단방향 매핑
데이터베이스에서 두 개의 테이블은 서로 연관 관계를 가지기도 한다. 예를 들어 Member table에는 Job table에서 member의 job을 참조할 job_id를 외래키로 가지게 된다. 이러한 경우에 두 테이블은 서로 연관 관계를 가진다고 한다.
데이터베이스에서는 job_id를 가지고 두 개의 테이블에서 원하는 결과를 가져올 수 있다. 하지만 객체에서 하나의 필드로 원하는 결과를 가져오기 위해서는 상당히 지저분하거나 복잡한 로직이 필요하다. 대신 다른 엔티티의 참조 값을 가지고 있음으로써 간단하게 나와 연관관계가 있는 엔티티의 정보를 가져올 수 있다. 엔티티에서의 연관관계 매핑은 이런식으로 이루어진다.
기본적으로 아래와 같은 테이블이 있다고 생각해보자
CREATE TABLE MEMBER (
ID INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(50) NOT NULL,
JOB_ID INT,
FOREIGN KEY ('JOB_ID') REFERENCES JOB('ID');
)
CREATE TABLE JOB (
ID INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(50) NOT NULL,
AVG_SALARY INT
)데이터베이스에서 id가 1인 멤버의 job name을 알고 싶다고 하자. 그렇다면 아래와 같은 쿼리를 작성해야 할 것이다.
SELECT NAME
FROM JOB
WHERE ID = (SELECT JOB_ID
FROM MEMBER
WHERE ID = 1);
OR
SELECT J.NAME
FROM MEMBER M LEFT OUTER JOIN JOB J
ON M.JOB_ID = J.ID
WHERE M.ID = 1;데이터베이스에서는 job_id라는 외래키 컬럼을 가지고 이렇게 조회할 수 있다. 그렇다면 JPA에서는 어떨까?
Member member = em.find(Member.class, 1);
String jobName = member.getJob().getName();JPA에서도 생각보다 간단하게 조회가 가능하다. 이것이 다 연관관계를 매핑해놓았기 때문이다.
@Entity
public class Member{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
@Column(name = "name")
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "job_id")
private Job job;
}위의 Member 엔티티 코드에서는 Job을 인스턴스 참조 값으로 그대로 가진다. 따라서 위의 코드 처럼 객체를 탐색하여 손쉽게 job name을 찾을 수 있었던 것이다.
이 경우에는 Member -> Job으로의 한 방향의 연관관계만 정해져있다. 이러한 연관관계를 단방향 연관관계라고 한다.
매핑 어노테이션
@ManyToOne
테이블 간의 연관관계는 일대일, 일대다, 다대다로 구분지을 수 있다. 한쪽 테이블에서 일대다라면 반대쪽에서는 다대일 관계이다.
위의 코드에서 @ManyToOne이라는 어노테이션을 보았을 것이다. 이 어노테이션을 그대로 해석하자면 다대일 관계라는 뜻이다. 어떤 하나의 job을 가진 member는 여러 명이 될 수 있다. 반면에 하나의 member는 하나의 job만을 가진다. 따라서 member 입장에서는 다가 되고 job 입장에서는 일이 된다.
비슷한 어노테이션으로는 @OneToOne, @OneToMany, @ManyToMany가 있으면 연관관계를 적절하게 판단하여 사용하면 된다.
@JoinColumn
위 코드의 어노테이션 중에 @JoinColumn이라는 어노테이션을 보았을 것이다. 이 어노테이션은 엔티티에서 참조 값으로 가지고 있는 이 연관관계를 데이터베이스의 컬럼과 매핑하는 어노테이션이다. 즉, 자바의 Job 과 데이터베이스의 job_id를 매핑해준다.
이 어노테이션을 생략하면 [필드명]_[컬럼명]을 사용해서 자동으로 매핑해준다. 즉 job_id로 자동으로 매핑해준다.
양방향 매핑
두 개의 엔티티의 매핑은 단방향 매핑만 존재하는 것이 아니다. 두 테이블이 서로 연관관계를 가지는 양방향 매핑이 존재한다.
단방향 매핑에서는 외래키를 가지는 테이블과 매핑되는 엔티티에서 연관관계를 가지고 있었다. 그래서 member.getJob()이 가능했다. 하지만 member join job, job join member가 모두 가능한 데이터베이스 테이블에 비해서는 서로 참조가 자유롭지 못했다. 양방향 매핑에서는 job에서도 member에 접근할 수 있는 연관관계를 관리한다.
member : job은 다 대 일 관계였다. 따라서 Member 엔티티에서는 @ManyToOne으로 연관관계를 매핑했었다. 그렇다면 Job에서는 반대로 @OneToMany로 매핑하게 된다. 그리고 하나의 Job이 여러 개의 member를 가질 수 있기 때문에 Member를 List, Map, Set등의 컬렉션으로 저장하게 된다. 따라서 Job에서는 아래와 같이 연관관계를 관리한다.
@OneToMany
private List<Member> members = new ArrayList<Member>();연관관계의 주인
양방향 매핑은 사실상 하나의 연관관계가 양쪽을 이어준다고 볼 수는 없다. 두 개의 단방향 연관관계가 하나의 양방향 연관관계처럼 보일 뿐이다. 그렇다면 이 두 개의 단방향 연관관계를 데이터베이스와 어떻게 매핑 시킬까?
방법은 연관관계의 주인을 설정함으로써 그 주인을 기준으로 매핑한다. 보통은 ManyToOne 어노테이션이 붙은 필드가 연관관계의 주인이자 외래키와 매핑되는 필드가 된다. 그리고 실제 컬럼이 존재하지 않는 반대쪽의 필드에는 연관관계의 주인이 아니라는 뜻으로 mappedBy라는 속성을 연관관계 어노테이션에 붙인다.
@ManyToOne
private Job job;
-------------------
@OneToMay(mappedBy = "job")
private List<Member> members = new ArrayList<Member>();
이와 같이 매핑하게 되면 연관관계의 주인은 job이라는 필드가 되고, 데이터베이스의 job_id와 매핑된다. 그리고 members 필드에는 mappedBy 속성을 붙여 job이라는 연관관계의 주인과 매핑해준다.
양방향 매핑 시 주의할 점
이와 같이 양방향 매핑을 함에 있어서 주의할 점이 있다. 우리는 데이터베이스와의 매핑은 신경쓰지 않고 JPA가 알아서 처리해준다. 하지만 데이터베이스의 데이터를 객체로 핸들링하기 때문에 객체의 데이터 무결성에 대해서는 주의하여야 한다. 특히 양방향 매핑에서 흔히 발생하는 실수들이 있다.
name = developer인 job과 name = engineer인 job이 있다고 하자. name = jaeseok-go인 member의 job이 developer라고 하자.
Job job1 = new Job("developer", 1000);
Job job2 = new Job("engineer", 900);
Member member = new Member("jaeseok-go", job1);
job1.members.add(member);
em.persist(job1);
em.persist(job2);
em.persist(member);
위와 같이 developer와 jaeseok-go는 양방향 매핑이 되었다. 여기서 job이 engineer로 바뀐다고 생각해보자. 연관관계의 주인은 member.job이기 때문에 member.job의 객체를 바꿔주면 양방향 매핑이 바뀐다.
member.job = job2;
job2.members.add(member);
em.persist(member);
em.persist(job2);하지만 위의 코드를 보면 job2의 members에도 member 객체를 추가해주었다. 추가를 안한다고 하더라도 양방향 매핑이 안되는 것은 아니다. JPA는 연관관계의 주인을 기준으로 매핑을하고 데이터 무결성을 보장한다. 하지만 연관관계의 주인이 아닌 곳을 신경쓰지 않는다면 객체 상태의 연산 중에 에러가 발생할 수 있다. 객체의 무결성은 개발자가 직접 신경써야하는 부분이다.
하지만 위의 코드로 객체가 무결하다고 볼 수 없다. 왜냐하면 아직 job1은 member를 가지고 있기 때문이다. 따라서 job1의 members의 객체를 삭제해줘야 한다.
job1.members.remove(member);이러한 작업들이 job2를 member에 set하는 과정이다. 이를 하나의 setter method로 구현할 수 있다. 이를 연관관계 편의 메소드라고 한다.
public void setJob(Job job){
if (this.job != null){
this.job.getMembers().remove(this);
}
this.job = job;
job.getMembers().add(this);
}
---------------------
member.setJob(job2);
em.persist(member);
em.persist(job1);
em.persist(job2);위와 같은 연관관계 편의 메소드를 작성해서 코드가 훨씬 깔끔해졌고 실수를 줄일 수 있다.
다양한 매핑 기법
지금까지는 다대일의 단방향/양방향 매핑을 알아보았다. 그렇다면 일대일, 일대다, 다대다에서 단방향/양방향 매핑을 불가능한 것일까? 차례대로 한번 짚어보자.
일대일 단방향/양방향 매핑
일대일 관계에서는 두 테이블 어느 곳이든 외래키를 가질 수 있다. 두 개의 테이블을 주 테이블과 대상 테이블로 구분한다.
객체 지향 관점의 개발자는 주 테이블에 외래키를 두어 객체 그래프 탐색으로 주 테이블에서 대상 테이블을 쉽게 참조할 수 있게 설계하는 것을 선호한다.
반대로 데이터베이스 관점의 개발자는 대상 테이블에 외래키를 두어 명확하게 테이블을 구성한다. 즉 일대다 관계가 되더라도 수정할 필요가 없다.
어느 곳에서 외래키를 관리하던 외래키를 관리하는 곳에서 연관관계 매핑을 수행하면 된다. 단방향 매핑의 경우에는 외래키가 없는 곳에서 연관관계의 주인이 되어 반대편의 외래키를 관리하고자 한다고 하더라도 이를 지원하는 방법이 없다.
일대다 단방향 매핑
일대다 매핑은 다쪽의 외래키를 일쪽의 필드에서 컬렉션으로 매핑한다.
@OnetoMany
@JoinColumn(name = "job_id")
private List<Member> members = new ArrayList<>();이와 같이 member테이블의 job_id라는 외래키를 member 엔티티에서 매핑한다.
이와 같은 경우에는 외래키가 다른 테이블에 있기 때문에 쿼리의 성능이 떨어진다. 아래의 코드를 보고 쿼리의 성능을 가늠해보자.
Member member1 = new Member("jaeseok-go");
Member member2 = new Member("minsu-kim");
Job job = new Job("developer");
job.members.add(member1);
job.members.add(member2);
em.persist(member1);
em.persist(member2);
em.persist(job);
transaction.commit();
-- ID : 1
INSERT INTO MEMBER(NAME)
VALUES ("jaeseok-go");
-- ID : 2
INSERT INTO MEMBER(NAME)
VALUES ("minsu-kim");
-- ID :1
INSERT INTO JOB(NAME)
VALUES ("developer");
UPDATE MEMBER
SET JOB_ID = 1
WHERE ID = 1;
UPDATE MEMBER
SET JOB_ID = 1
WHERE ID = 2;다대일 매핑이었다면 3개의 쿼리로 위의 작업이 모두 수행되었을 것이다. 하지만 JOB_ID 외래키를 관리하는 게 members라는 반대쪽 엔티티의 필드이기 때문에 두 개의 update문이 더 발생했다.
따라서 일대다 단방향 매핑은 왠만하면 지양하고,컬렉션 필드를 꼭 가지고 싶다면 다대일 양방향 매핑을 사용하자.
일대다 양방향 매핑
일대다 단방향 매핑 역시 깔끔하게 사용하기는 힘들다. 일단 @ManyToOne에 mappedBy 속성이 아예 없다. 굳이 이 매핑을 사용하는 방법은 @ManyToOne에 읽기전용 필드를 하나 만들어서 이를 매핑해주는 방법이다. 하지만 이 역시 일대다 단방향 매핑과 마찬가지로 성능저하를 불러일으킨다.
왠만하면.. 일대다 매핑보다는 다대일 양방향 매핑을 사용하자!!
다대다 단방향/양방향 매핑
우선 다대다 매핑은 관계형 데이터베이스에서 그대로 구현할 수 없다. 따라서 보통은 관계 테이블을 하나 추가해서 이를 활용한다.
예를 들어서 회원 테이블과 상품 테이블이 있다고 생각해보자. 회원은 여러 개의 상품을 구매하고 각 상품은 여러 명의 회원들이 구매한다. 그럼 테이블을 어떻게 구성할 수 있을까?
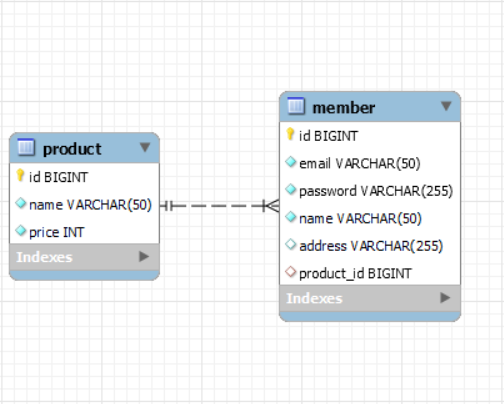
위와 같이 member에 product_id를 넣으면 될까? 이러면 하나의 상품을 여러 명의 회원이 구매하는 것으로 보일 수 있겠지만 여러 상품을 한 명의 회원이 구매하는 것은 구현하기 어려워보인다.
그렇다면 반대도 마찬가지일 것이다. 그래서 보통은 아래와 같이 이 두 개의 테이블 사이에 관계 테이블을 추가한다.
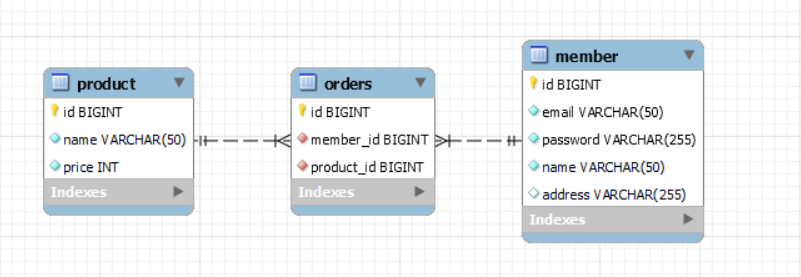
그렇다면 엔티티와 연관관계는 어떻게 매핑할까?
크게 두 가지로 구분된다. 첫 번째는 3개의 엔티티를 만들어서 다대일 연관관계 두 개를 주문 테이블에 매핑하는 것이다. 이 방법이 가장 권장되는 방법이다.
두 번재로는 JPA에서 지원하는 다대다 연관관계 매핑을 하는 것이다. 이 방법은 관계 테이블을 생략하고 두 개의 테이블로 연관관계를 매핑할 수 있다.
@Entity
public class Member {
@Id
@Column(name = "id")
private Long id;
private String email;
private String password;
private String name;
@Column(nullable = true)
private String address;
@ManyToMany
@JoinTable(name = "orders",
joinColumns = @JoinColumn(name = "member_id"),
inverseJoinDolumns = @JoinColumn(name = "product_id"))
private List<Product> products = new ArrayList<Product>();
}위와 같은 코드로 단방향 매핑을 할 수 있다. 양방향 매핑을 하고 싶다면 반대쪽 엔티티에 @ManyToMany(mappedBy = "products")를 붙여주기만 하면 된다.
이렇게 편리한 다대다 매핑보다 왜 다대일 매핑을 여러 개 만드는 것이 더 권장되는 방법일까? 그것은 관계 테이블에 단순히 매핑 정보만 담기지 않기 때문이다.
위와 같은 경우에만 해도 주문 테이블에 상품 주문량이나 주문 일자 등 다양한 컬럼이 추가되어서 관리될 수 있다. 하지만 다대다 매핑은 관계 테이블자체를 생략하고 매핑을 하기 때문에 권장되지 않는 것이다.
