✏️ UMA와 NUMA
■ UMA(Uniform Memory Access)
모든 프로세서가 메모리에 동일한 시간 안에 접근할 수 있는 구조
- 메모리 모듈, CPU 모듈이 따로 존재한다.
- 메모리 접근을 위해 네트워크 스위치를 사용하여, 특정 메모리 모듈로 라우팅한다.
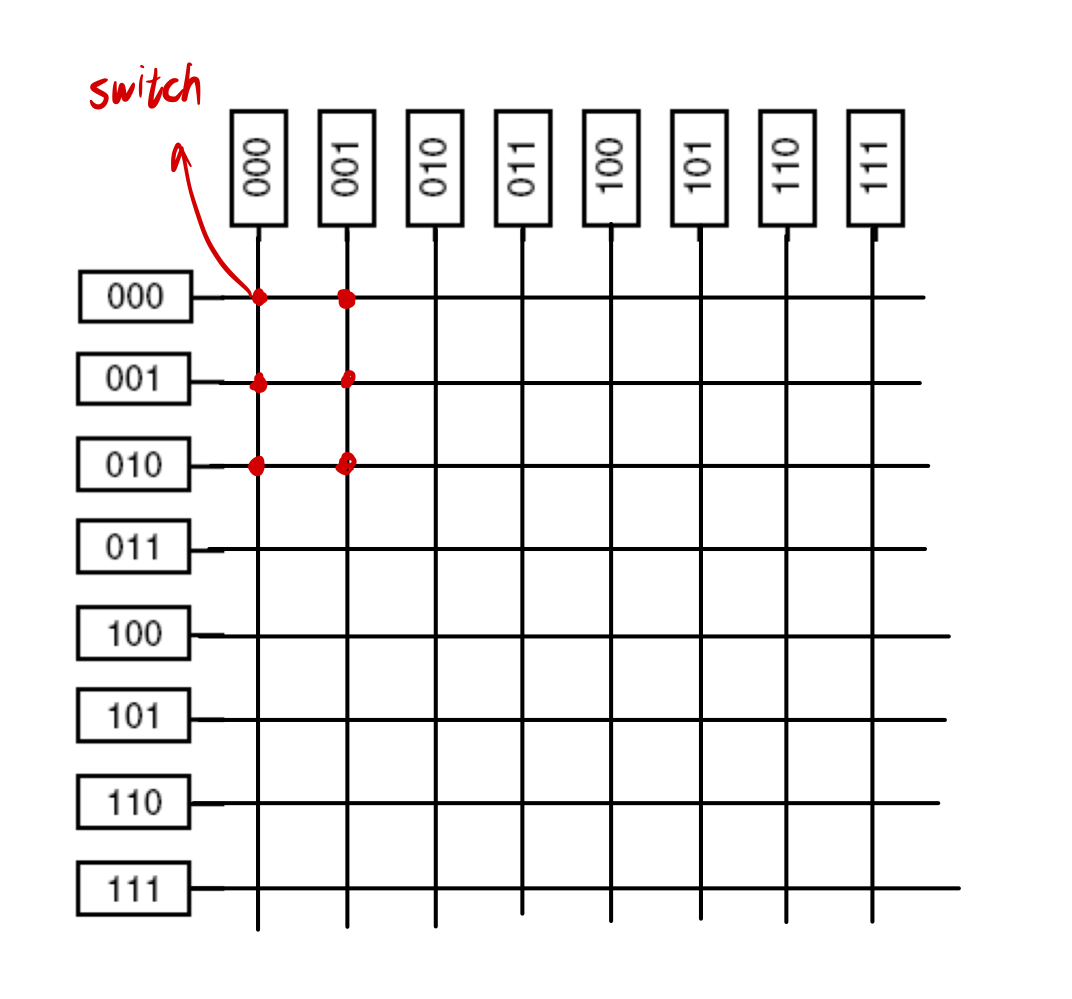
특정 CPU가 000 메모리 모듈에 액세스 요청을 보내는 경우
➜ 패킷을 보냄
➜ Network Switch가 000 메모리 모듈로 연결
스위치의 개수가 너무 많다는 단점이 존재한다!
∴ Omega Switching 방식을 사용한다.
Omega Switching
: 메모리 주소의 비트에 따라 스위치 경로를 동적으로 결정하여 효율적으로 트래픽을 관리하는 방식
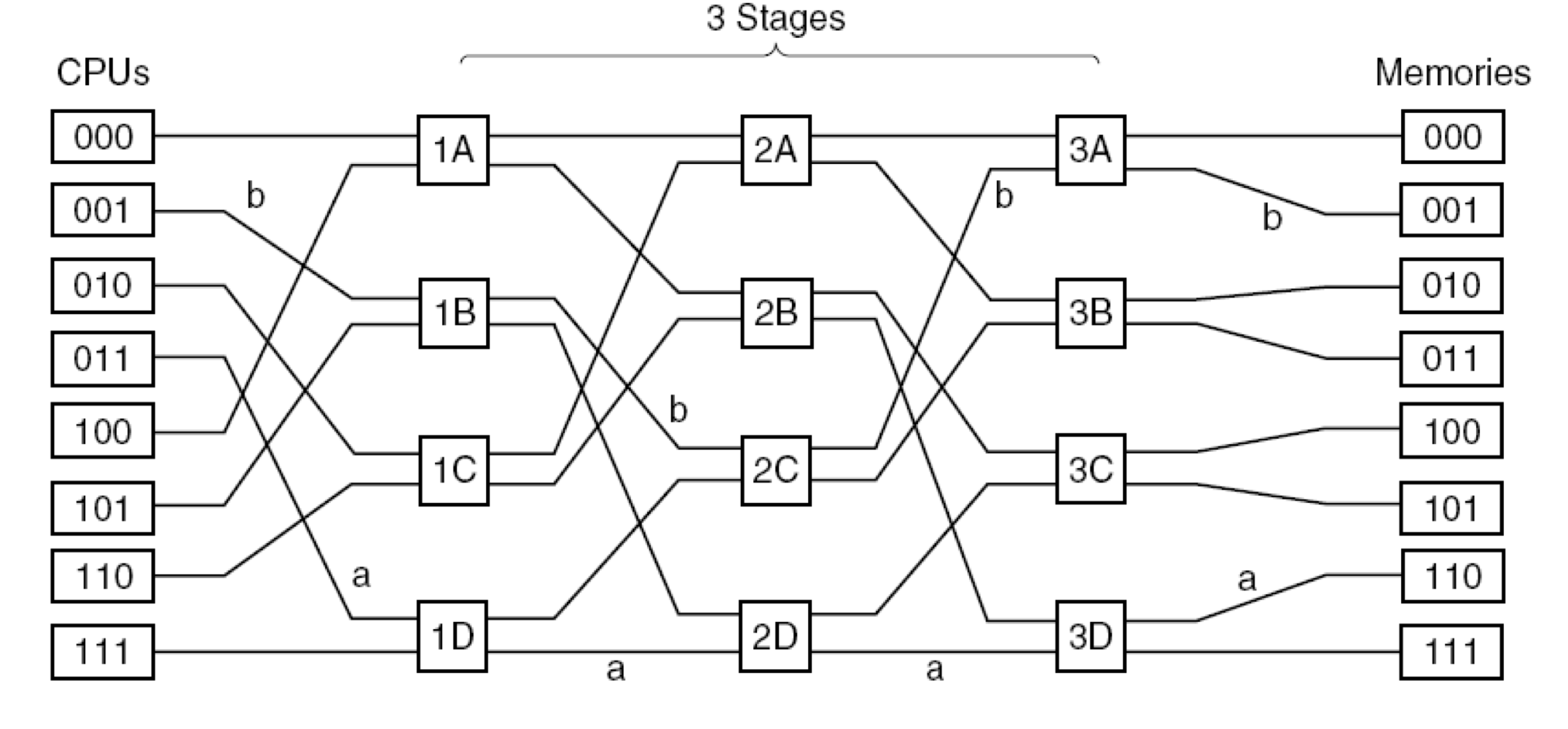
001번 CPU가 001 메모리에 액세스하는 경우
메모리의 첫 bit: 0 ➜ 스위치의 윗쪽으로
메모리의 첫 bit: 0 ➜ 스위치의 윗쪽으로
메모리의 첫 bit: 1 ➜ 스위치의 아래쪽으로
- 스위치 수를 획기적으로 줄일 수 있다!
■ NUMA
프로세서가 자신의 로컬 메모리에 빠르게 접근할 수 있으나, 다른 프로세서의 메모리에는 상대적으로 느리게 접근하는 구조
- 각 CPU는 Local Memory를 가지고 있음.
- Remote Memory에 Access할 때는
Load와store명령어를 사용한다. - Remote Memory에 Access하는 것은 상대적으로 느리다.
✏️ Multi-Processor System의 종류
1. Shared Memory Multi-Processor System
여러개의 코어가 하나의 메모리를 공유하는 시스템
-
붙일 수 있는 CPU의 한계가 있다. (메모리를 공유하기 때문에)
-
UMA와 NUMA 구조가 존재한다.
-
cache coherence logic을 사용한다.
: 각 프로세서에서 데이터를 캐싱, 다른 프로세서가 메모리를 수정할 경우 이를 감지하고 캐시를 업데이트- snooping 회로를 사용한다. (버스를 계속 감시)
- 다른 CPU가 메모리 write를 했을 때, 자신이 Caching하고 있다면 그 데이터를 없애버림
2. Distributed System
여러 컴퓨터가 인터넷을 통해 연결되어 독립적으로 작동하는 시스템
- Internet을 사용하기 때문에 상대적으로 느리다.
- 따라서, Inter-Connection Network를 사용하는 Message-Passing System을 사용하자.
3. Message-Passing Multi-Computer
각 컴퓨터(또는 프로세서)가 자신의 코어와 메모리를 갖고 있으며, 메시지 패싱을 통해 데이터를 교환하는 시스템
- 슈퍼 컴퓨터의 형태이다.
- Inter-Connection Network 사용
- Inter-Connection Network: 하드웨어적으로 구현한 Network
- NUMA 구조를 사용한다.
- CPU를 많이 붙일 수 있다.
✏️ OS for Multi-Processor
■ Separate OS for Each CPU
각 프로세서마다 독립적인 운영체제가 설치된 형태
■ Master-slave Model
하나의 CPU가 Master로 작동하며 시스템 호출 등을 처리하고, 나머지 Slave CPU는 사용자 프로그램 코드만 실행하는 형태
- Slave CPU는 사용자 프로그램 코드만 실행한다.
- 운영체제 코드는 Master CPU에서만 실행한다.
- User 프로세스가 slave CPU를 사용하다가 시스템 호출 발생
- 문맥 저장
- master cpu로 가서 실행
⚠️ 동시에 여러 CPU가 운영체제 코드를 사용하면 죽는다!
⚠️ Master CPU가 너무 바쁘다는 단점이 있다.
■ Symmetric Multiprocessors
모든 CPU가 운영체제 코드를 동시에 실행할 수 있으며, 데이터 접근 시 동기화를 위해 lock을 사용하는 형태
- 동시에 여러개 CPU가 운영체제 코드를 사용해도 상관없음
- 대신 데이터에 access할 때는 lock을 걸고 사용한다.
✏️ Synchronization
Test and Set Lock
: 특정 데이터를 독점적으로 사용하기 위해 데이터에 lock을 거는 방법.
- TSL 명령을 할 때는 버스에 lock 시그널을 뿌린다.
➜ 혼자 독점적으로 해당 메모리를 사용하게 한다.
TSL의 단점은 다음과 같다.
- 특정 CPU가 TSL 명령어를 호출하면 다른 CPU는 버스를 사용하지 못한다.
- lock 변수가 캐시에 저장되어 있을 때, 다른 CPU가 해당 변수를 수정하면 cache coherence logic에 의해 캐시된 값이 무효화되어야 한다.
위의 단점을 해결하기 위한 3가지 방식이 존재한다.
1. Revised TSL
버스를 독점하는 상황을 방지한다.
-
TSL은 lock 변수가 0이 될 때까지 TSL 명령어를 실행한다.
➜ 버스를 독점한다. -
Revised TSL은 lock 변수가 0이 될 때까지 check만 한다.
➜ 버스에 Lock 시그널을 뿌리지 않으므로 독점을 방지할 수 있다.
하지만, 여전히 cache coherence logic으로 인한 문제는 해결하지 못했다.
lock 변수를 캐싱하고 읽는다
➜ 다시 Test and Set을 시도해야 함
➜ Cache coherence logic 때문에 또 무효화 됨
2. Exponential backoff
lock 획득 실패 후 대기 시간을 점차적으로 늘려가며 다시 시도하는 방식
3. Private lock variable
lock 변수들을 Linked List로 구성하여 각 lock 변수가 다른 캐시 블록에 위치하도록 하는 방식
- lock 변수가 서로 다른 Cache Memory block에 저장된다
- 서로 다른 memory 위치에 존재하는 lock 변수이기 때문에, coherence logic이 작동하지 않는다.
- 1번 lock 변수 사용이 끝나면, linked list를 타고 다음 lock 변수를 free
✏️ Multi-Processor Scheduling
Multi-Processor에서 사용하는 스케줄링 방식은 3가지가 있다.
-
Time Sharing
: 모든 CPU가 하나의 Scheduling queue를 공유하는 방식 -
Space sharing
: 각 프로세스에게 CPU를 독립적으로 할당하는 방식 -
Gang Schedlung
: 한 프로세스의 스레드들을 동시에 실행하는 방식
■ Time Sharing
모든 CPU가 하나의 Scheduling queue를 공유하는 방식
각 CPU는 실행할 때마다 Scheduling queue에서 제일 높은 우선순위를 가진 프로세스를 실행헌다.
⚠️ CPU 개수가 많아지면 문제가 발생
➜ global queue에서 가져가는 것이 Bottle leck이 되기 때문(Lock을 걸어야 해서)
위의 문제를 해결하기 위해서 Two-level Scheduling을 사용한다.
- 하나의 global queue 와 각 CPU마다 local queue가 존재한다.
- CPU는 먼저 global queue에서 몇개를 꺼내와서 local queue에 매달아 놓고 실행한다.
- local queue가 다 비었을 때만 global queue에서 가져온다.
Two-Level Scheduling은 캐쉬 친화적이다!
Cache Affinity Scheduling
: 하나의 프로세스가 동일한 CPU에서 수행되도록 만드는 방식
ex) 프로세스 A가 0번 CPU 실행
➜ Time quantum이 끝나서 큐로 복귀
➜ 그 다음 Scheduling은 1번 CPU에서 실행됨
➜ 0번 CPU에 캐시가 존재하기 때문에, 좋지 않은 방식이다!
Two-level Scheduling을 사용하면 똑같은 CPU에서 실행되기 때문에 캐쉬 친화적이다.
■ Spcae Sharing
각 프로세스에게 CPU를 독립적으로 할당하는 방식
CPU의 수가 프로세스의 수와 유사해짐에 따라 각 프로세스에 독립적인 CPU를 할당.
- CPU들을 partition 단위로 나눈다.
- 각 partition을 프로세스에 할당한다.
ex) 8개의 CPU로 이루얻진 partition을 프로세스 A에게 할당
➜ A는 8개의 스레드를 만들어서 각 CPU한테 하나의 스레드 할당.
⚠️ CPU 개수가 많아지면, FCFS, round-robin 같은 스케줄링 알고리즘이 중요하지 않게 된다.
■ Gang Scheduling
한 프로세스의 스레드들을 동시에 실행하는 방식
- 한 프로그램의 모든 스레드를 한 번에 실행하거나 전혀 실행하지 않는다.
- 효율성이 좋다.
✏️ Multi-Computer
Multi-Processor(Shared Memory System)은 CPU 개수가 증가하면 Main Memory가 Bottle leck이 된다.
위의 문제를 해결하기 위해 Multi-Computer가 등장했다.
Multi-Computer
: 각 CPU가 자신의 코어와 독립된 메모리를 가지고, 메시지 패싱을 통해 데이터를 교환 (NUMA).
- Multi-Processor에서 발전된 방식이다.
- Inter-Connection Network를 사용한다.
- Inter-Connection Network를 사용하지 않으면 Distributed system이라 부른다.
■ Hardware
Multicomputer의 하드웨어 구조를 알아보자.
1. Inter-Connection Network
- 슈퍼 컴퓨터를 만드는 방식이다.
- 초기에는 버스, 링을 사용했으나, 라인 하나가 끊어지면 다 먹통이 되는 단점이 있었다.
➜ 그리드, 큐브 형태로 발전했다. - Store & Forward 형식으로 패킷을 전달한다.
2. Network Interface
- Multi-Computer의 각 노드들은 서로 데이터를 주고받을 수 있는 네트워크에 연결되어 있다.
- 데이터 전송 과정에서 발생하는 복사 작업으로 인한 오버헤드가 크다.
■ Software
1. Blocking & Nonblocking
송신측은 4가지 방식 중 하나를 선택할 수 있다.
| Send | 설명 |
|---|---|
| Blocking Send | 메시지를 전송하는 동안 송신자가 다른 작업을 수행하지 못하고 대기 |
| Nonblocking send with Copy | 송신자가 메시지를 전송 요청 후 즉시 다른 작업 수행 메시지가 복사되어 시스템의 버퍼에 저장된다. |
| Nonblocking send with Interrupt | 송신자가 메시지를 전송 요청 후 즉시 다른 작업 수행 메시지 전송이 끝나면 시스템이 인터럽트를 걸어준다. |
| Copy On Write | 데이터를 복사할 필요가 있는 경우에만 실제로 복사를 수행하는 기술 |
2. Remote Procedure Call
네트워크를 통해 다른 컴퓨터에 있는 함수를 마치 로컬 컴퓨터에 존재하는 것처럼 호출할 수 있게 해주는 프로토콜 또는 기술
- RPC는 IPC 방법의 한 종류이다.
- 리모트에 존재하는 객체를 호출할 수도 있는데, 이는 Object Request Broker(ORB)라 부른다.
3. Distributed Shared Memory
RPC 보다는 DSM이 선호된다.
DSM (Distributed Shared Memory)
각각의 CPU에 존재하는 local Memory를 합쳐서 virtual global Memory를 구현하는 기술
- 하드웨어 레벨, 운영체제 레벨, 라이브러리 레벨에서 구현이 가능하다.
- 자신의 컴퓨터에 존재하지 않는 메모리 영역에도 접근할 수 있다.
- 자신에게 없는 메모리 공간이 필요하면 virtual global memory에 액세스 한다.
- False Sharing이 발생할 수 있다.
False Sharing
다수의 CPU가 메모리의 같은 페이지를 다룰 때 발생하는 문제
- 페이지에 A,B라는 데이터가 존재.
- CPU1는 A, CPU2는 B만 액세스
➜ 이 경우, 해당 페이지는 CPU A, B 간 반복 전송된다.
A,B를 다른 페이지에 배치하면 해결할 수 있다.
■ Scheduling
Mutli-Computer에는 3가지 스케줄링 방식이 존재한다.
| 스케줄링 | 설명 |
|---|---|
| Graph-Theoretic Deterministic Algorithm | 작업들을 노드에 할당 노드 간 총 통신량이 최소화 되도록 스케줄링하는 방식 |
| A Sender-Initiated Distributed Heuristic Algorithm | 바쁜 노드가 스스로 작업을 다른 노드로 분산 |
| A Receiver-Initiated Distributed Heuristic Algorithm | 유휴 상태의 노드가 자발적으로 바쁜 노드로부터 작업을 요청하고 가져오는 방법 |
✏️ virtualization
■ Type1 Hypervisor
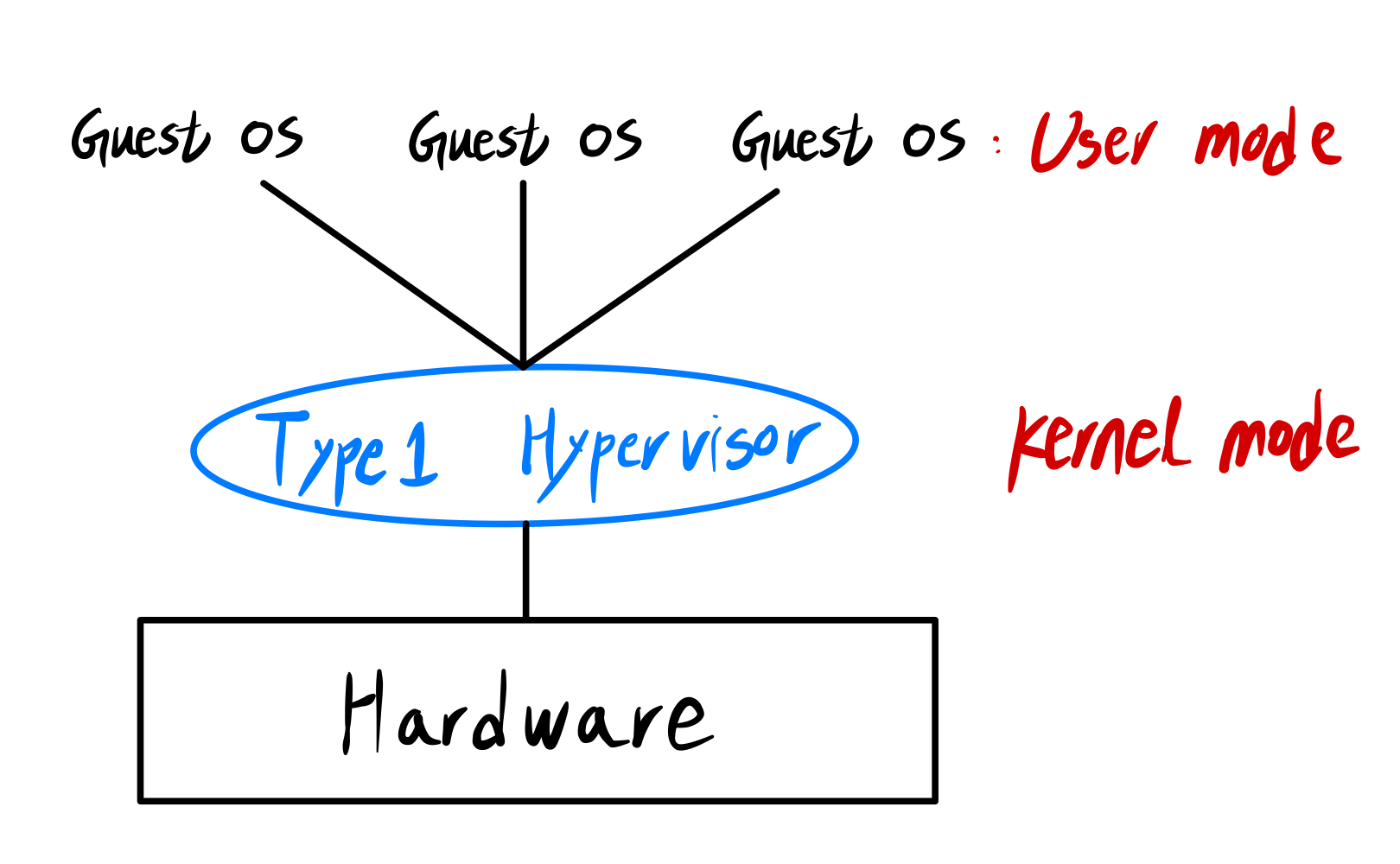
- 하드웨어에 직접 설치
- 운영체제 위에서 실행되는 것이 아니라, 운영체제 자체를 호스팅한다.
- 입출력은 Type1 Hypervisor가 담당한다!
➜ 가상머신에 존재하는 운영체제는 입출력 못함
➜ Hypervisor call 을 사용해서 입출력
■ Type2 Hypervisor
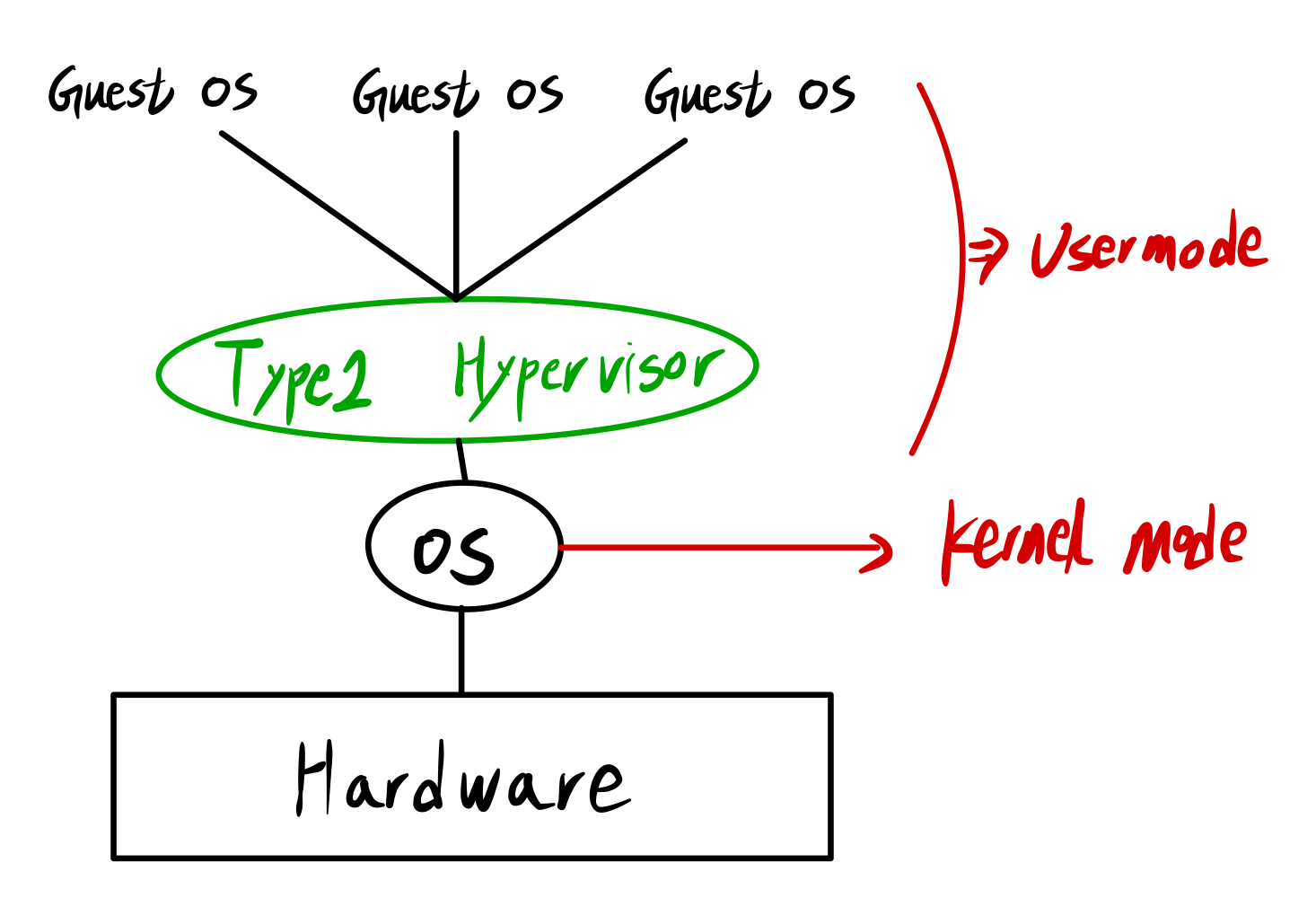
- Typ2 Hypervisor의 예시로 VMWare가 있다.
- 기존 운영체제 위에 설치된다.
- Guest OS에서, OS는 Virtual Kernel Mode 이고, 그 위에서 실행되는 프로세스는 Virtual User Mode이다.
■ Paravirtualization
Virtual Machine은 구현이 너무 어려워!
➜ 운영체제를 바꾸자
➜ Paravirtualization
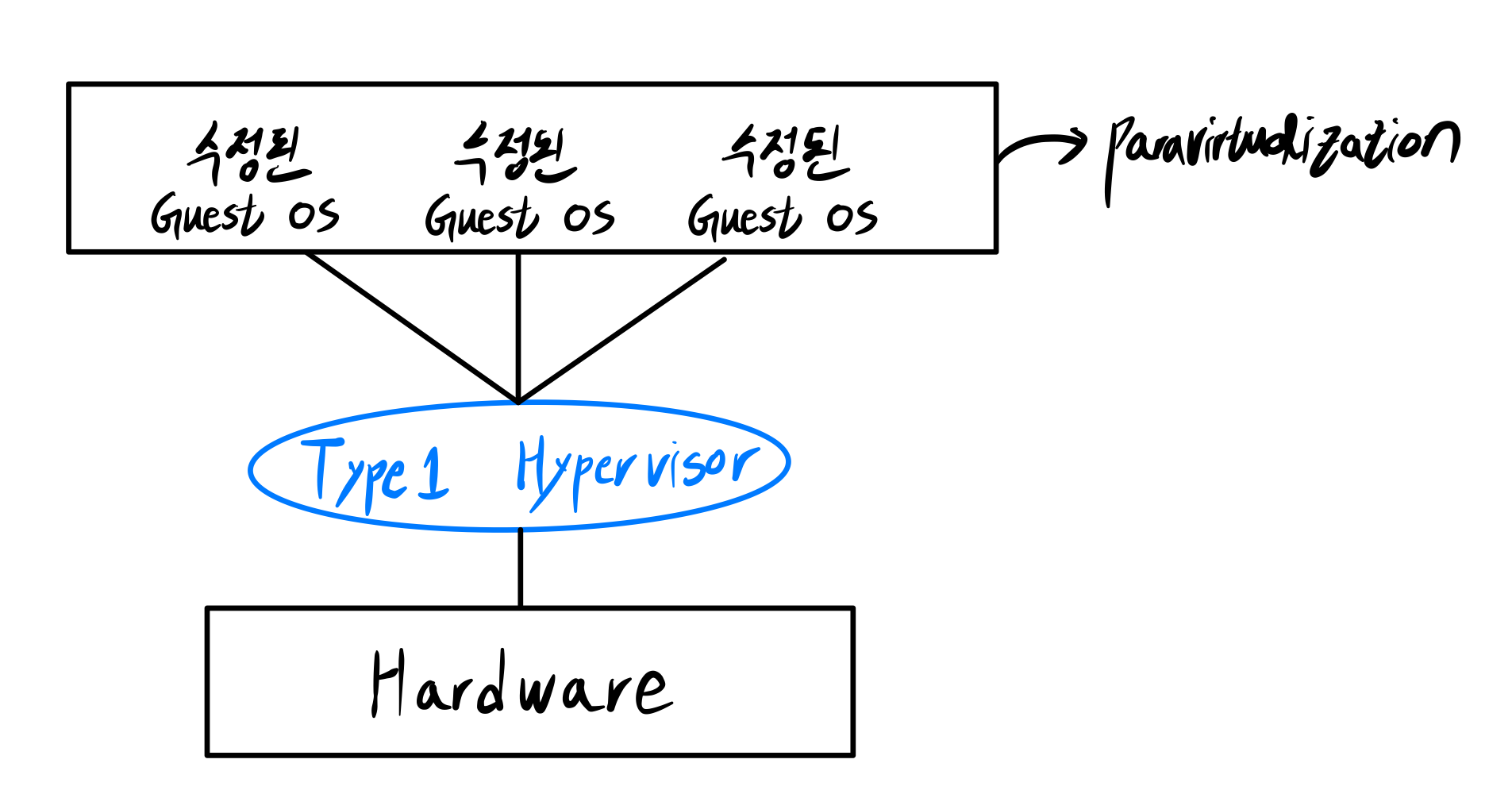
- Type1 Hypervisor의 일종이다.
- Guest OS에서 입출력할게 있으면 Hypervisor call해서 Hypervisor에게 부탁한다.
✏️ Middleware
Middleware
OS와 애플리케이션 간의 중재자 역할을 수행하는 소프트웨어
OS가 애플리케이션에 제공하는 서비스 이외의 추가적인 것들을 제공한다.
■ Document-Based Middleware
Web 브라우징과 같은 활동이 Document-Based Middleware의 예시이다.
- Web 브라우저를 통해서 Web 페이지를 시각화
- 링크를 클릭하여 다른 페이지로 이동
위의 기능들이 middleware의 동작 방식이다.
■ Coordination-Based Middleware
| 이름 | 특징 |
|---|---|
| Linda | 튜플을 통해 데이터를 저장하고 검색 ex: ("abc",2,5) "abc"로 검색하면 2,5를 결과로 반환한다. |
| Jini | 네트워크 내의 기기들이 서로를 발견하고 상호작용할 수 있게 하는 서비스 상용화 실패 |
REFERENCE
📚 Modern Operating Systems, Third Edition - Andrew S. Tanenbaum
