쿼리 튜닝과 필요성
DB 기반 시스템에서의 DB관련 성능저하의 비율은 70% 이상이다. 그만큼 DB 설계 및 쿼리 단계에서 성능을 고려하지 못하는 경우가 발생하기 쉽고, 이를 기술적으로 해결해나가는 것이 중요하다.
이처럼 DB 쿼리의 성능저하 이슈를 해결하는 작업을 쿼리 튜닝이라고 한다.
데이터베이스 메모리 구조
 출처 : http://dbcafe.co.kr/wiki/index.php/SGA_%EC%99%80_PGA
출처 : http://dbcafe.co.kr/wiki/index.php/SGA_%EC%99%80_PGA
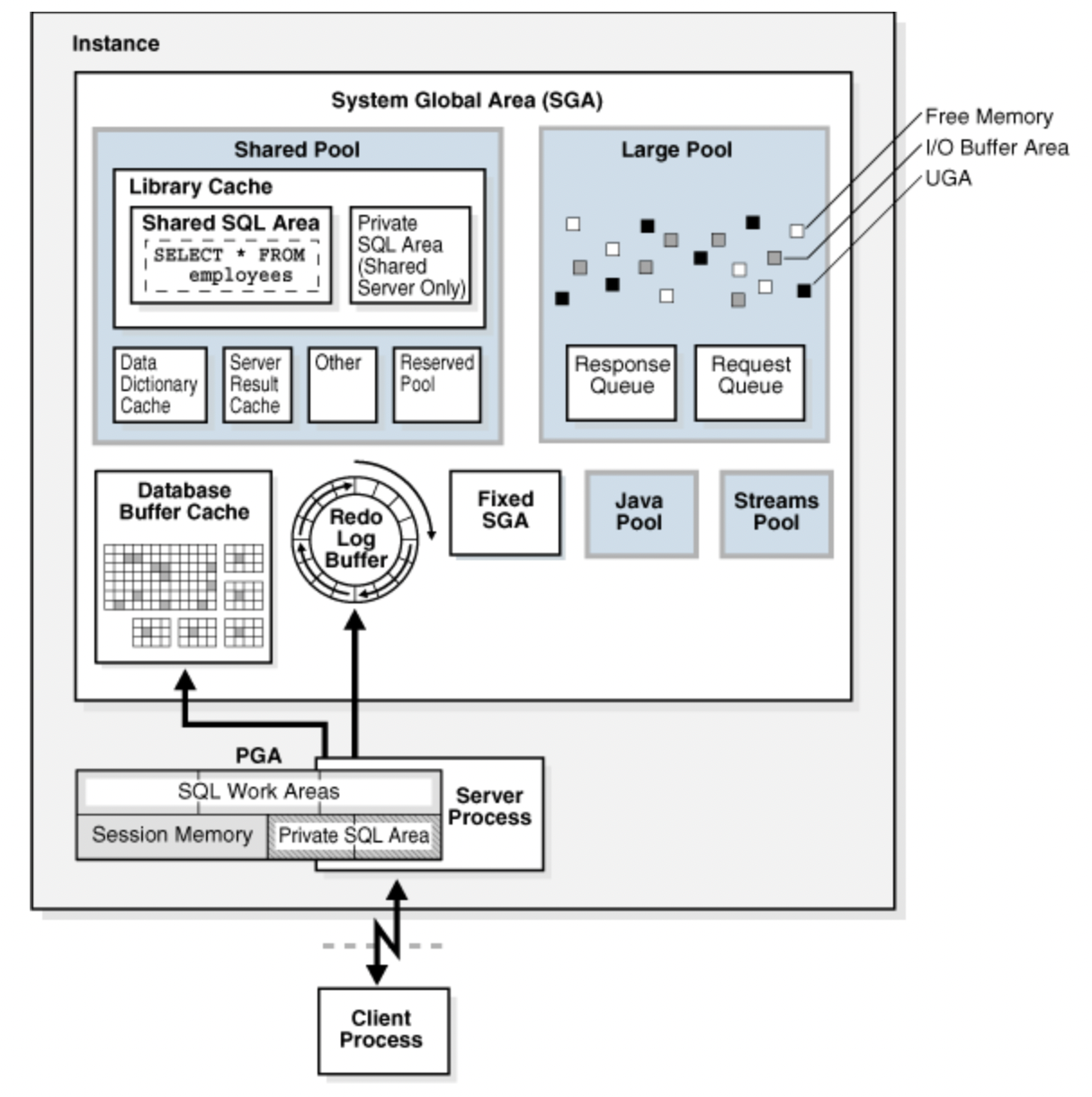
위의 그림은 오라클 기반의 DB 메모리 구조를 표현한 그림이다.
메모리는 크게 PGA와 SGA로 구분되는데, PGA는 Client Session, SQL 처리 메모리, Sorting 메모리 등을 포함하며 관리한다. 이러한 PGA는 Client Connection마다 하나씩 할당되는 영역이다.
SGA는 Shared Pool, DB Buffer Cache, Redo Log Buffer 등을 가지며 모든 사용자가 공유하는 영역이다.
메모리 리소스들의 자세한 역할은 아래의 SQL문 처리 과정을 보며 이해해보자.
SQL문 처리 과정
Client side에서 SQL문을 실행하는 경우 아래와 같은 과정을 통해 SQL문이 실행된다.
parse (구문분석) - bind (바인드) - execute (실행) - fetch (인출)
1. parse
구문분석 과정에서는 전달받은 SQL로 컴파일 코드와 실행 계획을 만들어서 Shared Pool에 저장하는 과정이다. parse과정은 아래의 순서로 진행된다.
1) SQL문의 구문을 체크한다. (select, from, where 등)
2) table/column의 권한/보안정책을 체크한다.
3) parse tree (컴파일 코드)를 생성하고 Shared Pool에 저장한다.
4) Optimizer가 어떤 수행방법이 빠른 방법인지 검토한다.
5) 실행 계획을 만들어서 Shared Pool에 저장한다.
사실 위의 과정에서 한 가지 빠진 과정이 있는데, 이는 Shared Pool에 현재 전달받은 쿼리가 존재하는지 검증하는 과정이다.
이 과정에서는 입력받은 쿼리를 ascii code로 바꾸어서 모든 값의 합계를 구한다. Shared Pool에 존재하는 쿼리와 입력받은 쿼리의 합계가 다른 경우는 다른 쿼리로 판별하고, 같은 경우의 쿼리만 비교해서 직접 검증한다.
만약 입력받은 쿼리가 이미 직전에 입력받은 쿼리여서 Shared Pool에 존재하는 쿼리라면 3~5번 과정은 생략한다.
이렇게 생략하는 것을 soft parse라고 하며, 반대로 모든 과정을 수행하는 과정을 hard parse라고 한다.
hard parse보다 soft parse를 지향하는 쿼리가 더 성능이 좋은 쿼리이므로, 정해진 작성룰에 맞춰 쿼리를 작성하는 것이 좋다.
(빈 칸, 공백 등의 사소한 차이도 다른 쿼리로 인식)
2. bind
Shared Pool에 작성된 parse tree에 변수가 존재한다면 그 값을 바인딩하는 과정이다. 변수가 없는 경우에는 다음 단계로 넘어간다.
3. execute
실행과정은 실행계획을 적용하는 과정이다.
select문의 경우 아래와 같은 과정으로 실행과정이 실행된다.
- DB Buffer Cache에 데이터가 있는지 확인한다.
- 데이터가 없다면, data file에서 필요한 data block을 Cache로 가져온다.
update문의 경우 아래와 같은 과정으로 실행과정이 실행된다.
- DB Buffer Cache에 데이터가 있는지 확인한다.
- 데이터가 없다면, data file에서 필요한 data block을 Cache로 가져온다.
- 데이터가 없다면, Undo Block을 할당받아서 Cache로 Copy한다.
- 새로운 데이터와 예전 데이터를 Redo Log Buffer에 저장한다.
- Undo Segment의 Undo Block에 예전 데이터를 저장한다.
- Cache의 Data Block에 새로운 데이터를 update한다.
4. fetch
인출과정은 select문의 경우에만 수행되는 과정이다. DB Buffer Cache에 있는 요청 데이터를 Array Size 만큼 반복하여 인출하는 과정이다. 받은 데이터를 PGA에서 Sorting작업을 수행한다.
옵티마이저
옵티마이저란 SQL문 parse 과정에서 실행 계획을 만들어 내는 최적화 리소스이다. 이 때 만들어진 실행계획을 가지고 얼마나 최적화된 경로로 데이터를 조회할지 결정하기 때문에, 성능을 결정하는 매우 중요한 요소이다. 옵티마이저가 보다 최적화된 실행계획을 만들어내게 유도함으로써 쿼리 튜닝을 수행할 수 있다.
이와 같은 옵티마이저가 만들어낸 실행계획을 아래와 같이 확인해보자.
 개인환경에서는 oracle을 준비하지 못해 mysql로 실행계획을 확인해보았다.
개인환경에서는 oracle을 준비하지 못해 mysql로 실행계획을 확인해보았다.
실행계획에서는 해당 쿼리가 어떤 타입인지, 어떤 인덱스를 사용하는지, 몇 줄의 데이터를 검색하는지 등의 데이터를 가지고 있다. 이와 같은 정보들을 활용해 현재 쿼리의 성능이 나쁜 원인을 분석해서 더 나은 쿼리를 만들어 내거나, 인덱스와 같은 자료구조를 수정해서 성능을 개선하는 작업을 수행할 수 있다.
