엔티티 매니저 팩토리와 엔티티 매니저
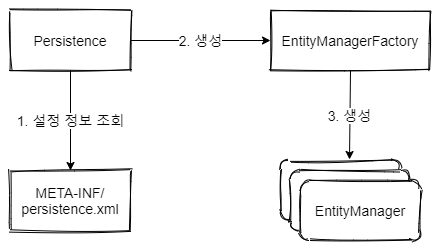
JPA를 시작하며 가장 기본적으로 사용되는 객체가 엔티티 매니저 팩토리와 엔티티 매니저이다. JPA를 기본적으로 데이터를 엔티티 단위로 받아오기 때문에 엔티티를 관리할 수 있는 수단이 필수적이다.
EntityManagerFactory는 하나의 애플리케이션에 하나만 생성하여 사용한다. 왜냐하면 하나의 인스턴스를 생성하는데에 드는 비용이 크기 때문이다. JPA를 구동시킬 기본적인 객체나 여러 커넥션이 함께 생성되기도 한다. 이렇게 생성된 하나의 EntityManagerFactory로 여러 개의 EntityManager를 생성하여 사용한다.
EntityManager는 하나의 가상 데이터베이스로 생각하여 사용하면 되는데, 이 인스턴스를 활용해 실제 엔티티를 핸들링하게 된다. JPA에서는 개발자가 논리적으로 Transaction을 구현하기 때문에 EntityManager를 동시에 접근하면 동시성 문제가 발생할 수 있다.
영속성 컨텍스트란?
영속성(Persistence)이란 JPA의 P에 해당하는 단어로 변하지 않는 성질을 의미한다. 그리고 Context는 물리적으로 어떤 리소스의 집합이고, 논리적으로는 어떤 것들이 실행될 수 있는 환경이다. 따라서 영속성 컨텍스트는 데이터가 지속될 수 있도록 구성된 환경이라고 볼 수 있다.
EntityManager가 트랜잭션을 만들어 어떤 로직을 처리할 때 엔티티 단위의 CRUD를 발생시킨다. 이 CRUD는 바로 데이터베이스에 반영되는 것이 아니라 영속성 컨텍스트에 먼저 반영된다.
INSERT
em.persist(member);위와 같은 코드가 transaction안에서 실행되었다고 하자. 그렇다면 만들어놓은 member 객체를 바로 데이터베이스에 반영하지 않는다. 우선 영속성 컨텍스트에 반영한다.
영속성 컨텍스트에서는 Id, Instance의 하나의 Map이 있다. 이 Map에 member 인스턴스의 식별자 값을 Key에, member 인스턴스 자체를 Value에 넣어서 보관하고 있는다. 이를 쓰기 지연이라고 한다. 영속성 컨텍스트는 쓰기 지연을 구현하기 위해서 쓰기 지연 SQL 저장소를 내부적으로 가진다. 쓰기 지연된 엔티티에 대한 SQL을 이 저장소에 보관하고 있는다. 그리고 transaction이 commit될 때 한 번에 모든 비즈니스 로직 쿼리가 데이터베이스로 요청된다.
UPDATE
Member member = em.find(Member.class, 1);
member.setName("jaeseok-go");위와 같은 코드를 실행하면 자동으로 update 쿼리가 생성된다. 우선 find로 불러온 member entity는 영속성 컨텍스트에 추가된다. 영속성 컨텍스트에 어떤 엔티티가 추가 될 때 추가되는 시점의 상태를 저장하고 있는 스냅샷이 같이 추가된다. 그리고 트랜잭션이 커밋될 때 쿼리가 데이터베이스에 요청되기 전, 영속성 컨텍스트에서 관리하는 Map에 스냅샷과 비교하여 변경된 부분이 있는지 찾는다. 변경된 부분이 있다면 변경을 요청하는 Update 쿼리를 쓰기 지연 SQL 저장소에 저장하고 최종적으로 쿼리로 데이터베이스에 요청한다.
이 때 만들어지는 update문은 변경된 컬럼만 수정하는 update 문이 아니다. 모든 컬럼을 다시 한번 명시하여 만들어진다. 이렇게 만들어지는 이유는 수정 쿼리가 항상 같기에 쿼리의 재사용성을 활용하기 위함이다.
DELETE
Member member = em.find(Member.class, 1);
em.remove(member);delete의 경우에도 update와 동작 원리는 같다. 하지만 remove 메소드는 영속성 컨텍스트에서 아예 해당 인스턴스를 삭제해버리기 때문에 인스턴스는 가비지 컬렉터가 메모리를 수거한다.
영속성 컨텍스트로 얻는 이점
JPA에서 영속성 컨텍스트를 사용함으로써 얻는 다양한 이점이 존재한다.
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
- 지연 로딩
위와 같은 이점을 하나씩 살펴보자.
1차 캐시
비즈니스 로직에서 어떤 결과값을 요청할 때 먼저 영속성 컨텍스트에 있는지 확인한다. 영속성 컨텍스트에 원하는 결과 값이 없다면 그제서야 데이터베이스에 요청을 보낸다.
하지만 영속성 컨텍스트에 원하는 결과 값이 있다면 바로 그 값을 반환한다. 따라서 1차 캐시로서의 영속성 컨텍스트의 역할 덕분에 이러한 성능상 이점을 누릴 수 있다.
동일성 보장
똑같은 쿼리를 두 번 요청했다고 생각해보자. 각 쿼리의 결과 값을 새로운 변수를 만들어서 반환받았다. 두 개의 새로운 변수에 내용은 같지만 따로 요청한 쿼리의 결과값이 들어가있기에 두 변수의 인스턴스는 다를 것으로 예상된다.
하지만 두 변수의 인스턴스는 동일하다. 첫 번째 쿼리가 실행되어 영속성 컨텍스트에 만들어진 인스턴스가 두 번째 쿼리가 실행될 때 영속성 컨텍스트에 이미 만들어져있기 때문에 그대로 반환되기 때문이다.
트랜잭션을 지원하는 쓰기 지연
여러가지 로직을 처리하고 트랜잭션을 끝내는 메소드가 있다고 가정해보자. 각 로직이 각각 하나의 쿼리를 발생시킬 때, 모든 쿼리를 데이터베이스에 요청해야만 할 것이다. 하지만 영속성 컨텍스트는 1차 캐시기능을 가지고 있어 모든 로직이 실행되고 트랜잭션이 커밋되는 시점의 상태만을 요청하면 된다.
변경 감지
이미 만들어졌거나(persist) 불러왔던(find) 인스턴스를 영속성 컨텍스트에 저장해놓고 수정되거나(setter), 삭제된(remove) 내역만 감지하여 쿼리를 만들어낸다.
지연 로딩
member.getTeam();위의 코드만으로 member와 연관관계가 있는 Team 테이블을 엔티티 리스트로 받아올 수 있다.
플러시
플러시는 개발자가 직접 사용하기도 하지만 대부분 트랜잭션이 커밋되는 시점에 자동으로 실행된다. 플러시 메소드가 실행되면 아래와 같은 과정이 발생된다.
- 변경 감지가 동작한다. 모든 변경 사항이 SQL 저장소에 쿼리로 등록된다.
- 쓰기 지연 SQL 저장소에 있던 모든 쿼리를 데이터베이스로 전송한다.
여러가지 영속 상태
지금까지 말했던 영속성 컨텍스트에 엔티티가 등록되는 상태를 영속 상태라고 한다. 하지만 엔티티는 영속상태뿐 아니라 다양한 상태로 존재할 수 있다. 다양한 영속 상태를 알아보자.
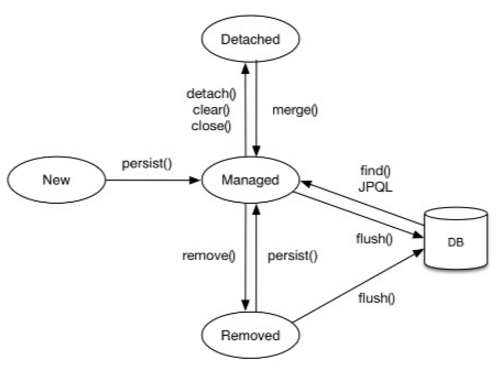
우선 아무것도 아닌 비영속 상태가 있다. 엔티티 인스턴스가 생성되었지만 persist 메소드가 사용되기 전의 단계이다.
영속 상태는 엔티티가 관리되고 있는 상태라고 볼 수 있다. 위에서 설명되었던 모든 기능이 사용될 수 있다. 하지만 준영속 상태가 되면 거의 모든 기능을 사용할 수 없다. 특정 엔티티를 준영속 상태로 만들기 위한 방법으로는 detach(entity) 메소드를 사용하는 방법이 있고, 아예 영속성 컨텍스트를 close(), clear()하는 방법으로 모든 엔티티를 준영속 상태로 만들 수 있다.
이렇게 준영속 상태가 된 엔티티는 merge() 메소드로 다시 영속 상태로 만들 수 있다.
