Plonky2 = Plonk + custom gates
FRI PCS
fast recursion -
recursion : verify proof in another proof
(p,v)가 있을때 pi(proof)와 pi가 올바르다는 proof 총 두개의 proof를 만든다
v를 circuit안에 넣어놓으면 recursion?
어쨌든, 이전 증명을 검증하고, 새로운 증명을 생성하는 과정의 반복
current approach to recursion
Groth16 : E(F_q) -paring friendly (base field)
F_P - scalr field(주로 타원곡선에서 점을 스칼라 곱하는데 사용됨)
-> 의미: base field는 eliptic curve의 point가 있는 곳, scalar field의 order는 base field의 곡선의 차수와 같음
V does operation in Fp and Fq
proving system is Fp
그런데 일반 cpu에서도 Fp와 Fq에 대한 연산은 가능하다 뭐가 문제인가?
기존의 접근 방식에서는 Groth 16과 같은 시스템이 사용되었고, 이는 타원 곡선을 기반으로 한다. 그러나 재귀 과정에서 FP(기본 필드)와 Fq(스칼라 필드) 간의 연산이 비싸다.
같은 커브에 있으면 Fp operation은 싸지만, Fq operation은 비싸다
그래서 verify하려면 Fq에서 직접 연산하지 않고, non-native arithmetic(비트 연산이나 다른 필드로의 변환)을 해야함. 그러나 이는 연산 복잡성을 증가시킴
그리고 overflow때문에 Fq에 있는 값을 Fp에 표현할 수 없음.
그래서 range check도 해야함
E <-> E' : E'(Fp) - scalar field Fq
E : original curve
E' : second curve(base field FP로 defined)
proof Pi / E 선택
Verifier V / E' - scalar field of E'은 Fq
proof Pi를 선택하고 based on E
검증자가 E'와 같은 두 번째 곡선을 사용하여 Fq로 전환한다. 이 과정에서 Fq의 연산이 저렴해진다.
그런데 verify하는 비용이 더 비싸므로 바뀌면 이득이다
타원 곡선의 두 사이클을 사용하여 기본 필드와 스칼라 필드를 변경함으로써 연산 비용을 줄입니다.
하지만 kzg같은 곳에서는 cycle with reasonable size를 모르고
best known size는 700-800 bits이다
cpu가 64bit임을 감안할때 엄청 크다
그래서 paring based로 verify하고자 하면 issue가 된다
IPA(inner product argument)- based PCS
DLP기반이다 -> curve of size 256bits를 쓸 수 있음, 128bit 안전도를 준다
-> much cheaper
verfication in linear
Halo
verification을 logarithmic하게 할 수 있음
-> accumulation (모든 증명을 recursion으로 처리, verify를 지연시킬 수 있음 그러나 한개만 맞으면 다른 증명들이 맞다는 strong guarantee를 얻을 수 있음)
최종 검증 비용을 선형으로 줄임.
E . -> acc(log)-> acc(log) -> verify(linear)
E+ . -> . -> . -> .
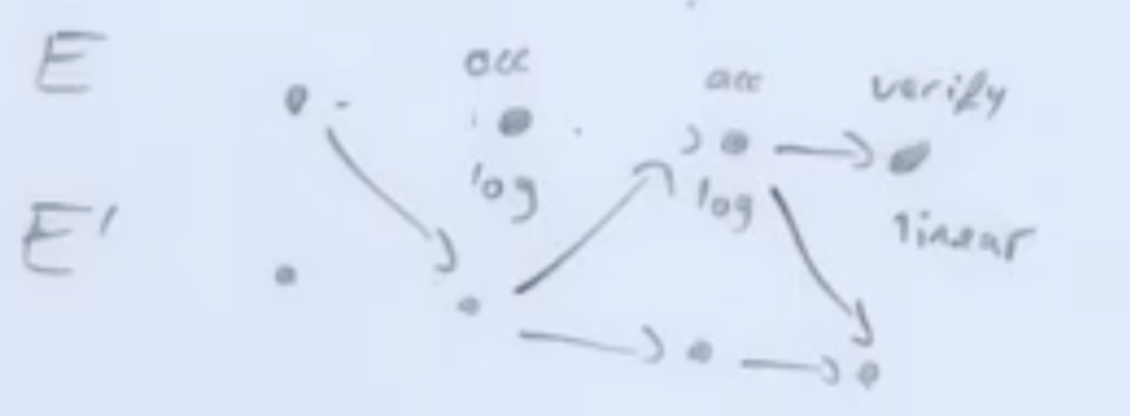
이게 plonky 1
Plonky2
FRI -based PCS
- no non-native stuff
- use small field
- no trusted setup, post-quantum secure
Fry는 단일 필드(FP)에서 모든 연산을 수행하여 복잡성을 줄임.
Plonky2는 turbo plonk를 통해서 강력한 arithmatization을 제공함.
정수 및 비트 구조
증명 시스템에서는 비트 단위로 문제를 표현하는 것이 중요하다.
128비트 정수는 이진수로 표현 가능하고, 그러면 구조가 잘 갖춰져 있다고 한다.
두 개의 64비트 정수 X와 Y를 곱할 때, 결과는 128비트 정수가 된다. 이때 곱셈 연산을 빠르게 수행하려면 P로 모듈로 하는 것이 필요하다.
custom gate
커스텀 게이트는 특정 연산이나 제약 조건을 모델링 할 수 있어서, 연산 효율성을 크게 향상시킨다
예를 들어 곱셈이나 비트 연산과 같은 특정 게이트를 정의하다 보면, 최적화된 방식으로 문제를 해결할 수 있다.
무작위 소수의 중요성
증명 시스템에서 무작위 소수를 사용하는 것은 매우 중요합니다. 이는 특정 구조적 문제를 해결하는 데 도움이 됩니다. 예를 들어, 128비트 정수를 P로 나누는 경우, 해당 연산은 모듈로 P에서 수행되며, 이는 상대적으로 빠르다.
Goldilocks 필드를 사용해서 FPGA나 GPU 구현이 용이해진다.
route wire(실제 계산 수행), advice wire(필요한 데이터를 전달)를 사용하면 필요한 연산만 수행해서 중간 단계 생략가능
-> proof size를 조정 가능
custom gate
plonky2에서는 모든 wire가 라우터 가능하다.
plonky2는 여러 최적화 기능을 사용하여 성능을 개선하는데, Miracle caps으로 merkle tree의 leaf, 중간 레이어, 루트를 연결한다.
이를 통해 region 증명을 줄여주고, 해시 목록에서 랜덤 엑세스를 통해 간단히 검증 가능하다
rollup에서 사용
keccak을 사용하여 증명 생성 속도를 높이고, L1에서의 검증 비용을 줄인다. poseidon 해시함수보다 효율적임
그래서 결국 Plonky2는 모든 재귀 단계에서 다양한 매개변수를 이용하여 원하는 대로 최적화 가능하다
