JVM의 구조
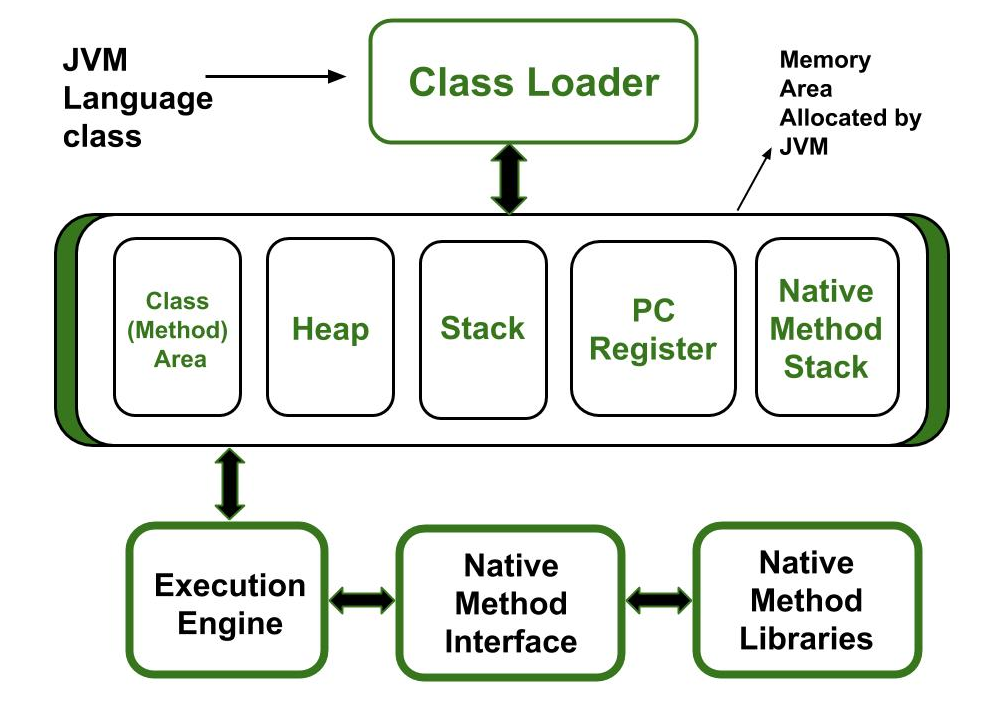
위와 같은 구조로 구성된 JVM이 어떤 식으로 동작하는지 한번 알아보자.
우선 java파일을 javac가 컴파일해서 .class 확장자로 떨어지는 바이트 코드 파일이 존재한다. JVM은 이 바이트 코드 파일을 실행시킬 것이다.
클래스로더
그러기 위해 클래스로더가 JVM으로 바이트 코드 파일을 가져와서 알맞게 메모리를 세팅한다.
우선 로딩의 과정이 있다. 클래스로더는 바이트 코드 파일을 가지고 와서 알맞는 바이너리 데이터를 만든다. 그리고 이 데이터를 클래스 영역에 저장하게 된다. 이 때 클래스 영역에 저장되는 데이터로는 FQCN(Full Qualified Class Name), 클래스의 종류(class/interface/enum), 클래스의 메소드/변수 등이 있다.
로딩의 과정이 끝나면서 힙영역에 메모리 영역에 저장된 클래스 데이터의 인스턴스를 만들어서 저장한다.
두 번째로는 링크 과정을 거친다. 링크 과정에서는 검증하고, 준비하고, 연결한다. 우선 바이트 코드 파일이 유효한지 검증한다. 그리고 static 변수와 같이 기본적으로 필요한 변수를 클래스 영역에 준비한다. 마지막으로 구성되어 있는 참조들을 실제 힙영역에 있는 인스턴스와 연결한다.
이렇게 링크 과정이 끝난다면 초기화 과정을 수행하며 이 때 준비되어 있던 static변수에 알맞는 데이터를 할당한다.
메모리 영역
JVM의 메모리 영역 역시 세부 영역으로 나뉘며 각 세부 영역마다 저장되는 데이터의 종류가 상이하다.
가장 왼쪽의 클래스 영역과 힙 영역은 공유 자원이다. 클래스 영역을 말 그대로 클래스 관련 데이터와 static 변수와 같은 기본 자원들을 저장한다. 그리고 힙 영역에는 객체 인스턴스들을 저장한다.
스택 영역에서는 스레드마다 스택을 만든다. 하나의 스레드가 가지고 있는 스택에서는 이 스레드가 메소드를 호출할 때마다 스택 프레임을 쌓는다. 이 프레임 안에서 지역 변수등을 선언하고 이 때 사용되는 참조 변수는 힙 영역에 있는 인스턴스를 참조하게 된다. 스레드를 종료하게 되면 스택도 사라지게 된다.
PC는 Program Counter의 약자로 현재 스레드가 실행할 명령어의 위치를 저장하고 있는 작은 메모리이다.
그리고 마지막으로 네이티브 메소드 스택은 네이티브 메소드와 관련된 스택 메모리이다.
실행 엔진
이렇게 구성되어 있는 메모리에 클래스로더가 알맞게 데이터를 세팅했다. 이 상태에서 실행엔진이 어플리케이션을 실행 할 것이다.
실행 엔진은 내부적으로 인터프리터, JIT 컴파일러, 가비지 콜렉터를 가진다. 인터프리터는 메모리에 저장되어 있는 바이너리 데이터를 PC의 값에 따라 어플리케이션을 실행시킨다. 이 때 반복되는 작업이 있다면 JIT 컴파일러가 네이티브 코드로 바꾸고 인터프리터는 이 네이티브 코드를 곧바로 실행한다.
이렇게 실행되고 있는 어플리케이션에 사용되지 않는 변수나 인스턴스를 가비지 컬렉터가 알아서 반환하게 된다.
객체 생성 코드
public class Person {
private int age;
private String language;
public Person(){}
public Person(int age, String language){
this.age = age;
this.language = language;
}
}
public static main(String[] args){
Person jaeseok = new Person(0, "Java");
}위와 같은 객체 생성 코드가 있다고 하자.
객체를 생성하기 위해서 클래스 로더는 우선 컴파일된 .class 파일을 읽고 바이너리 데이터로 변환한다. 그리고 Class 영역에 Person이라는 클래스가 저장되어있는지 확인한다. 저장되어있지 않다면 클래스의 상수 풀, 필드 정보, 메소드 정보, 생성자 정보, FQCN등을 저장한다. 그리고 생성자 코드를 참고하여 생성된 객체를 Heap 영역에 저장한다.
그리고 .class 파일이 유효한지 바뀌지 않았는지 먼저 검사하고 Stack 영역에 생성된 jaeseok이라는 참조 변수가 가리키는 심볼릭 링크를 실제 참조 주소로 변환한다. 이 과정에서 jaeseok이라는 참조 변수가 가지는 참조 값이 Heap 영역의 객체이므로, jaeseok은 인스턴스화가 된다.
생성자?
생성자는 인스턴스 생성 시에 호출되는 특별한 기능이며 보통 클래스 내부에 클래스와 같은 이름으로 정의한다.
public class Person {
private int age;
private String language;
// 생성자 1
public Person(){}
// 생성자 2
public Person(int age, String language){
this.age = age;
this.language = language;
};
}
public static main(String[] args){
Person jaeseok = new Person(0, "Java");
}위 코드에서 Person()으로 정의된 부분이 생성자 부분이다.
만약 생성자를 만들지 않고 클래스를 정의한다면 Java 컴파일러가 컴파일 시에 자동으로 Default 생성자를 만들어서 넣어준다. 기본 생성자의 형태는 위의 코드의 생성자 1과 같다.
만약 위의 생성자 1의 코드가 없다고 가정했을 때,
Person jaeseok = new Person();이와 같은 코드가 있다고 하자. 그럼 오류가 발생한다. 생성자 2가 있기 때문에 컴파일러가 기본생성자를 자동으로 추가해주지 않는다.
따라서, 보통 클래스를 정의할 때에는 기본 생성자를 같이 정의해주는 것이 바람직하다.
static variable?
static 변수, 인스턴스의 필드, 지역 변수는 각자 다른 영역에 담겨서 사용된다.
지역 변수는 Stack 영역에 생성되어, Heap 영역과의 레퍼런스 없이 바로 사용가능하다. 보통 지역 변수들은 메소드가 수행될 때 Stack 영역에 할당되고 메소드가 끝나면 메모리를 정리한다.
인스턴스의 필드는 인스턴스가 생성될 때 Heap 영역에 초기화되어 Garbage Collector에 의해 인스턴스가 삭제되면 함께 삭제된다. 그리고 인스터스마다 각자 다른 값을 가질 수 있다.
하지만 클래스의 static 변수는 클래스가 생성될 때 Class Area에 생성되어 GC의 관리를 받지 않는다. 그리고 클래스가 삭제될 때 같이 삭제되므로, 프로그램 종료 시까지 메모리를 할당받은 상태로 존재하여 프로그램 성능의 저하를 야기시킬 수도 있다. 그리고 많은 객체가 static변수를 공유하기 때문에 데이터의 무결성을 보장하는 별도의 처리가 필요하다.
call by value VS call by reference
자바에서 함수를 호출하는 방식은 크게 두 가지로 나누어 볼 수 있다. 이를 call by value, call by reference라고하는데, 직역하면 값에 의한 호출, 참조에 의한 호출이다.
실제 의미도 같다.
call by value부터 보자면 파라미터를 기본타입으로 전달하여 함수를 호출한다. 그렇기때문에 함수 내에서 값을 변경하더라도 값만 복사해서 받은 것이기 때문에 함수 실행이 끝나면 파라미터로 넘겨줫던 주소의 변경값은 반영되어 있지 않다.
그리고 call by reference는 파라미터를 참조타입으로 전달하여 함수를 호출한다. 그렇기때문에 함수 내에서 값을 변경하면 참조타입의 주소값에 있는 값을 직접 변경하기 때문에 함수 실행이 끝나면 파라미터로 넘겨줬던 주소의 변경값이 반영된다.
아래의 코드를 참고해보자.
public static void main(String[] args) {
// 20개짜리 배열을 만든다.
int[] arr = new int[20];
// 5번째 배열을 100으로 업데이트하는 메소드를 호출한다.
update5th(arr[5]);
System.out.println(arr[5]); // 0
// 10번째 배열을 100으로 업데이트하는 메소드를 호출한다.
update10th(arr);
System.out.println(arr[10]); // 100
}
// call by value
private static void update5th(int value) {
value = 100;
return;
}
// call by reference
private static void update10th(int[] reference) {
reference[10] = 100;
return;
}
위의 코드에서 call by value로 호출한 첫 번째 메소드는 arr[5]라는 int형 데이터를 전달한다. 메소드에서 전달받은 value값을 100으로 바꿨지만 이 value는 arr의 5번째 인덱스를 주소로 가진 변수가 아니라 해당 메소드에서 사용되는 로컬 변수이기 때문에 arr[5]의 값이 바뀌지 않는다.
하지만 call by reference로 호출한 두 번째 메소드는 arr이라는 int[]형 데이터를 전달한다.
메소드에서 전달받은 reference는 arr의 주소값을 가지고 있다. 왜냐하면 참조 변수를 파라미터로 받았기 때문이다. 참조 변수는 힙 영역에 생성된 할당 메모리 주소를 가지고 있는 변수이다. 그렇기때문에 두번째 메소드는 arr 배열의 실제 주소를 전달받았기에 이 주소의 값을 100으로 변경하면 값이 그대로 변경된다.
