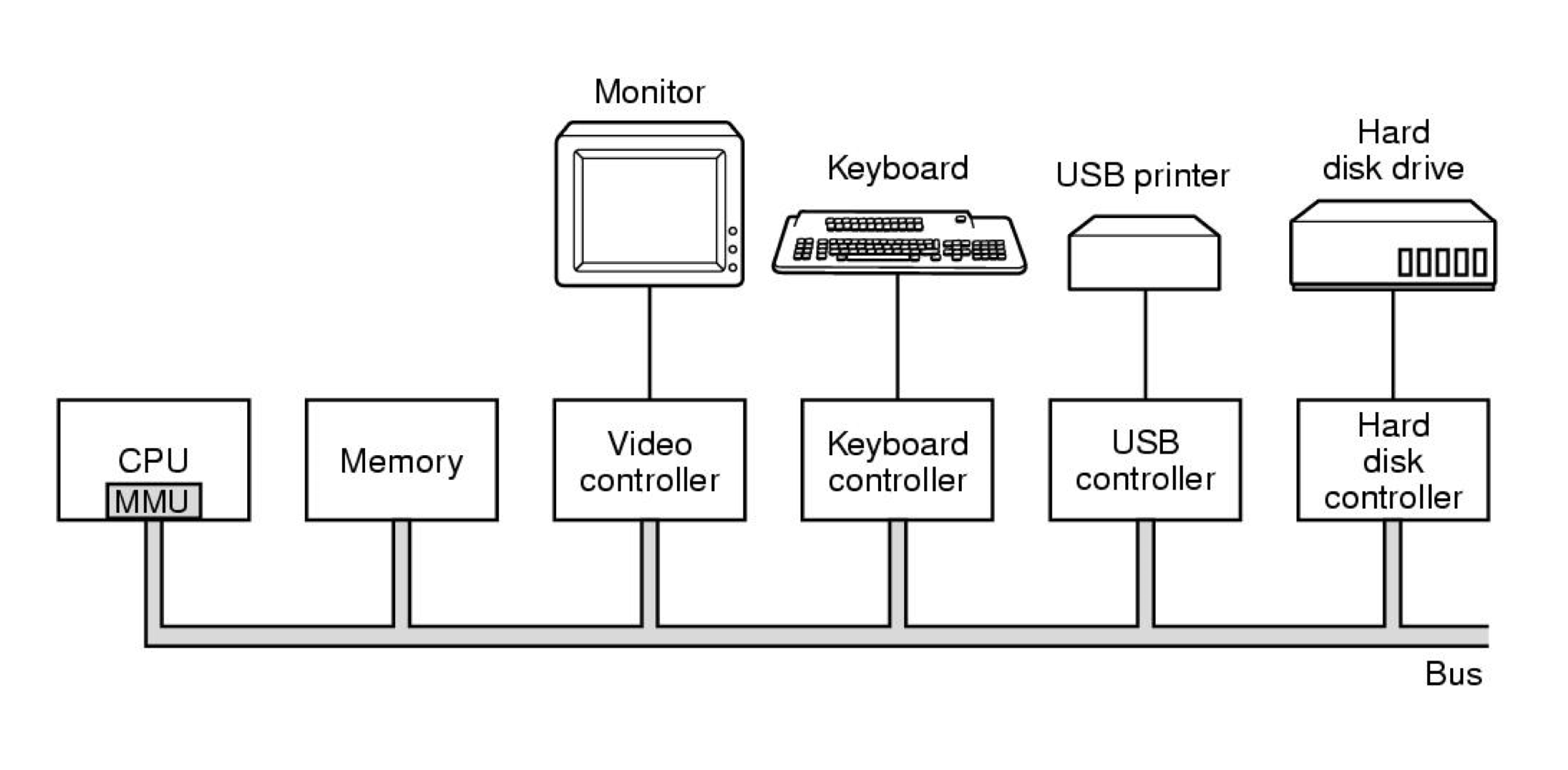
✏️ 현대 컴퓨터의 구조
- 하나 이상의 processor (CPU)
- Main memory (DRAM)
- Storage (Disk)
각 컴포넌트는 버스를 통해서 연결된다.
✏️ CPU
■ 특징
- 항상 다음 명령을 실행한다.
- 실행할 명령이 없으면 루프를 돈다.
- CPU는 메모리만 상대한다.
CPU는 2개의 모드를 가지고 있다.
1. User Mode: 입출력 명령 실행 불가
2. Kernel Mode: 입출력 명령 실행 가능
■ 구성요소
CPU는 다음과 같은 요소로 구성된다.
- PC: Program Counter
- IR: Instruction Register
- MAR: Memory Address Register
- MBR: Memory Buffer Register
- I/O AR: I/O Address Register
- I/O BR: I/O Buffer Register
메모리에 Read/Wrtie - MAR,MBR 사용
입출력 장치에 Read/Write - I/O AR, BR 사용
■ CPU ↔︎ 입출력 장치
CPU는 I/O Device와 어떻게 상호작용 하는가?
2가지 방식이 존재한다.
- Memory Mapped I/O:
메모리와 입출력 장치의 주소를 구분하지 않음
메모리 주소의 일부분을 I/O Register에 부여한다.
CPU는 마치 메모리에 접근하는 것과 똑같이 입출력 장치에 접근한다.
- I/O Mapped I/O:
메모리와 입출력 장치의 주소를 구분함
I/O Register에 접근하는 명령어가 별도로 존재한다.
입출력을 하기 위해서는 별도의 주소 입력 버스를 사용해야 한다.
■ Register의 종류
- User-Visible Registers
프로그래머가 제어할 수 있는 Register이다.
모든 프로그램이 사용 가능하다.
Data, Address, Index, Segment Pointer, Stack Pointer 등
- User-Invisible Registers
CPU의 Control 연산을 위해 사용되는 Register이다.
PC, IR, PSW(Program Ststus Word Register/Flag Register: 현재 CPU가 커널 모드인지 유저 모드인지) 등
■ CPU의 속도를 높이자
Pipelining
- Fetch - Decode - Execute 의 과정을 병렬로 작업함
ex) 1번 라인 Fetch
1번 Decode 하는 동안 2번 Fetch
1번 Execute 하는 동안 2번 Decode, 3번 Fetch
➜3배 빨라짐
하지만, 점프 명령을 만나면 무용지물
【 해결 - 파이프라이닝 2개 】
하나는 점프 만나는거 예상해서 파이프라이닝
하나는 순차적으로 파이프라이닝
하지만, 보안 문제가 발생할 수 있다.
【 해결 - Super Scalar 】
여러개 명령을 한꺼번에 실행
더이상 어떻게 빠르게 만들어? -> Multicore & Multithread
더 빠르게? -> L2 캐시를 공유하지말고, 각 코어마다 L2 캐시를 가지자
■ Interrupt
Interrupt는 Processor의 수행 순서를 제어하는 방법이다.
Interrupt가 없다면?
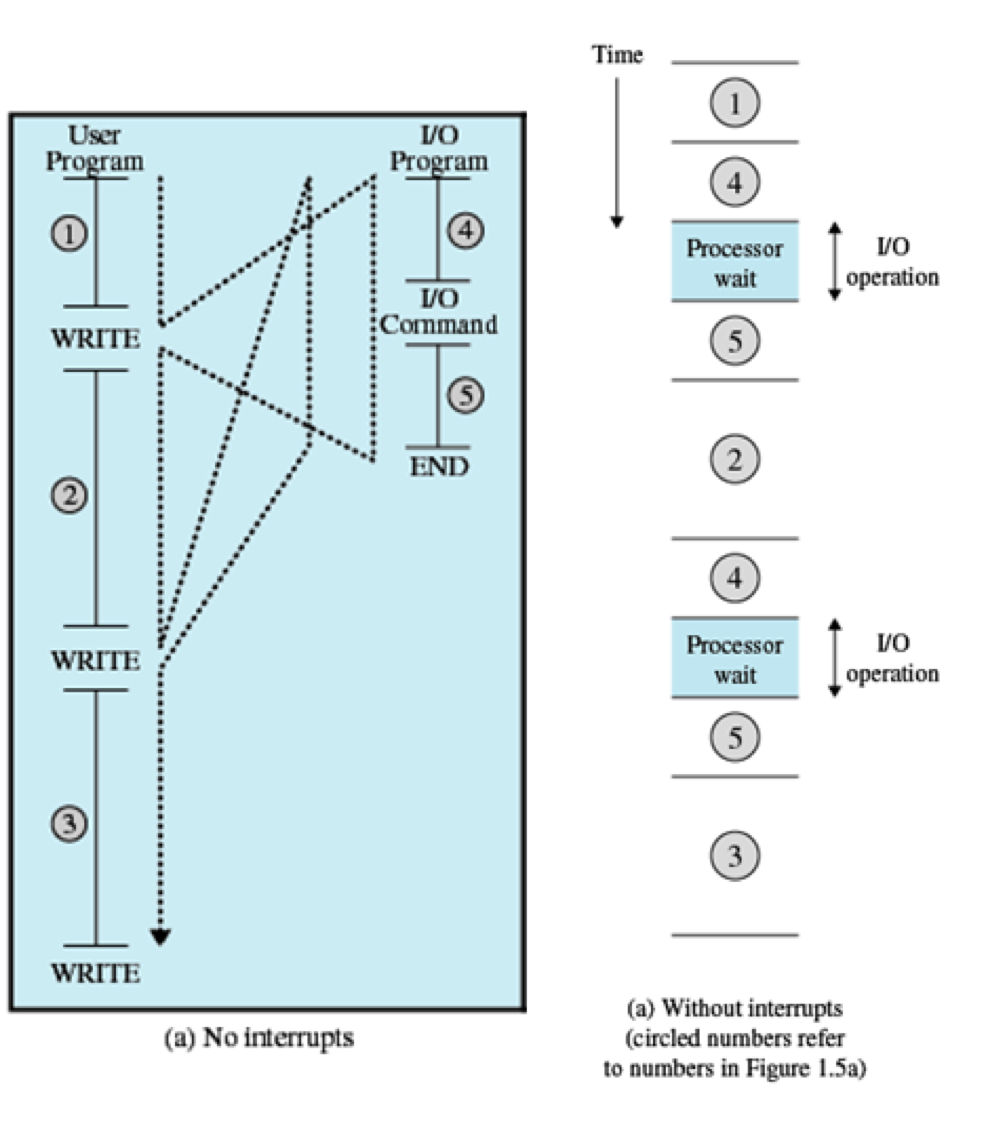
1번 작업을 수행하는 도중 Write 요청 발생
➜ 4번: 입출력 실행
➜ 대기
➜ 5번: 입출력 결과 가져오기
➜ 다시 2번 작업을 수행하러 옴
매우 비효율적이다!!
Interrupt를 사용한다면
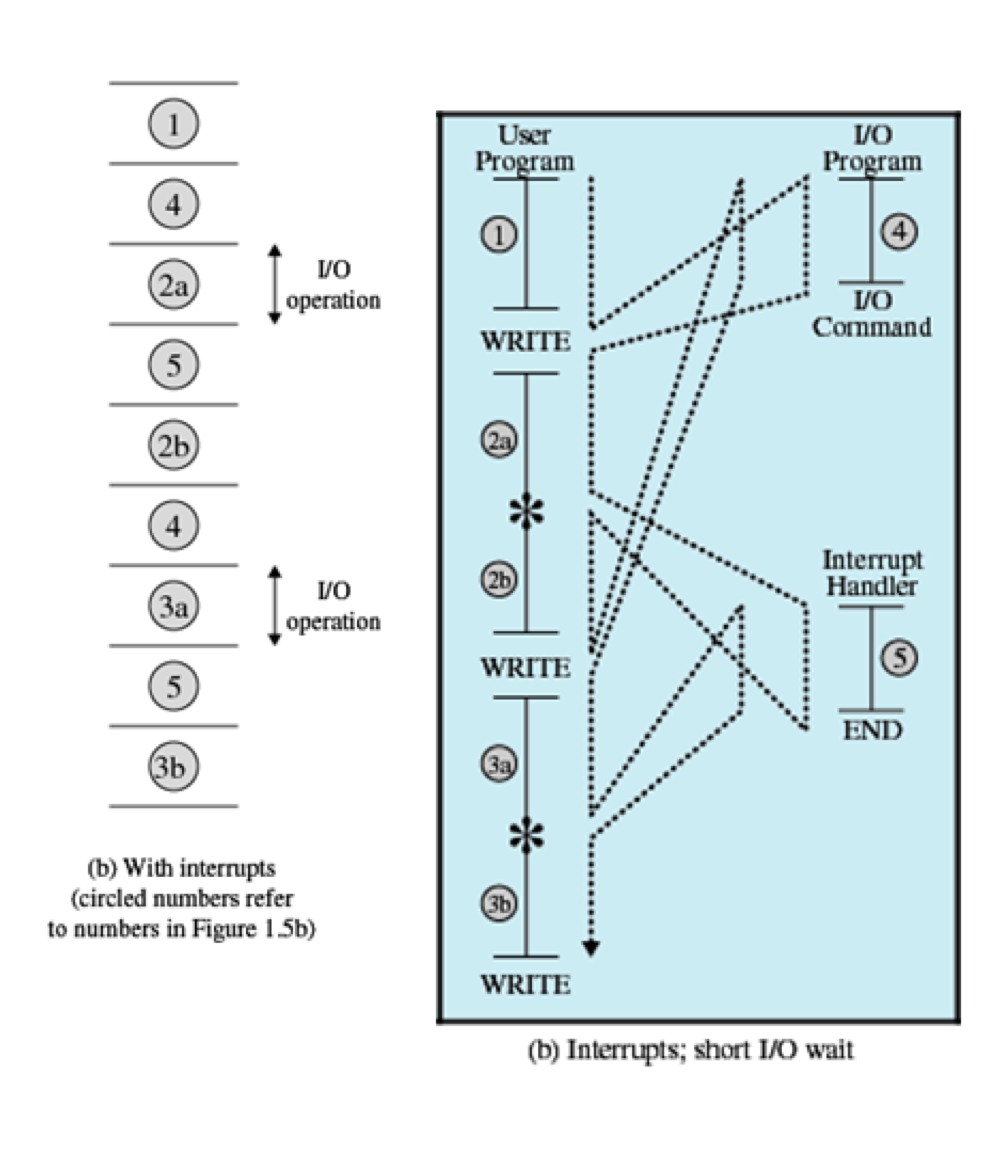
1번 작업을 수행하는 도중 Write 요청 발생
➜ 자기 자신에게 Interrupt 걸음
➜ 4번: 입출력 실행
➜ 다시 2번 작업을 수행하러 옴
➜ 5번: 입출력 결과 가져오기
➜ 2번 작업 마무리
대기 시간이 없어졌다.
OS에는 Interrupt Handler가 존재한다.
CPU가 User Program을 실행하는 중에 Interrupts 발생 (ex 키보드 인터럽트)
하고 있던 명령(i)을 마친 뒤에, Interrupt Handler로 점프 후 처리
다시 다음 명령(i+1)으로 점프 한 뒤에 계속하기
-
Programmed I/O
처리가 끝날 때까지 CPU가 기다림 -
Interrupt-driven I/O
인터럽트가 걸리면 실행 한 뒤에 다시 자기 할 일 함.
실행이 끝났다는 인터럽트가 걸리면 결과물만 가져옴
Interrupt의 실행 주체는 OS가 아니다.
운영체제는 코드 데이터를 빌려주는 것 뿐이다.
주체는 프로세스이다.
이러한 하드웨어를 사람이 직접 관리할 수 없으므로 OS(Operating System)가 대신 관리한다.
운영체제는 하드웨어를 감싸고 있다.
마우스로 앱을 클릭하는 것은 운영체제가 처리하지 않는다.
응용 프로그램인 GUI가 처리하는 것이다.
GUI가 System call 형태로 운영체제에게 부탁을 하면 운영체제가 프로그램을 실행시켜준다.
✏️ Memory
■ 특징
- CPU 보다는 느리지만, DISK보다는 빠르다.
- 바이트 단위로 입출력한다.
- 전기가 나가면 정보가 없어진다. (휘발성)
■ Memory의 종류
| 휘발성 Memory | 비 휘발성 Memory |
|---|---|
| DRAM(Main Memory) | Magnetic Disk |
| CPU 내부의 Register | Magnetic Tape |
| CPU 내부의 Cache |
■ Cache Memory
앞서 말했듯이, CPU는 Main Memory만 상대한다.
CPU는 Main Memory보다 훨씬 빠르다.
둘의 속도 차이를 어떻게 극복할 수 있을까?
➜ CPU 칩 안에서 Cache Memory를 사용하자.
Cache는 다음과 같이 구성된다.
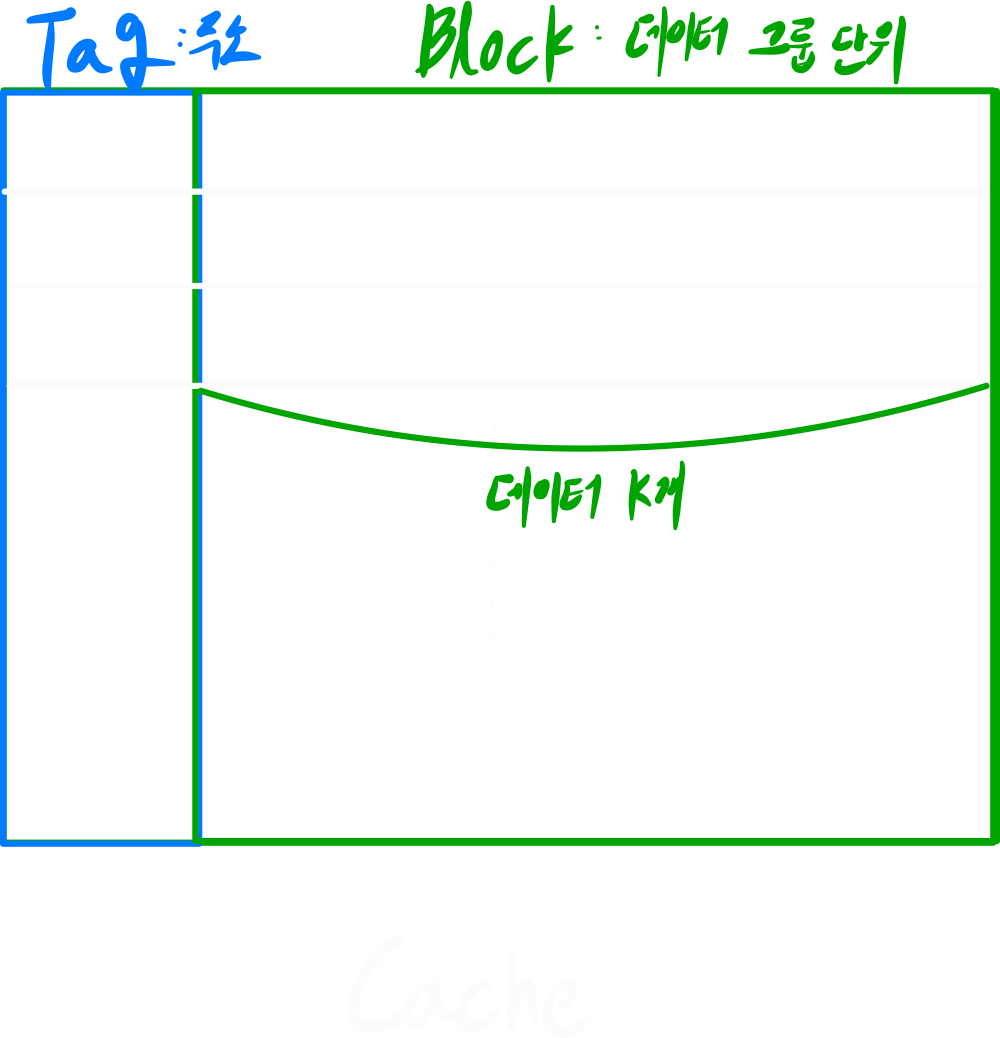
Cache의 고려사항
생각보다 Overhead가 크다.
- Size
- 언제 넣을 것인가?
- 어디에 넣을 것인가?
- Cache가 꽉차면 어떤 데이터를 대체할 것인가?
- 언제 Main Memory에 적을 것인가? (Write, Write Back)
Cache Memory의 동작 방식
Cache Memory를 탐색해서 있으면 가져오고, 없으면 DRAM에서 가져오자.
ex) 데이터 A (주소 3번)를 가져오고 싶다.
1. Cache Mememory 체크 (없음)
2. Main Memory의 3번 주위를 블록 단위로 가져와서 Cache에 넣음
Cache Memory를 탐색하는 방법
1. Fully Associative Mapping - 비교회로 n개
Main Memory에서 복사한 데이터 블록이 Cache의 어디에나 들어갈 수 있음
► 탐색 - 데이터 A (Memory Address: 00770)
모든 Tag를 다 비교해서 데이터를 찾아낸다.
Tag가 n개면, n번의 탐색이 필요하다.
2. Direct Mapping - 비교회로 1개
: Main Memory에서 복사한 각 데이터 블록이 특정 Cache 라인에만 들어갈 수 있음
ex) Main Memory의 Index가 00 으로 끝나는 데이터만 Cache의 0번 라인에 복사될 수 있다.► 탐색 - 데이터 A (Memory Address: 00770)
Memory Address % 100 가 Line Index와 일치해야지 저장될 수 있다고 가정하자.
CPU가 00770을 요구하면, 70번 Line만 체크하면 된다.
1번의 탐색이 필요하다.
Direct Mapping 방식은 탐색이 빠르지만, 저장할 수 있는 데이터 수가 작다는 단점이 있다.
3. Set Associative Mapping - 비교회로 2개
: Direct Mapping 방식을 2개 겹침
► 탐색 - 데이터 A (Memory Address: 00770)
Memory Address % 100 가 Line Index와 일치해야지 저장될 수 있다고 가정하자.
CPU가 00770을 요구하면, 첫번째 Cache의 70번 Line + 두번째 Cache의 70번 라인을 체크한다.
총 2번의 탐색이 필요하다.
Cache Memory의 hit rate
95% 이다.
Locality of Reference(특정 부분, 특정 타이밍에 가져올 확률)가 높기 때문에 상당히 높은편.
Average Access Time = 0.95 x 0.1 + 0.05 x (0.1 + 1) = 0.15 [us]
0.1: Cache Memory 접근 시간
1: DRAM Memory 접근 시간
✏️ Disk - HDD
■ 특징
- HDD(Hard Disk Drive) 는 보조기억 장치로, 섹터 단위로 입출력한다.
※ 섹터를 블록 단위로 관리함 - 전기가 나가도 정보가 보존된다.
- 충격에 약함
- 원판마다 헤드가 따로 있지 않고, 헤드는 하나의 봉으로 고정되어있음
✏️ 운영체제란 무엇인가?
운영체제는 위의 컴퓨터 구성요소들을 관리하는 시스템 소프트웨어이다.
- 응용 프로그램에게 시스템 서비스를 제공하기 위해 존재한다.
- 리소스 매니저의 역할도 한다.
■ 리소스 관리
-
CPU 관리: 여러 프로그램을 동시에 실행할 수 있도록 도와준다.
(실제로는 매우 빠른 시간동안 번갈아가면서 하나씩 실행) -
Memory 관리: 메모리를 보호한다.
-
입출력 장치 관리
-
Disk 관리
운영체제는 multiplexing으로 이러한 기능을 지원한다.
시간 단위 multiplexing: 프로그램 동시 실행
공간 단위 multiplexing: 공유 메모리 공간 관리
■ OS의 진실
운영체제는 특별한 장치가 아니다!
운영체제는 코드, 데이터, 힙, 스택으로 구성된 소프트웨어일 뿐이다.
프로그램을 실행시키면, 프로그램의 코드 데이터 힙 스택이 메모리에 저장된다.
그 위에 운영체제의 코드 데이터 힙 스택이 저장된다.
Interrupt가 걸리면 User Program에서 OS의 코드로 점프해서 인터럽트를 처리한다.
결국, 운영체제의 코드를 실행하는 것은 USER PROGRAM 자기 자신이다!!
✏️ 운영체제의 발전
1945~1955: Vacuum Tubes (진공관)
~65: 트랜지스터 & Batch System (고전 운영체제1)
~80: IC & Multiprogramming (고전 운영체제2)
~Present: PC
■ 고전 운영체제
1. Batch System
Batch System은 정해진 Program을 순차적으로 실행하는 시스템이다.
펀칭 카드(job Control 역할)를 끼워넣으면, OS가 해당 프로그램을 실행한다.
⚠️ 하나의 작업이 끝날 때 까지 다른 작업을 할 수 없다!
2. MultiProgramming
MultiProgramming이란 여러 개의 프로그램이 동시에 메모리에 로드되어 실행되는 방식이다.
실제로 여러 프로그램을 동시에 실행하는 것이 아니라, 매우 빠른 속도로 번갈아가며 실행하는 것이다.
Stack Pointer란 무엇인가?
시스템 콜과 인터럽트의 차이점은 무엇인가?
