
저장해야하는 데이터가 많은 경우, 다양한 방법을 비교하고, 성능을 개선하는 과정에 대해 작성하였습니다.
사물함 예약 서비스는 학과별 사물함 관리를 위해 관리자 전용 기능을 제공합니다. 이를 구현하기 위해 학과사무실에서 제공하는 엑셀 파일의 재학생 데이터를 데이터베이스에 저장하는 작업이 필요했습니다. 이를 위해 Apache POI 라이브러리를 사용하여 데이터를 파싱하고 저장하는 방식을 채택했습니다.
학과당 약 1000~1500명의 재학생이 있으며, 초기 구현 단계에서 데이터를 1000개 처리하는 데 약 1.1초가 소요되었습니다. 이후, 학생 수 증가로 인해 성능 문제가 발생할 가능성을 발견하고 최적화 작업을 진행했습니다.
성능 이슈 파악
기존 코드 분석
아래는 데이터를 처리하는 주요 코드입니다. 이 코드는 엑셀 데이터를 읽어 행 단위로 파싱하고, 각 데이터를 데이터베이스에 저장합니다.
private void processExcelData(Workbook workbook, MajorDetail majorDetail, User user) throws Exception {
for (int sheet = 0; sheet < workbook.getNumberOfSheets(); sheet++) {
Sheet workSheet = workbook.getSheetAt(sheet);
for (int i = 1; i < workSheet.getPhysicalNumberOfRows(); i++) {
Row row = workSheet.getRow(i);
if (row != null && row.getCell(0) != null && row.getCell(1) != null && row.getCell(2) != null) {
setRowType(row);
String studentNum = row.getCell(0).getStringCellValue();
String studentName = row.getCell(1).getStringCellValue();
String checkDues = row.getCell(2).getStringCellValue();
verifyBlank(studentNum, studentName, checkDues);
if (studentName.isEmpty() && studentNum.isEmpty() && checkDues.isEmpty()) {
continue;
}
boolean isDues = determineDuesStatus(checkDues);
userUseCase.updateUserDueInfoOrSave(UpdateUserDueInfoDto.builder()
.isDue(isDues)
.studentNum(studentNum)
.name(studentName)
.majorDetail(majorDetail)
.build());
}
}
}
}이 코드는 엑셀의 모든 행을 처리할 때마다 userUseCase.updateUserDueInfoOrSave()를 호출합니다. 이 메서드는 데이터베이스에서 학생 정보를 조회한 뒤, 존재하지 않으면 새로운 데이터를 저장합니다.
public void updateUserDueInfoOrSave(UpdateUserDueInfoDto updateUserDueInfoDto) throws Exception {
User user = userQueryPort.findByStudentNum(updateUserDueInfoDto.getStudentNum())
.orElseGet(() -> userQueryPort.save(
User.builder()
.name(updateUserDueInfoDto.getName())
.studentNum(updateUserDueInfoDto.getStudentNum())
.userTier(UserTier.judge(updateUserDueInfoDto.isDue()))
.role(Role.ROLE_USER)
.majorDetail(updateUserDueInfoDto.getMajorDetail())
.auth(false)
.build())
);
if (user.isAuth()) {
user.updateTier(UserTier.judge(updateUserDueInfoDto.isDue()));
}
}문제는 이 과정에서 데이터베이스 요청이 반복적으로 발생해, 데이터가 1000개일 경우 약 1000회의 SELECT 및 INSERT 쿼리가 실행된다는 점이었습니다. 이는 성능 저하의 주요 원인이었습니다.
최적화 과정
save()와 saveAll() 비교
updateUserDueInfoOrSave() 메서드에서 반복적으로 실행되는 쿼리를 줄이기 위해, JPA의 saveAll() 메서드를 활용해 Bulk Insert 방식을 적용했습니다. 이를 통해 데이터베이스 호출 횟수를 줄여 성능을 개선할 수 있었습니다.
성능 비교
-
기존 방식 (
save)
응답 시간:1.1초 -
Bulk Insert 적용 (
saveAll)
응답 시간:0.52초
saveAll() 메서드가 save() 대비 성능이 개선되는 이유는 트랜잭션 처리 방식에 있습니다.
스프링에서 save()와 saveAll()의 트랜잭션 처리 차이
먼저 코드를 살펴보겠습니다!
@Transactional
@Override
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}saveAll()을 보니 단순히 내부에서 save()를 엔티티의 수만큼 호출하는것을 볼수있습니다!
트랜잭션과 스프링 AOP의 동작 방식
saveAll()은 결국 save()를 사용하는데, 왜 성능 차이가 날까요?? 그것은 스프링이 AOP를 지원하는 원리에 숨겨있습니다.
스프링 컨텍스트에 등록된 빈은 프록시 객체로 감싸지며, AOP는 이 프록시 객체를 통해 메서드 호출 전후에 동작합니다. 하지만 클래스 내부에서 호출되는 메서드는 프록시를 거치지 않기 때문에 AOP 로직이 적용되지 않는다는 점입니다.
save()
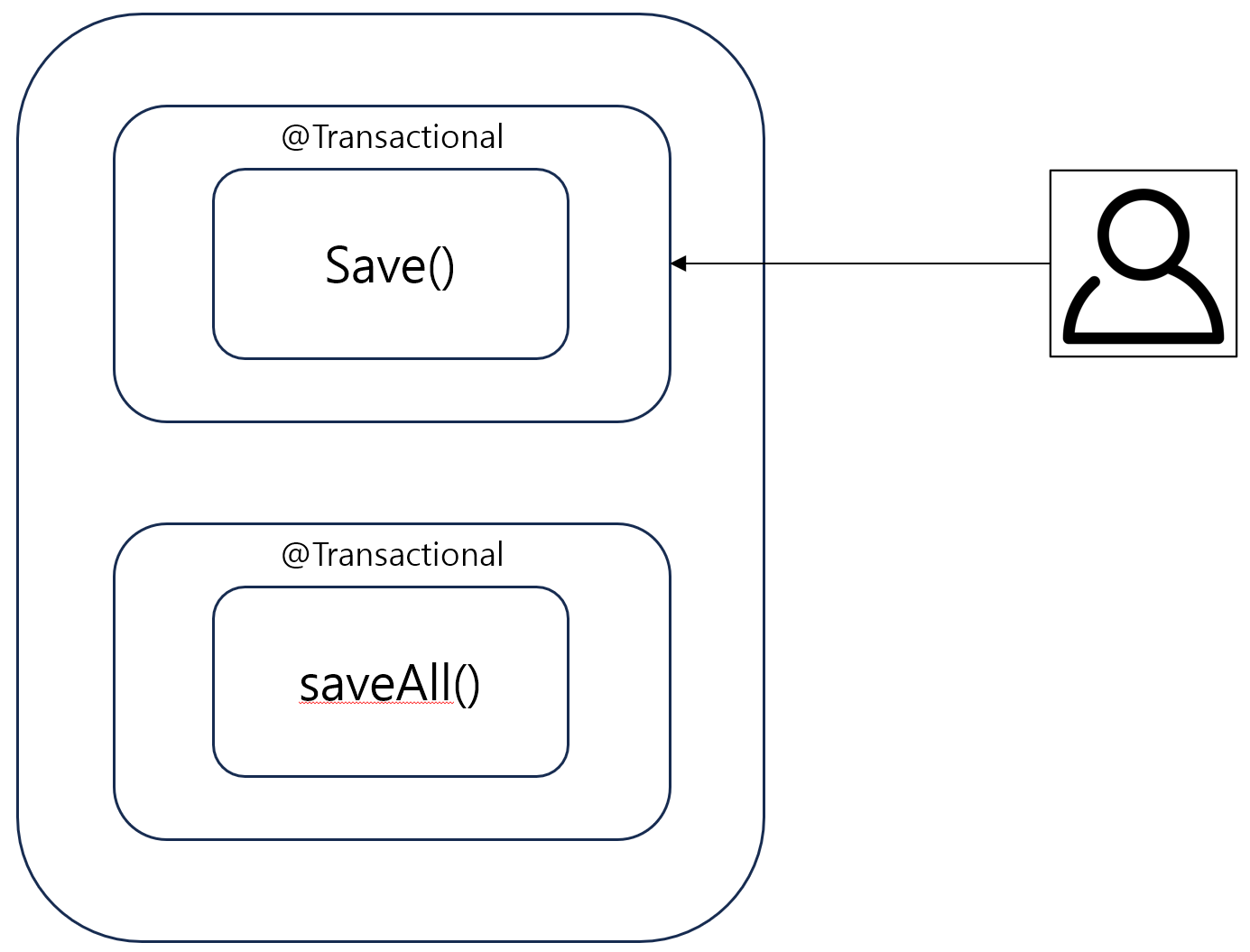
사용자가 save()를 호출할 경우 @Transactional기능이 추가된 프록시 객체로 호출하게 됩니다! 따라서 클라이언트가 반복문으로 save()를 호출하면 트랜잭션이 호출한만큼 열렸다 닫히게 됩니다!
saveAll()
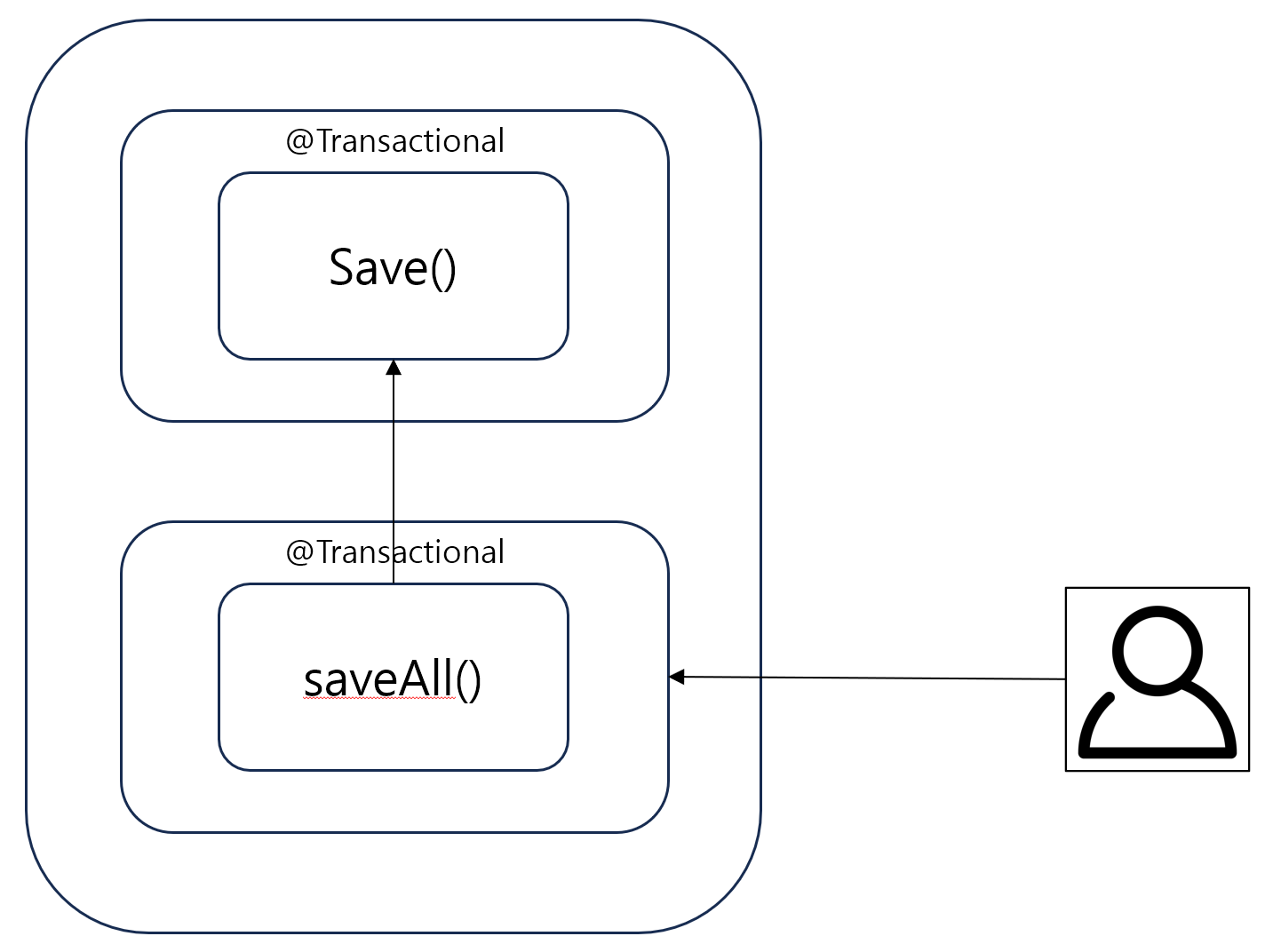
saveAll()을 호출하면 어떻게 될까요? 그림을 보면 saveAll()이 @Transactional이 적용되어 있는 프록시 객체가 아닌 save()메서드 자체를 호출하게 됩니다! 왜냐하면 프록시 객체는 스프링 컨텍스트에 저장되어있는데, saveAll()은 save()코드 자체를 호출했기때문에 AOP가 적용되지 않기 때문입니다.
즉, 내부 메서드를 호출하면 프록시를 거치지 않으므로 AOP에서 설정한 트랜잭션이 동작하지 않습니다. 이로 인해 save()와 saveAll()의 트랜잭션 처리 방식이 달라지고, 성능 차이가 발생하게 됩니다.
정리하면, 성능 차이는 트랜잭션의 호출 횟수 차이에서 발생한다!!
- save() 반복 호출 → 트랜잭션 여러 번 생성 (비효율적).
- saveAll() 호출 → 한 번의 트랜잭션으로 처리 (효율적).
Bulk Insert 구현: JDBC로 성능 극대화
saveAll() 방식으로도 성능을 개선했지만, 실제 쿼리 로그를 확인한 결과, 여전히 쿼리 하나당 한 행씩 처리하는 방식이었습니다. MySQL의 IDENTITY 전략은 JPA에서 Bulk Insert를 지원하지 않기 때문에, 진정한 의미의 Batch Insert를 구현하기 위해 JDBC를 사용했습니다.
public void bulkInsert(List<User> users) throws SQLException {
Connection con = DriverManager.getConnection(url, username, password);
String sql = "INSERT INTO user_jpa_entity (auth_id, auth_type, height, new_flag, nickname, role, username, weight) VALUES (?, ?, ?, ?, ?, ?, ?, ?)";
PreparedStatement pstmt = con.prepareStatement(sql);
con.setAutoCommit(false);
try {
int batchSize = 100;
int count = 0;
for (User user : users) {
pstmt.setString(1, user.getAccount().getAuthId());
pstmt.setString(2, user.getAccount().getAuthType().toString());
pstmt.setInt(3, user.getHeight());
pstmt.setBoolean(4, user.getAccount().isNewUser());
pstmt.setString(5, user.getNickname());
pstmt.setString(6, user.getAccount().getRole().toString());
pstmt.setString(7, user.getName());
pstmt.setInt(8, user.getWeight());
pstmt.addBatch();
count++;
if (count % batchSize == 0) {
pstmt.executeBatch();
pstmt.clearBatch();
}
}
pstmt.executeBatch();
con.commit();
} catch (Exception e) {
con.rollback();
throw e;
} finally {
con.setAutoCommit(true);
pstmt.close();
con.close();
}
}성능 비교
-
saveAll()
응답 시간:0.52초 -
JDBC Batch Insert
응답 시간:0.18초
Batch Insert는 데이터베이스로 보내는 쿼리 횟수를 최소화하여 성능을 극대화했습니다. 예를 들어, 1000개의 데이터를 처리하는 경우, 100개씩 묶어서 10번의 쿼리만 실행됩니다.
결론
이번 최적화 작업을 통해 JPA의 한계를 이해하고, JDBC를 사용해 성능을 극대화하는 방법을 학습할 수 있었습니다. JPA는 편리한 개발 경험을 제공하지만, 대량의 데이터를 처리할 때는 JDBC를 활용한 Batch Insert가 더 적합하다는 점을 확인했습니다.
최종 성능 개선 결과:
1. save → 1.1초
2. saveAll → 0.52초
3. JDBC Batch Insert → 0.18초
