
이전글에서 Redis의 자료구조와 함께 캐시로써의 Redis에 대해 알아보았다. 이번 글에서는 Redis를 캐시로써 어떻게 사용하는지에 대해 알아보자!
캐시란

사용자의 요청으로 데이터를 DB에서 불러오는데, DB의 속도가 느리다면? 데이터를 미리 속도가 빠른곳에 저장해두고 사용하면 응답을 빠르게 할수 있지않을까?
캐시의 개념은 데이터의 원본보다 더 빠르고 효율적으로 엑세스할 수 있는 임시 데이터 저장소를 의미한다!
Redis는 In-Memory DB인만큼 빠른 속도(약100ns)를 보이기때문에 캐시로 사용하기 적합하다!
그렇다면 어느상황에서 캐시를 사용하면 유리할까?
- 데이터 검색까지 시간이 오래걸리거나, 매번 계산이 필요한 값인 경우 계산된값을 미리 캐시하면 유리하다
- 캐시에서 데이터를 가져오는 것이 원본 데이터 저장소 데이터를 요청하는 것보다 빨라야한다.
- 잘 변하지 않는 데이터이어야한다.
- 자주 요청되는 데이터여야한다.
Redis를 캐시로 사용하면 좋은 점
Redis는 고성능의 In-Memory 데이터베이스로, 캐시 시스템으로 활용하기에 많은 장점을 제공합니다. 주요 이점은 다음과 같습니다:
1. 빠른 속도
Redis는 메모리를 기반으로 작동하기 때문에 데이터 접근 속도가 매우 빠릅니다. 이는 높은 응답 속도를 요구하는 시스템에서 큰 강점이 됩니다.
2. 다양한 자료구조 지원
Redis는 문자열, 해시, 리스트, 집합, 정렬된 집합 등 다양한 자료구조를 지원합니다. 이를 통해 다양한 상황에서 데이터를 효율적으로 캐싱할 수 있으며, 개발 난이도를 낮출 수 있습니다.
3. 고가용성 기능 제공
캐시의 접근이 불가능해지면 서비스 장애로 이어질 수 있기 때문에 캐시 저장소의 안정성은 매우 중요합니다. Redis는 고가용성을 지원하는 여러 기능을 제공합니다:
- Sentinel: 마스터 노드의 장애를 감지하고 자동으로 페일오버를 수행하여 서비스의 연속성을 보장합니다.
- Cluster: 데이터를 분산하여 저장하고, 노드 간 데이터를 공유해 스케일 아웃을 손쉽게 구현할 수 있습니다.
캐시전략
그렇다면 효율적으로 캐시를 운영하기 위해 어떤 구조로 사용하면 좋을까요? Redis를 어떻게 배치하는지에 따라
읽기 전략
Look aside(==Lazy Loading)
Look Aside전략은 가장 대표적인 캐시전략으로 DB를 살피기전 캐시서버를 먼저 조회하는 구조이다.
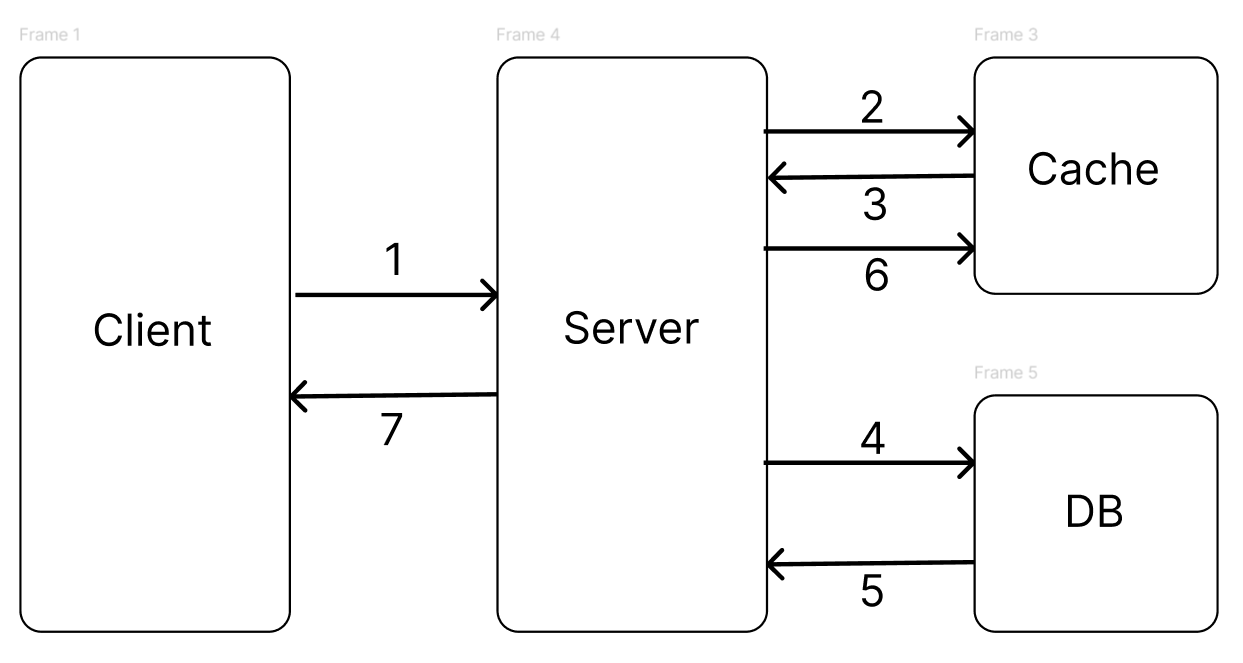
- 클라이언트 요청
- 캐시(Redis)에 원하는 데이터가 존재확인 (Cache hit)
2-1. 캐시(Redis)에 데이터 존재시 반환- 캐시(Redis)에 데이터 존재X (Cache miss)
- DB에서 데이터확인
- DB에서 데이터 반환
- DB에서 조회한 데이터를 캐시에 업데이트
- 클라이언트에게 데이터 반환
장점
- 레디스->DB로 이어지는 구조인만큼, 레디스에 문제가 생겨 접근할수 없는 상황이 발생하더라도 DB에서 데이터를 가져올수 있어, 장애를 예방할수 있다는 장점이 있다!
단점
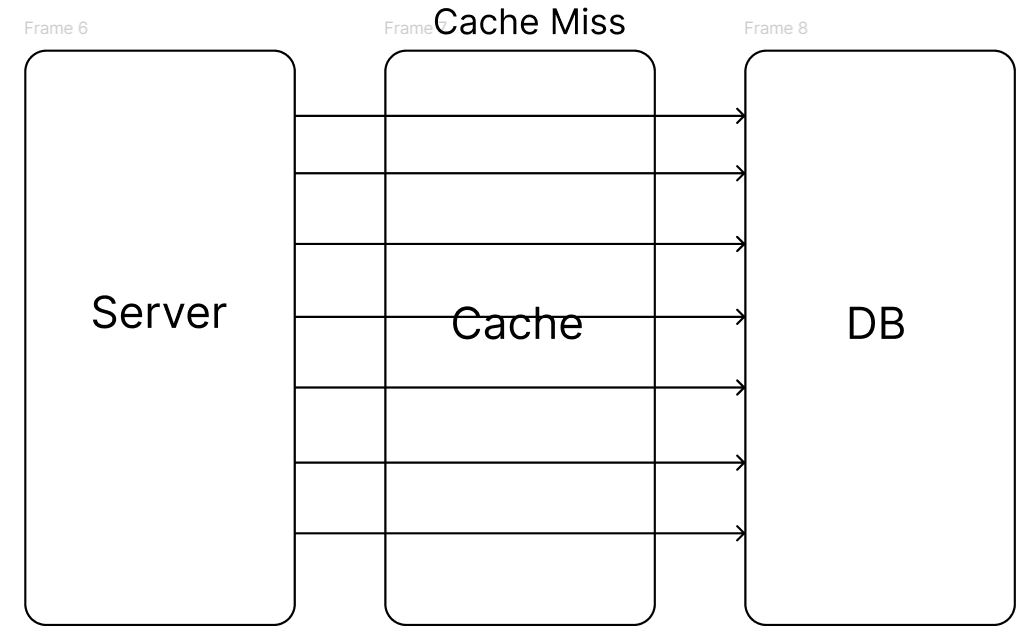
- 하지만, 기존 레디스를 통한 데이터 조회가 많았을경우, 모든 커넥션이 DB로 몰려 갑작스러운 부하로 인해 문제가 생길수 있다. 참고. Thunder Herd
어느 상황에 적용하면 좋을까??
캐시를 적용한 초기상황에서는 무조건적인 DB호출이 필요하니, 같은 데이터를 반복 조회하는 쿼리가 많은 서비스에 적합할것같다.
반복조회를 해야하는 서비스에 캐시를 적용하면 안될까??
- 서비스 중간에 캐시를 적용하거나, 새로운 상품을 등록한 경우 캐시 미스로 인해 문제가 발생할수 있다. 이런경우, 캐싱 워밍과정을 통해 미리 캐시에 데이터를 쌓아두는 방식으로 해결할수 있다!
쓰기 전략
캐시는 필요한 데이터를 미리 복사해사용하는 것인만큼 실제 DB와의 정합성이 중요하다. 데이터간의 정합성이 맞지 않은경우를 캐시 불일치라 하는데, 이를 해결할기 위한 전략으로 Write Through, cache Invalidation, write behind가 있다.
Write Through
Write Through방식은 저장할 데이터를 캐시에 먼저 저장하고, DB에 저장하는 방식이다.
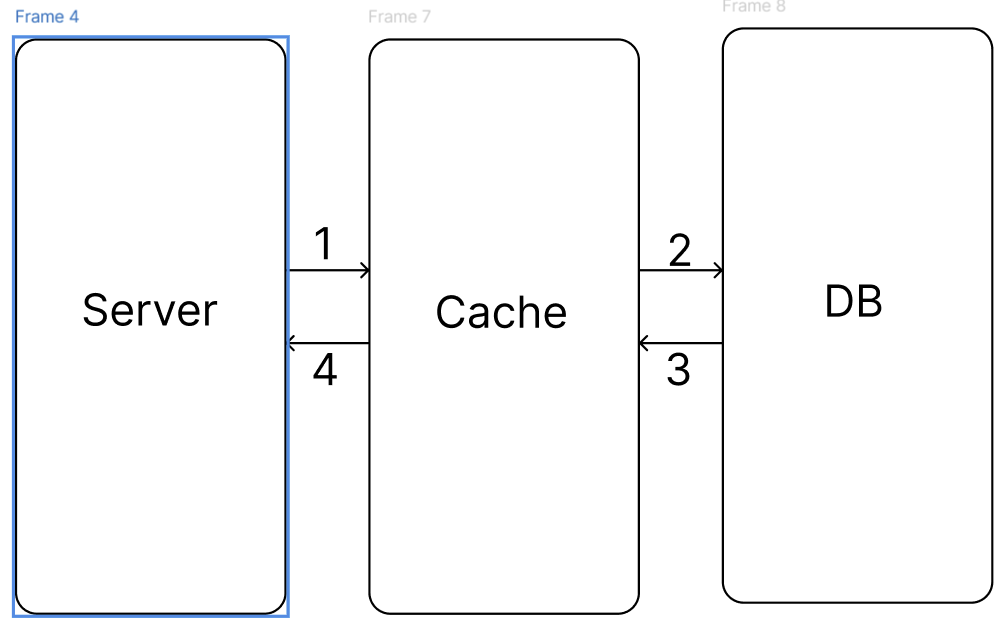
- 캐시에 쓰기
- DB에 쓰기
장점
- 캐시와 DB가 항상 최신데이터를 가지고 있을수 있다는 장점이 있다.
단점
- 2개의 DB에 저장해야하므로, 데이터를 저장할때마다 시간이 많이 소요될수 있다.
- 자주 사용되지 않는 데이터도 무조건 캐시에 저장되므로, 불필요한 자원낭비가 발생할수 있다.
TTL설정을 통해 자주 사용되지 않는 데이터를 자동으로 삭제시켜 자원을 확보할수 있다.
Cache Invalidation
DB에 값을 업데이트 할때마다 캐시에서는 데이터를 삭제하는 전략이다. 특정 데이터를 삭제하는 것이 새로운 데이터를 저장하는것보다 리소스가 적기때문에 write through의 단점을 보완한 방법이라 볼수 있다.
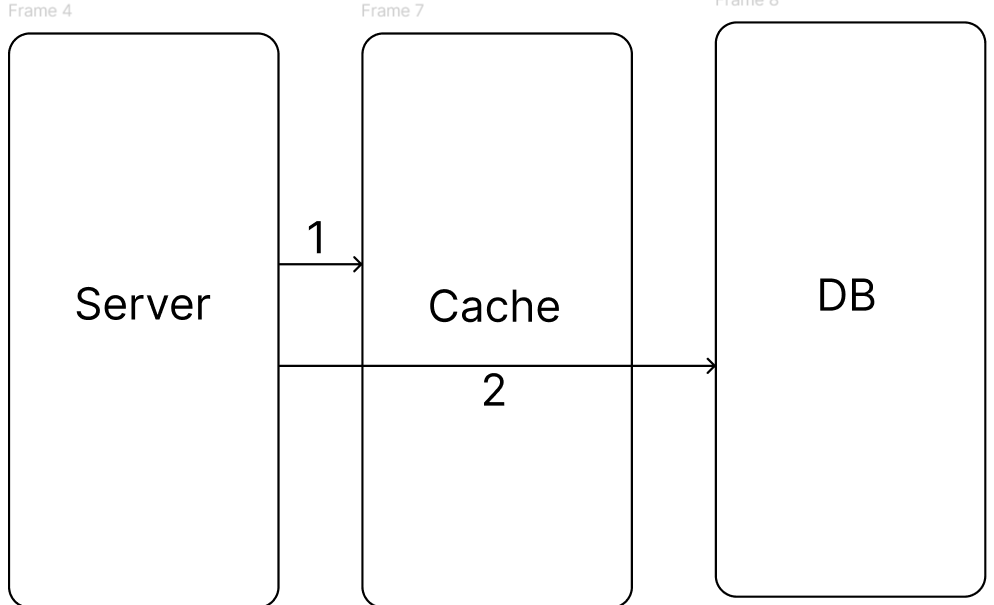
- 데이터 삭제
- DB에 데이터 저장
Write Behind(Write Back)
write through전략은 2개의 DB에 저장하는 과정때문에 속도가 떨어질수있다. 따라서 쓰기가 빈번히 일어나는 경우라면 캐시에 데이터를 우선 저장하고, 일정 주기마다 DB에 새로운 데이터를 저장하는 write behind가 적합할수 있다.
- 캐시에 데이터 저장
- 일정시간후 캐시에 저장된 데이터를 DB에 저장
장점
- 캐시에만 우선 저장하여 DB에 빈번히 접근하지 않아 성능상 이점을 가질수 있다.
단점
- DB에 저장하기전, 캐시에 문제가 발생할시 데이터가 휘발될수 있다.
어느상황에서 사용하면 좋을까?
- 실시간으로 정확한 데이터가 아니어도 되는 좋아요, DAU등에 대한 데이터를 저장할때 유용할것 같다.
Redis 자원관리
Redis는 In-Memory DB인만큼 상대적으로 작은 용량을 가지고있다. 따라서 데이터를 계속 저장하는것이 아닌 지속적으로 지우는 과정도 중요하다. 따라서 캐시로 레디스를 사용할때, 데이터를 저장함과 동시에 적절한 시간의 TTL값을 설정해야한다.
TTL
TTL(Time To Live)는 만료시간을 의미한다. 레디스는 특정키에 대한 TTL을 정하여, TTL이후 데이터가 자동삭제된다.
위의 예시는 Redis의 TTL(Time To Live) 설정과 관련된 명령어와 그 작동 방식을 보여줍니다. Redis는 키-값 저장소로, 키에 대한 TTL을 설정하면 해당 키는 TTL이 만료되면 삭제됩니다. 명령어의 작동 방식을 단계별로 설명하겠습니다.
1. TTL 설정 및 기본 동작
> SET a 100
"OK"- 키
a를 값100으로 설정합니다.
> EXPIRE a 60
(Integer) 1- 키
a에 대해 60초의 TTL을 설정합니다. 반환값(Integer) 1은 TTL 설정이 성공했음을 나타냅니다.
> INCR a
(Integer) 101- 키
a의 값을 1 증가시켜 101로 만듭니다. 값이 변경되더라도 TTL은 유지됩니다.
> TTL a
(Integer) 51- 키
a의 남은 TTL이 51초임을 나타냅니다. TTL은 설정 후 지속적으로 감소합니다.
2.RENAME 명령어
> RENAME a APPLE
"OK"- 키
a의 이름을APPLE로 변경합니다. 기존의 TTL도 함께 이동합니다.
> TTL apple
(Integer) 41- 새 이름인
APPLE에 대해 남은 TTL이 41초임을 확인합니다.
3.TTL 덮어쓰기 및 초기화
> SET b 100
"OK"
> EXPIRE b 60
(Integer) 1- 키
b에 60초의 TTL을 설정합니다.
> EXPIRE b 60
(Integer) 1- 동일한 TTL을 다시 설정합니다. 성공적으로 덮어씌워졌음을 나타냅니다.
> TTL b
(Integer) 57- 키
b의 남은 TTL은 57초입니다.
> SET b banana
"OK"- 키
b의 값을banana로 설정합니다.SET명령어는 TTL을 초기화하므로 TTL은 제거됩니다.
> TTL b
(Integer) -1- 키
b의 TTL은 제거되었으므로 -1이 반환됩니다.
레디스에서 키가 만료되어도 사실 바로 삭제되는것은 아니다. 키는 passive방식과 active방식 두가지로 삭제되는데, 각각 알아보자
- passive방식: 클라이언트가 키에 접근하고자 할 때 키가 만료됐다면 메모리에서 수동적으로 삭제한다. 사용자가 접근할 때만 수동적으로 삭제되기 때문에 이를 passive 방식의 마료라 한다. 그러나 사용자가 다시 접근하지 않는 만료된 키도 있어, 이 방식만으로는 충분하지 않다.
- active방식: TTL값이 있는 키 중 20개를 랜덤하게 뽑아낸뒤, 만료된 키를 모두 메모리에서 삭제한다. 만약 25%이상의 키가 삭제됐다면 다시 20개의 키를 랜덤하게 뽑은 뒤 확인하고, 아니라면 뽑아놓은 20개의 키 집합에서 다시 확인한다. 해당 과정을 1초에 10번씩 수행한다.
메모리 관리
TTL을 통해 키에 만료 시간을 설정하면 데이터가 자동으로 삭제되어 메모리를 확보할 수 있지만, 너무 많은 키가 저장되면 메모리가 가득 차는 경우가 발생할 수 있습니다. 따라서, 메모리 용량을 초과하는 데이터가 저장되면 내부 정책을 통해 키를 임의로 삭제해야 합니다.
Redis에서는 maxmemory 옵션과 다양한 설정을 통해 메모리를 효율적으로 관리할 수 있습니다.
Noeviction
메모리 용량이 가득 차더라도 데이터를 임의로 삭제하지 않고 에러를 발생시키는 옵션입니다. 직접 데이터를 삭제해야 하기 때문에 일반적으로 권장되지 않습니다.
Redis에서 임의로 데이터를 삭제하면 캐시 스탬피드(Cache Stampede)와 같은 문제가 발생할 수 있으므로, 애플리케이션 단에서 메모리를 관리할 필요가 있을 때 고려해볼 수 있습니다.
LRU eviction
LRU(Least Recently Used)는 최근에 사용되지 않은 데이터부터 삭제하는 정책입니다. "최근에 사용되지 않았다면, 앞으로도 사용되지 않을 가능성이 높다"는 전제에 기반한 방식입니다.
-
volatile-lru
만료 시간이 설정된 키에 한해서만 LRU 알고리즘을 적용합니다.특정 키가 삭제되면 안 되는 경우 만료 시간을 설정하지 않아야 유용합니다. 하지만 모든 키에 만료 시간이 설정되지 않으면 관리에 어려움이 생길 수 있습니다.
-
allkeys-lru
모든 키에 LRU 알고리즘을 적용합니다.Redis 공식 문서에서 권장하는 방식으로, 메모리가 가득 차 발생할 수 있는 장애를 최소화할 수 있습니다.
LFU eviction
LFU(Least Frequently Used)는 자주 사용되지 않은 데이터부터 삭제하는 정책입니다. "자주 사용되지 않은 데이터는 앞으로도 접근될 가능성이 낮다"는 전제에 기반합니다.
-
volatile-lfu
만료 시간이 설정된 키에만 LFU 알고리즘을 적용합니다. -
allkeys-lfu
모든 키에 LFU 알고리즘을 적용합니다.
LRU와 LFU 알고리즘은 자주 사용된 키와 오래 사용되지 않은 키를 계산해야 하므로 CPU와 메모리 소모가 발생할 수 있습니다. 이를 방지하기 위해 Redis는 근사 알고리즘을 사용합니다.
정확한 계산 대신 근사치를 기반으로 데이터를 삭제한다는 점을 명심하세요!
Random eviction
임의로 키를 삭제하는 정책입니다. 이 방식은 필요할 수 있는 데이터를 삭제할 가능성이 크며, 다시 캐시에 데이터를 가져오는 작업이 추가로 발생해 성능 저하를 유발할 수 있으므로 권장되지 않습니다.
캐시 스탬피드 현상
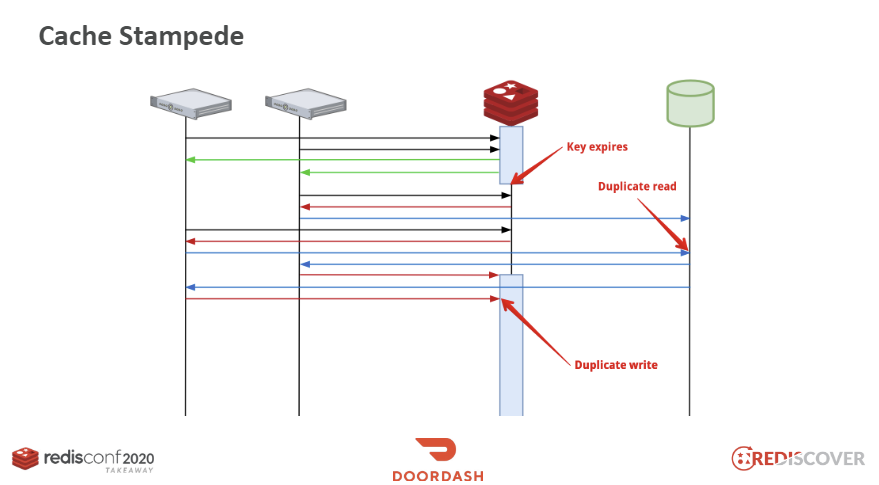
만료 시간과 maxmemory 설정을 통해 Redis의 자원을 효율적으로 관리할 수 있습니다. 그러나 캐시를 사용하는 과정에서 위 설정으로 인해 예상치 못하게 캐시가 삭제되었다고 가정해봅시다.
이 경우, 갑작스럽게 DB에 많은 트래픽이 몰리고, 동시에 Redis에 같은 키를 중복으로 쓰는 작업이 발생해 문제가 생길 수 있습니다. 이를 캐시 스탬피드라고 합니다.
캐시 스탬피드 예방 방법
선계산 (Probabilistic Early Recompute)
캐시 스탬피드 현상은 데이터가 만료되었을 때 동시에 여러 애플리케이션이 캐시에 데이터가 없음을 인지하고, DB 조회와 Redis 쓰기 작업을 병렬로 진행하면서 발생합니다. 이를 해결하기 위해 만료되기 전에 데이터를 갱신하면 문제를 예방할 수 있습니다.
아래는 선계산을 활용한 예제 코드입니다:
def fetch(key, expiry_gap):
ttl = redis.ttl(key)
if ttl - (random() * expiry_gap) > 0:
return redis.get(key)
else:
value = db.fetch(key)
redis.set(key, value, ex=KEY_TTL)
return value주기적으로 TTL 시간을 확인해 Redis 값을 갱신하면 캐시 스탬피드를 예방할 수 있습니다. 계산 작업이 추가되더라도 전체적인 성능은 향상될 가능성이 큽니다.
캐시 스탬피드를 완화하기 위한 확률적 조기 계산 알고리즘으로는 PER(Probabilistic Early Recompute) 알고리즘이 있습니다.
레디스의 더 많은 활용
Redis는 빠른 응답 속도를 자랑하는 만큼, 캐시 외에도 다양한 용도로 활용됩니다. 그중 하나는 사용자가 서비스를 이용하는 동안 지속적으로 읽고 쓰는 세션 스토어입니다.
세션이란?
세션은 서비스를 사용하는 클라이언트의 상태 정보를 의미합니다. 예를 들어, 현재 로그인한 사용자가 누구인지, 어떤 활동을 하고 있는지를 추적하기 위해 사용됩니다.
세션 스토어가 필요한 이유
단일 서버 환경에서는 서버 자체에서 세션을 관리하면 충분하기 때문에 별도의 세션 스토어가 필요하지 않습니다. 하지만 서버가 여러 대로 늘어나게 되면, 각 서버가 독립적으로 세션을 관리할 경우 스티키 세션 (Sticky Session) 문제가 발생할 수 있습니다.
스티키 세션이란 사용자가 처음 접속한 서버에 세션이 종속되어, 해당 사용자가 다시 접속할 때 반드시 같은 서버에 연결되어야 하는 문제를 뜻합니다. 이는 서버 확장성과 유연성을 제한하기 때문에, 여러 서버 간에 세션 정보를 공유하기 위해 공통 세션 스토어가 필요합니다.
Redis는 빠른 데이터 접근 속도와 다양한 자료구조를 제공하기 때문에 세션 스토어로 적합합니다. 특히, Redis의 Hash 자료형을 사용하면 세션 데이터를 효율적으로 관리할 수 있습니다.
캐시와 세션의 차이점
| 구분 | 캐시 | 세션 |
|---|---|---|
| 역할 | DB 복사본으로 데이터를 빠르게 제공 | 특정 사용자의 상태 정보 관리 |
| 공유 여부 | 여러 사용자 간 공유 가능 | 특정 사용자에 한정됨 |
| 문제 발생 시 | 캐시 문제 발생 시 DB에서 복구 가능 | 세션 데이터는 특정 사용자 전용으로 신중한 관리 필요 |
Redis를 세션 스토어로 활용하는 이유
-
고속 처리
세션은 사용자가 서비스를 이용하는 동안 지속적으로 접근되므로, DB에 저장할 경우 응답 속도가 느려질 수 있습니다. Redis는 In-Memory 기반으로 작동하여 빠른 응답 속도를 제공합니다. -
효율적인 자료구조
Redis의 Hash 자료형은 세션 데이터를 관리하기에 적합합니다. 키-값 쌍으로 저장된 데이터는 쉽게 접근할 수 있으며, 필요에 따라 유효기간(TTL)을 설정하여 자동으로 만료되도록 할 수도 있습니다.
Redis를 세션 스토어로 사용할 경우, 데이터의 신뢰성과 유일성을 보장하기 위해 신중하게 설계 및 운영하는 것이 중요합니다.
참고자료
개발자를 위한 레디스
redis 공식문서
