받지 못합니다. 그리고 여수 국가산단의 산업 활동이 심각한 영향을 받게 됩니다. 아 그 산업단지 공단의 통계의 의하면 약 백조 연간 여수 산단에서 백조의 그 생산이 발생하는데 하루만해도 삼천억 정도가 지금 차질이 빚어지는데요 이렇게 극심한 이런 가뭄이나 홍수를 대응하기 위해서는 그 수자원 정책이 시급하게 요구되고있는 실정입니다. 그래서 이제 그 기후 대응댐 건설 계획은 수자원 확보의 마지막 대안이라고 저희는 지금 보고 있습니다. 음 그 박종필 국장님은 필요성에 대해서 이렇게 이야기 해주셨는데 우리 교수님이 그 전문가의 입장에서 보셨을때는 세곳의 필요성에 대해 동의가 되시나요 어떻습니까. 그 홍수조절댐 두곳은 용량이 제가 정확한지 그것은 확인은 못했지만 필요합니다. 그 병영청댐하고 옥천댐하고 필요하고 한 저기 그 국장님이 말씀하신것처럼 저기 그 용수공금 동복천댐도 주암댐이 그 바닥이 나면은 그 물이 그 필요하니까 그 물을 공급해서라도 활용하겠다 그런 부분에서 필요성은 있는데 그 필요를 위해서 그니까 그거는 위기상황에서 보험을 들고자햐는 그런 인데 그것 때문에 먼저 그 지역의 주민이라던지 또는 그 아무래도 댐을 막으면 기존의 거기 수몰지역이 있지만 수몰지역이 더 넓어지니까 피해보는 사람들에 대해서 어떻게 배려를 하고 할 것인지 하는것에 대해서 하는 것과 그리고 정작 화순군에서는 그다지 큰 혜택이 없고 수혜를 받는 곳은 여수산단이라던지 광주광역시라던지 이런덴데 그사람들이 그러면 이쪽의 피해주민들한테 뭘 해줄수 있느냐 하는 그런 인구에 대한 얘기하고 또하는 자연에 대한 얘기하고 그런 부분을 그니까 물이 부족하면 아껴쓰면서 견뎌야하는것인지 개발을 해서 수요를 충족해줘야할것인지 그런
다음으로 비교군은 총 3가지입니다.
- Google (youtube CC 자동 자막을 기준으로 가져왔습니다.)
- Naver Clova (Naver Cloud Platform에서 제공하는 Clova Speach 의 Nest 엔진 테스트 버전을 사용해 보았습니다)
- 오픈소스로 제공되는 Wav2Vec2의 한국어 Fine-Tuning 을 거친 자료를 사용하였습니다.(kresnik/wav2vec2-large-xlsr-korean)
Wav2Vec2
비교군 3가지 중 youtube 자막과 naver clova의 경우 쉽게 자료를 복사하여 볼 수 있었습니다.
나머지 한가지 오픈소스로 구성한 모델인 wav2vec2 모델만 테스트 해보았습니다.
from transformers import Wav2Vec2Processor, AutoModelForCTC
import torch
import librosa
import jiwer
import nlptutti as metrics
processor = Wav2Vec2Processor.from_pretrained("kresnik/wav2vec2-large-xlsr-korean")
model = AutoModelForCTC.from_pretrained("kresnik/wav2vec2-large-xlsr-korean")
# 오디오 파일 로드 및 리샘플링
def load_audio(audio_path):
speech_array, sampling_rate = librosa.load(audio_path, sr=16000) # 16kHz로 리샘플링
return torch.tensor(speech_array), 16000
# 음성을 텍스트로 변환
def speech_to_text(audio_path):
speech, sampling_rate = load_audio(audio_path)
# 음성을 모델이 이해할 수 있는 형식으로 전처리
input_values = processor(speech, sampling_rate=sampling_rate, return_tensors="pt").input_values
# 모델을 통해 음성 데이터 예측 (로그 확률)
with torch.no_grad():
logits = model(input_values).logits
# 가장 높은 확률의 ID를 사용해 텍스트로 디코딩
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)[0]
return transcription
# 사용 예제
with open("file6.txt", "r") as file:
# 모든 줄을 리스트로 읽습니다.
ground_truth = file.readlines()
with open("clova.txt", 'r') as file:
clova = file.readlines()
with open("google.txt", 'r') as file:
google = file.readlines()
ground_truth = "".join(ground_truth)
clova = " ".join(clova)
google = " ".join(google)
audio_path = "part_6.mp3" # 예시 파일 경로
transcription = speech_to_text(audio_path)
# WER 계산
wer = jiwer.wer(ground_truth, transcription)
wer2 = jiwer.wer(ground_truth, clova)
wer3 = jiwer.wer(ground_truth, google)
print(f"Word Error Rate (WER): {wer:.2f}")
print(f"Word Error Rate (WER): {wer2:.2f}")
print(f"Word Error Rate (WER): {wer3:.2f}")
nwer = metrics.get_wer(ground_truth, transcription, rm_punctuation=True)
nwer2 = metrics.get_wer(ground_truth, clova, rm_punctuation=True)
nwer3 = metrics.get_wer(ground_truth, google, rm_punctuation=True)
print(f"N Word Error Rate (WER): {nwer['wer']:.2f}")
print(f"N Word Error Rate (WER): {nwer2['wer']:.2f}")
print(f"N Word Error Rate (WER): {nwer3['wer']:.2f}")Wav2Vec 2.0 모델이 16kHz의 샘플링 레이트로 학습되었기 때문에, 입력되는 오디오 데이터도 동일한 샘플링 레이트로 제공되어야 합니다.
오디오 파일을 16kHz로 리샘플링한 후, 모델에 입력해보겠습니다. 이를 위해 librosa 라이브러리를 사용하였습니다.
이후 WER 분석을 위해 두 가지 라이브러리를 통해 비교하였습니다.
- jiwer : 기본적인 WER 식
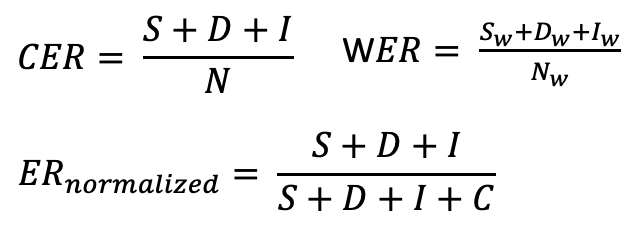
- nlptutti : 띄어쓰기와 구두점 전처리후 WER 식 적용
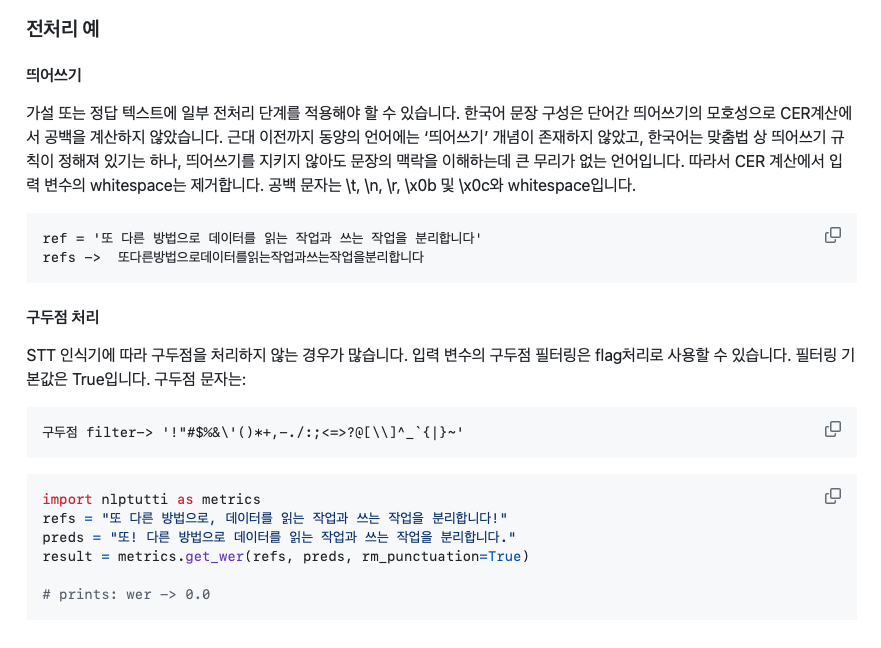
기본적인 WER 식만으로 비교할 경우 의성어, 의태어, 필러등 불필요한 데이터가 많은 유튜브 토론회 영상에서 정확한 비교가 어려울 것으로 판단하여 자동으로 구두점, 띄어쓰기 처리를 해서 WER을 제공하는 라이브러리가 있어 추가로 비교해보았습니다.
결과
마지막으로 결과입니다.
# 결과값
Word Error Rate (WER): 0.84 # Wav2Vec2
Word Error Rate (WER): 0.43 # Naver Clova
Word Error Rate (WER): 0.54 # Google Youtube CC
N-Word Error Rate (WER): 0.81 # Wav2Vec2
N-Word Error Rate (WER): 0.38 # Naver Clova
N-Word Error Rate (WER): 0.42 # Google Youtube CC음성도 겹치고, 수많은 필러가 있었지만 네이버 클로버의 경우 상당히 준수한 성능을 보여주었습니다.
초기에 확인 했던 WER 수치와 비교해 볼때 Wav2Vec 2.0 이 많이 떨어지는 성능을 보였기에 해당 모델을 한국어 유튜브 음성 분석에 사용하는 것은 어려울 것 같습니다.
또한 Google Youtube CC 자막의 경우도 Clova와 비슷한 성능을 보였습니다. 영어에 특화되어 있어 한국어 처리는 잘 못할 것으로 생각했는데 상당히 준수한 성능을 보여주었습니다.
마무리
크라우드스트라이크(CrowdStrike) 사의 보안 문제로 MS Azure 클라우드를 서버를 사용한 PC 들이 먹통이 된 사건을 계기로 많은 국내 클라우드 서비스가 주목을 받고있지만 이전부터 Naver Cloud Platform에서 Naver clova, objectStorage, server 등 다양한 서비스를 사용해본 유저로서 또 한번 네이버의 위대함을 느끼게 되는 계기가 아닌가 싶습니다..
Naver Clova Speech 오픈소스로 풀어줄순 없겠죠..?
네이버 클로바는 상업용 API 서비스로 네이버 클라우드를 통해 API 형태로 제공됩니다.
20분간 무료로 테스트 해볼 수 있으며 이후 비용은 옵션과 시간에 따라 다르게 측정되지만
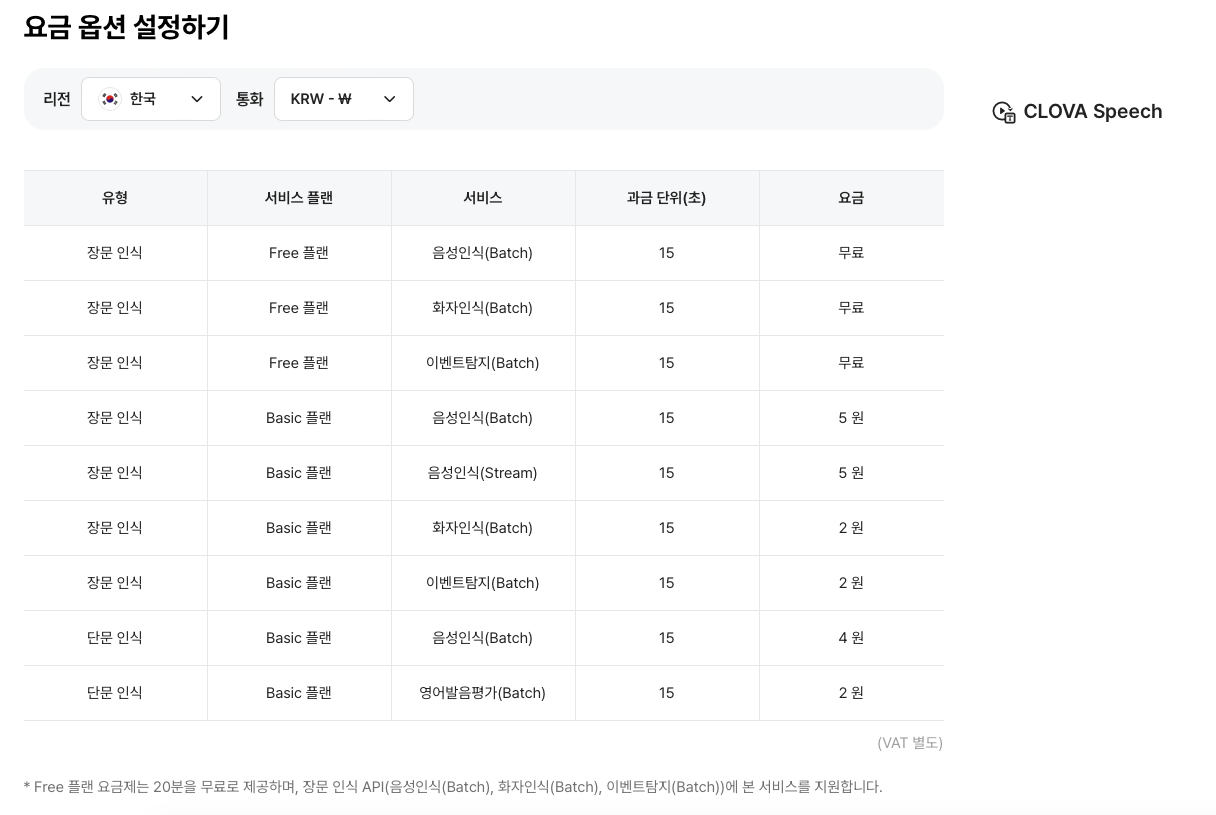
대략 1시간당 1000~2000원 사이의 요금이 발생합니다.
비용이 조금 있어 서비스로 제공은 어렵겠지만, 제가 가끔씩 뉴스나 토론회등의 영상을 요약할 필요가 있을 때 사용하면 괜찮을 것 같습니다.
또한 유튜브 자막의 성능이 뛰어나 기존처럼 무료로 유튜브 자막을 스크래치하여 사용하는 것이 괜찮은 방안이라고 생각했습니다.

안녕하세요, 네이버 클라우드 플랫폼입니다.
네이버클라우드의 기술 콘텐츠 리워드 프로그램 ‘이달의 Nclouder(8월)’ 도전자로 초대합니다 🙂
네이버 클라우드 플랫폼 서비스와 관련된 모든 주제로 9/2(월) 23시까지 신청 가능합니다. (*8월 작성 콘텐츠 한정 신청 가능)
Ncloud 크레딧을 포함한 다양한 리워드가 준비되어 있으니 많은 관심 부탁드립니다!
자세한 내용은 아래 링크에서 확인부탁드립니다.
https://blog.naver.com/n_cloudplatform/223539614636
신청 링크
https://navercloud.typeform.com/to/lF8NUaCF