✏️ Scheduling
Scheduling: 다음에 실행할 프로세스(또는 스레드)를 고르는 운영체제의 알고리즘
이 포스트에서는 프로세스를 스케줄링하는 것에 대해서 설명한다.
■ Scheduling 시점
- 프로세스 생성될 때
- 프로세스 종료할 때
- I/O 인터럽트 발생
- 프로세스가 I/O, 세마포어, 또는 다른 무언가로 block 될 때
- 타이머 인터럽트가 발생할 때(preemptive)
preemptive VS Non-preemptive scheduling
- preemptive: 프로세스 실행 중 I/O, 인터럽트 등이 발생하면 스케줄링 발생, 실행 시간이 끝났을 때도 스케줄링 발생
- Non-preemptive: 프로세스가 작업을 마치고 자발적으로 대기 상태가 돼야 스케줄링 발생
■ 스케줄링 오버헤드(Context Switching 비용)
CPU가 실행하는 프로세스가 A 프로세스에서 B 프로세스로 바뀔 때 발생하는 비용
다음 과정을 거쳐서 CPU가 실행중인 프로세스를 바꾼다.
- User Mode ➜ Kernal Mode
- 프로세스 테이블에 프로세스 A의 상태 기록
- Scheduling
- 프로세스 B의 저장 상태를 불러옴
- 프로세스 B 실행(User Mode)
이 때 발생하는 비용은 다음과 같다.
- 모드 변경 비용
- 문맥 저장/복구 (A의 데이터 저장, OS 서비스 루틴 실행, 스케줄링, B의 프로세스 실행) 비용
- 메모리 맵 저장 비용
- CPU 캐쉬 무효화 비용
■ Process Behavior
프로세스의 행동은 다음 두가지로 나뉜다.
- CPU 계산
- I/O 대기
이에 따라서, 프로세스의 종류가 나뉜다.
-
CPU bound process
대부분의 시간을 CPU 계산에 소비하고, 나머지를 I/O 대기 하는 프로세스 -
I/O bound process
대부분의 시간을 I/O 대기에 소비하고, 나머지를 CPU 계산 하는 프로세스
⚠️ Scheduling 시, CPU bound, I/O bound process가 같이 대기하고 있는 경우 I/O bound process를 먼저 실행시켜야 한다. I/O bound process가 잠깐 계산하고 block 상태에 가 있는 동안 CPU는 CPU bound process를 실행한다.
■ Type of Scheduling
-
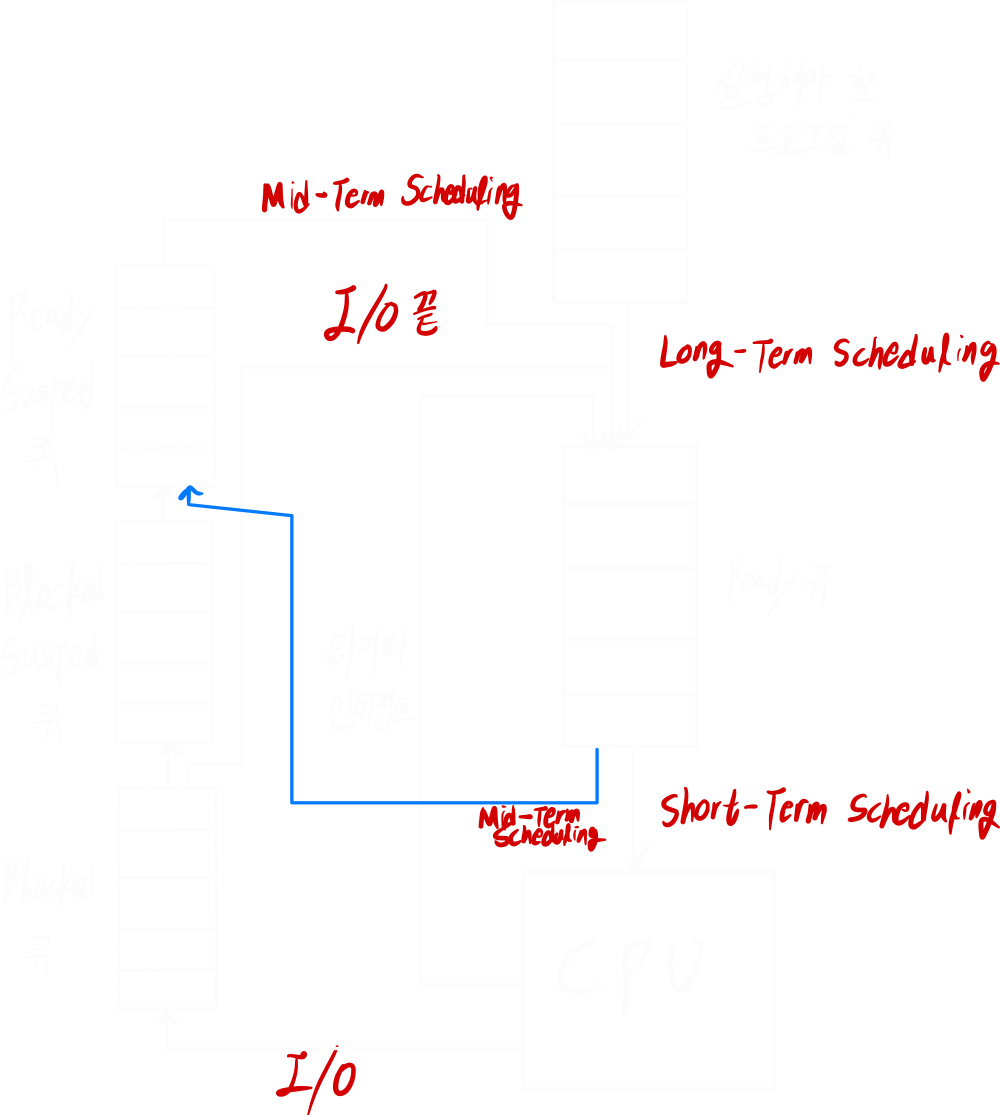
Short-term Scheduling:
Ready Queue ➜ Scheduling ➜ Run
Ready Queue에서 다음 프로세스를 선택하는 스케줄링 -
Medium-term Scheduling:
Ready/Suspend ➜ Scheduling ➜ Ready Queue
메모리에 존재하는 프로세스를 디스크에 보내거나, 디스크에 존재하는 프로세스를 메모리에 적재하는 스케줄링 -
Long-term Scheduling:
Scheduling ➜ Ready Queue 또는 Ready/Suspend
어떤 프로세스를 메모리에 로드할지 결정하는 스케줄링 -
I/O scheduling:
입출력 장치 각각이 어떤 작업을 먼저 처리할지 결정하는 스케줄링
■ Type of System
- Batch System: 한 번에 하나씩 순서대로 실행하는 운영체제
- Interactive System: 사용자와 대화하듯 실행하는 운영체제
- Real Time System: PC에는 존재하지 않고, 항공기나 로봇 등의 운영체제에 사용
| 시스템 종류 | 목표 |
|---|---|
| ALL | 1. 공평하게 우선순위에 따라 스케줄링 해야함. 2. 정책을 적용할 수 있어야 함. ex) 우선순위를 역으로 바꾸는 정책 3. 모든 구성 요소를 다 활용할 수 있게 균형이 맞아야 함. |
| Batch System | 1. Throughput: 단위 시간 안에 최대한 많이 실행 2. TurnAround time: waiting + executing time을 최소화 3. CPU Utilization: CPU 활용률이 높아야 함 |
| Interactive System | 1. Response Time: 응답 시간이 짧아야 함 2. Proportionality: 사용자의 기대치를 만족시켜야 함. |
| Real Time System | 1. DeadLine: 최소한 이때까지는 응답해야 함 2. Predictability: 모든 상황을 예측할 수 있어야 함 |
이제부터 이 시스템의 스케줄링 알고리즘에 대해 자세히 알아보자.
✏️ Batch System
Batch System의 스케줄링 알고리즘들에 대해 알아보자.
■ First Come First Served
먼저 온 프로세스부터 실행하는 스케줄링 알고리즘
- Non-Preemptive: 하나의 프로세스가 모두 끝나야 다음 프로세스가 실행된다.
- 프로세스 각각의 실행시간은 신경쓰지 않는다.
- Waiting time이 크다는 단점이 있다.
■ Shortest Job First
실행시간이 가장 짧은 프로세스를 선택해서 실행하는 스케줄링 알고리즘
- Non-Preemptive: 하나의 프로세스가 모두 끝나야 다음 프로세스가 실행된다.
- First Come first Served 방식에 비해 waiting time이 줄어들었다.
- Throughput은 똑같지만 Waiting time은 작음
■ Shortest Remaining Time Next
프로그램이 Ready Queue에 도착 시 스케줄링해서 남아있는 실행 시간이 가장 짧은 프로그램 실행
- Preemptive: 실행 중간에 다른 프로세스가 실행될 수 있다.
- 문맥 교환 비용은 고려하지 않음
- Shortest Job First보다 Waiting time이 또 줄어들음
■ Highest Response Radio Next
Shortest Job First/ Shortest Reamining Time next 에도 단점이 존재한다.
Starvation - 실행 시간이 긴 프로그램은 계속 밀림
따라서, 오래 기다리면 결국엔 실행되게 만든다.
- (대기 T + 실행 T) / 실행 T
- 위의 값이 제일 큰 애가 먼저 실행됨
✏️ Interactive System
Interactive System의 스케줄링 알고리즘들에 대해서 알아보자.
거의 모든 알고리즘이 Preemptive하다.
■ Round-robin scheduling
각 프로세스에 똑같은 Time Quantum을 줘서 번갈아가며 실행한다.
Time Quantum: 시스템을 실행하는 단위(더 이상 쪼개질 수 없음)
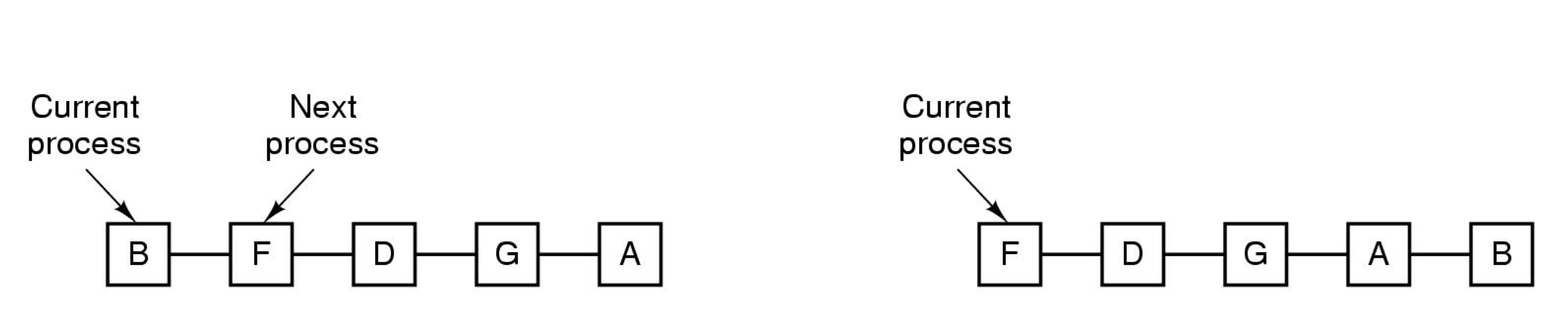
- 큐에 여러개 프로세스가 매달려 있음
- B를 실행하다가 Time Quantum이 끝나면 F를 실행
Time Quantum이 너무 짧으면, Context Switching이 자주 발생해서 CPU 효율이 떨어진다.
Time Quantum이 너무 길면, Response Time이 너무 커진다.
■ Virtual Round-Robin Scheduling
Round-Robin의 단점을 개선함
-
I/O Bound Process는 자기에게 할당된 CPU 시간(Time Quantum)을 다 받지 못한다.
ex) 실행시간 (Time Quantum)10ms 프로그램 실행하다가 7ms 쯤에 I/O 인터럽트 걸림.
I/O 대기 오래 해야 함. -
Auxiliary Queue를 도입함.
Time Quantum을 다 쓰지 못한 프로세스는 Auxiliary Queue에 들어감.
Auxiliary Queue는 Ready Queue보다 우선순위가 높다.
■ Priority Scheduling
우선 순위에 따라서 프로세스를 스케줄링한다.
- 우선순위별로 큐를 따로 둔다.
- 우선순위 1번 큐에 프로세스가 하나도 없을 때, 2번 우선순위 큐로 내려간다.
- 무조건 우선순위 높은 큐부터 실행한다.
■ Multilevel Feedback Queue
I/O bound Process의 우선순위는 높게, CPU bound process의 우선순위는 낮게
- CPU bound process가 CPU에 들어오면 우선순위 낮은 큐로 보냄
- CPU bound process는 한번 실행할 때마다 우선순위가 점점 낮아짐
- starvation 문제가 발생할 수 있으므로 오래 기다린 애는 우선순위를 조금씩 높여줌
➜ Aging Mechanism
■ Short Process Next
실행 시간이 짧은 애를 먼저 실행함
- 과거의 실행 기록을 보고 결정
- Exponential Averaging으로 평균을 내서 실행 시간을 결정한다.
Average = a*추정시간 + (1-a)*과거시간
■ Guaranteed Scheduling & Lottery Scheduling
- Guaranteed: n개의 프로세스 각각에게 1/n의 시간 동안 실행하도록 해줌
- Lottery: n 개의 프로세스 각각이 전체 실행 시간을 나누어 가짐
A: 60%, B: 30%, C: 10% 주고 싶어.
복권을 100장 발행해서, A는 60개 주고, B는 30개 주고, C는 10개 줌
Random Number 발행해서 복권 값이 맞으면 해당 프로그램을 실행시킴
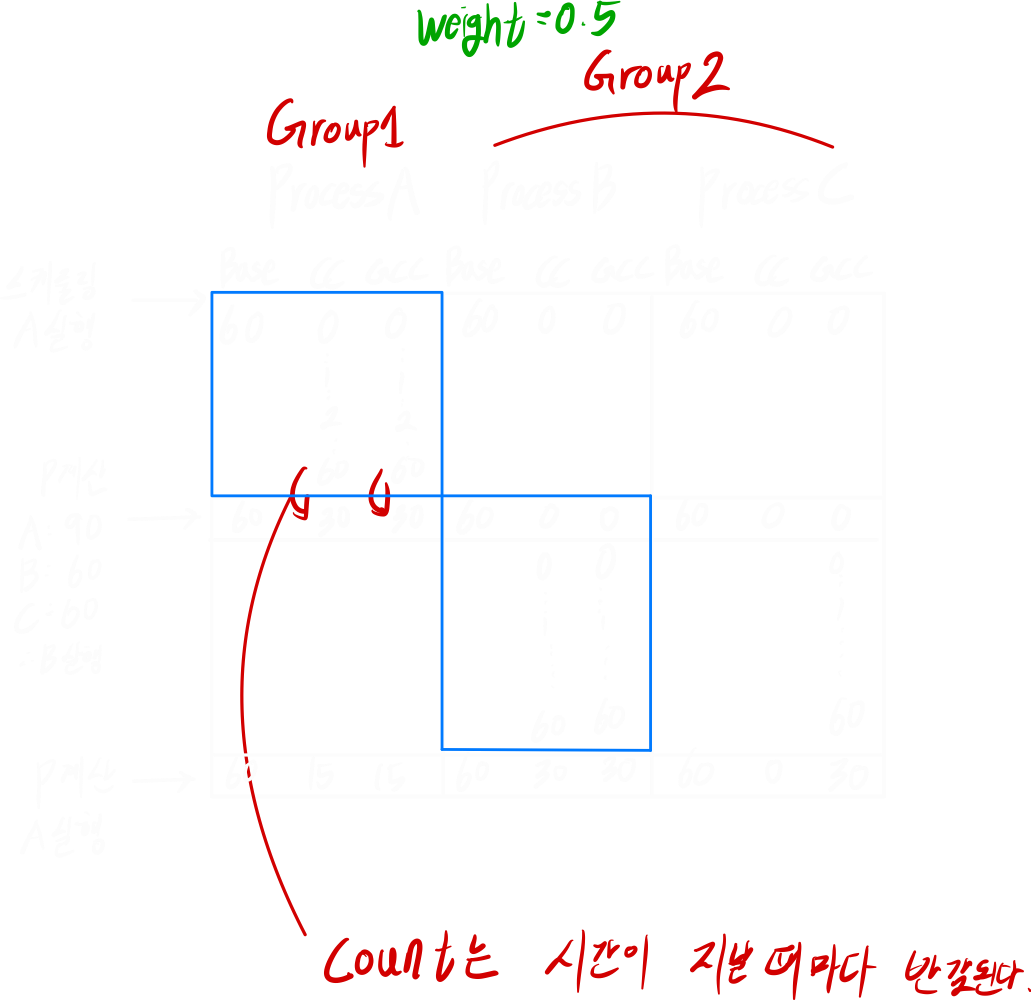
■ Fair-share Scheduling
고전적인 Unix Scheduling에 Group CPU count를 추가한 알고리즘
- 프로세스를 한번 실행 하면 CPU 시간이 커져서 P가 커짐. 그러면 우선순위가 낮아짐
- 기다리면 CPU count가 점점 작아져서 우선순위가 높아짐
- 거기다 group 별로 weight를 준다.
✏️ Mechanism VS Policy
Scheduling Mechanism과 Policy는 구분되어야 한다.
Scheduling Mechanism을 OS 안에 만들고, Policy는 user process가 쉽게 변경할 수 있게 해야한다.
✏️ Thread Scheduling
현대 컴퓨터에서는 OS가 스레드 단위로 스케줄링을 한다.
아주 옛날에 OS가 스레드의 존재를 모를 때, 스케줄링은 프로세스 단위로 처리됐다.
- OS가 프로세스 단위로 스케줄링
- 프로세스는 User level thread 패키지를 사용해서 각 스레드를 스케줄링
■ (과거) User level Thread Scheduling
process A
User level thread A1, A2, A3 갖고 있음
process B
User level thread B1, B2, B3 갖고 있음
OS는 스레드의 존재를 알지 못하고, 프로세스 단위로 스케줄링 함
- [A1, A3, A2] , [B3, B2, B1] 순서로 실행 가능
- [A1, B1, B3, A2, A3, B2] 같이, 프로세스가 섞인 경우 실행 불가능
■ (현재) Kernal Level Thread Scheduling
process A
Kernal level thread A1, A2, A3 갖고 있음
process B
Kernal level thread B1, B2, B3 갖고 있음
OS는 스레드의 존재를 알고 있고, 스레드 단위로 스케줄링함
- [A1, A3, A2] , [B3, B2, B1] 순서로 실행 가능
- [A1, B1, B3, A2, A3, B2] 같이, 프로세스가 섞인 경우도 실행 가능
✏️ Traditional Unix Scheduling
전통적인 Unix 스케줄링 방식에 대해서 알아보자.
-
Multilevel Feedback + Round Robin + priority Queue
- Multilevel Feedback: I/O bound는 우선순위 높음, CPU bound는 낮음
- Round Robin: Time quantum마다 번갈아가며 실행
- Priority Queue: 우선순위별로 큐를 따로 둔다.
-
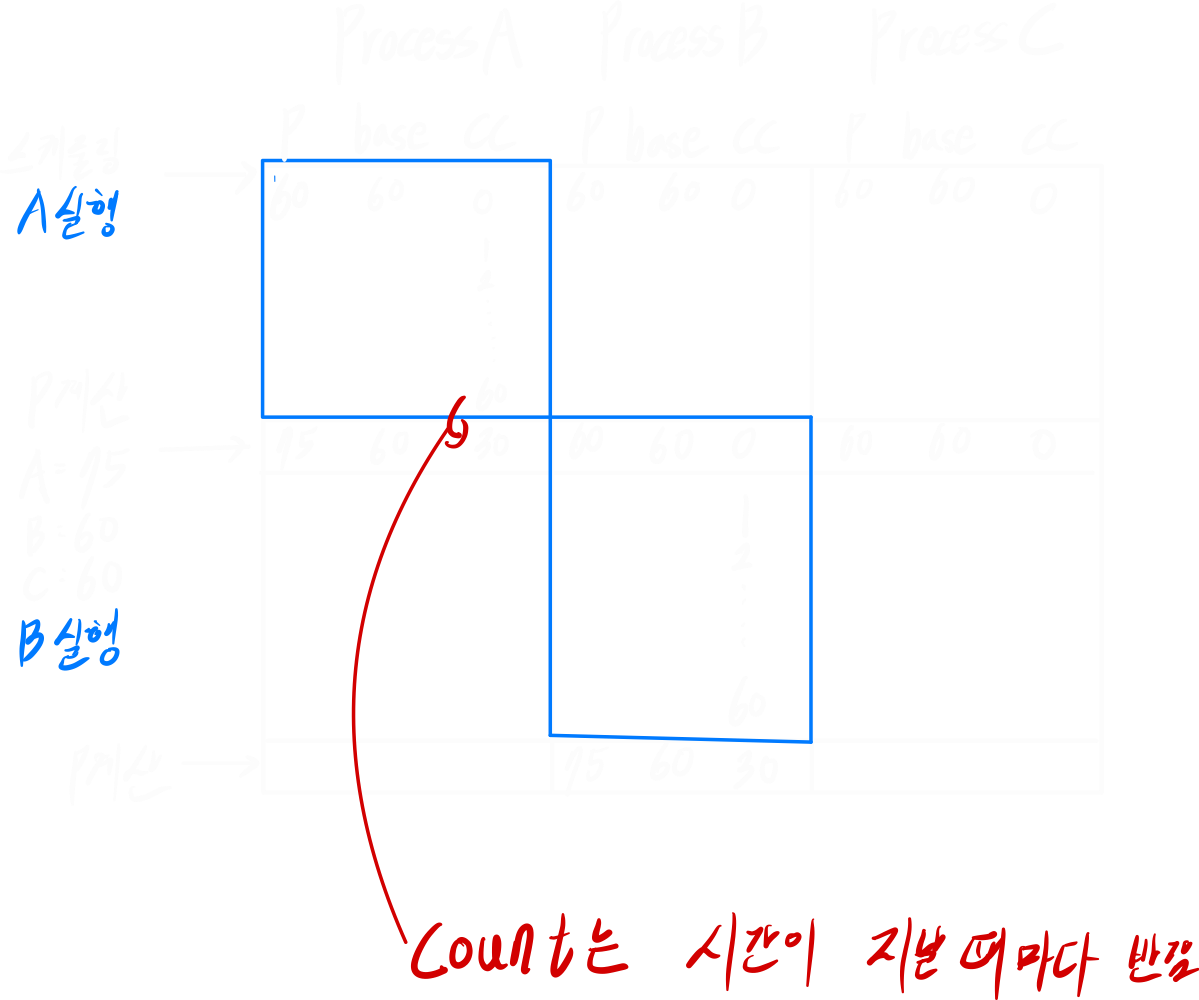
사용하는 공식은 다음과 같다.
P = Base + CPUcount_(i)/2 + nice값- P가 작을수록 우선순위가 높다.
- 프로세스마다 nice 값이 존재한다.
- nice 값을 마음대로 감소시키는 것은 super user만 가능하다.
- P는 1초마다 재계산된다.
■ BSD and SVR3 Scheduling
Traditional Unix Scheduling: 매 타임마다 scheduling을 한다.
➜ 매우 overhead가 크다.
SVR3
- decay factor = 1/2
- 즉 1초마다 CPU count가 반감된다.
- Starvation(무한 대기) 발생가능
BSD
- SVR3의 decay factor(1/2)가 너무 과하다. CPU count가 금방 0이 되어 버린다.
- 실행중인 프로세스 개수가 크면 클수록 decay factor를 더 크게하자.
➜ CPU count가 조금씩 줄어든다.
decay factor = (2*실행중인 프로세스 개수)/((2*실행중인 프로세스 개수) + 1)
즉, 3개인경우: 6/7, 4개인경우 8/9
✏️ Linux Scheduling
Unix계열 운영체제인 Linux의 Scehduling 방식에 대해서 알아보자.
Linux의 스케줄러는 클래스 단위로 모듈화 되어있다.
스케줄러 클래스마다 각기 다른 알고리즘, 우선순위가 존재한다.
- FIFO 클래스: 하나의 스레드가 멈출 때까지 실행
- Round Robin 클래스: 동일한 우선순위인 스레드들을 Time quantum 만큼씩 실행
FIFO와 Round Robin은 Real Time 프로그램을 위한 클래스이다. (동영상 등)
- Other 클래스
Other는 Non Real Time 프로그램을 위한 클래스이다.
■ (과거) O(1) Scheduler
과거에는 Other 클래스를 이용한 O(1) Scheduler를 사용했다.
O(1) Scheduler의 특징은 다음과 같다.
- 각각 140개의 active queue, expired queue가 존재한다.
- 어느 queue에는 task가 매달려 있고, 어떤 queue는 아무것도 없다.
- active queue마다 비트가 하나 있음.
비트가 0: 아무것도 없음
비트가 1: task가 존재함
- task마다 우선순위가 있음, 우선순위에 따라서 time slice 값 부여
- 한번 실행을 하면 자기의 time slice 동안 실행
- 실행이 끝나면 expired queue에 가서 매달림
- active queue가 다 비었으면, active queue ⇄ expired queue 전환
추가로, I/O bound process에 우선순위를 높게 주고 싶다면?
➜ effective priority 개념 추가 + 인터액티브(User와 상호작용) 태스크는 active queue에 넣음
effective prio = sleep_avg(실행시간 대비 휴면시간 비율) + 우선순위(nice에 비례)- time slice를 effective priority에 비례하게 할당한다.
O(1) Scheduler의 문제점
-
Nice값이 크면 timeslice가 크다.
➜ 우선순위가 높으면 더 오래 실행한다. -
Nice 값의 차이가 timeslice 차이에 비례하지 않는다.
Nice: 0->1 이면 5% 증가한건데 timeslice도 5ms 증가
Nice: 19->20 이면 2배 증가한건데 timeslice도 5ms 증가 -
인터액티브 태스크가 항상 active queue로 들어간다.
■ (현재) CFS Scheduler
I/O bound, CPU bound를 구분하지 않고, Time slice를 공평하게 분배한다.
- 큐 없이 Red Black Tree로 구현했음
- Nice 값에 정확히 비례해서 Time slice(weight) 할당
- Virtual Runtime 개념 도입
Timer interrupt가 20ms마다 걸린다면, 한 프로세스가 45 ms, 다른애는 15ms로 실행하고 싶은데, 실제로는 40ms, 20ms 실행함
40,20
✏️ UNIX SVR4 Scheduling
System Five Release 4 운영체제
Real Time process를 위한 기능들이 많이 추가됐다.
- Real time
- Kernal
- User Mode
순으로 우선순위가 낮다.
사용자 프로세스는 0-59까지 할당받음.
Kernal Mode 프로세스는 60-99
Real time process는 100-159
0-159까지 큐가 달려있다.
BitMap이 존재한다: 큐가 비어있으면 0, 큐에 매달려있으면 1
몇몇 시스템호출은 굉장히 오래걸림
- Real Time process가 깨어남
- 근데 시스템 호출이 끝나야 Real Time process를 실행가능.
- OS 코드 안에 Preemption Point를 넣어서 중간중간 스케줄링할 수 있도록 처리
- 현재 실행하는 프로세스를 잠시 중단하고, 급한 프로세스 먼저 실행.
하지만, 그럼에도 불구하고 Linux, Windows는 Real Time 운영체제는 아니다.
✏️ Windows Scheduling
Real Time 클래스와
Variable 클래스 존재
Preemptive Scheduilng
Non-preemptive: 멈출때까지
0-32까지의 우선순위가 있다.
0-15: 일반 프로그램
16-21: Real Time 프로그램
스레드를 만들면서 우선순위를 지정할 수 있다. - 의미없음, 어차피 스레드의 우선순위는 실행하면서 계속 변함
✏️ 동기화 문제 예제
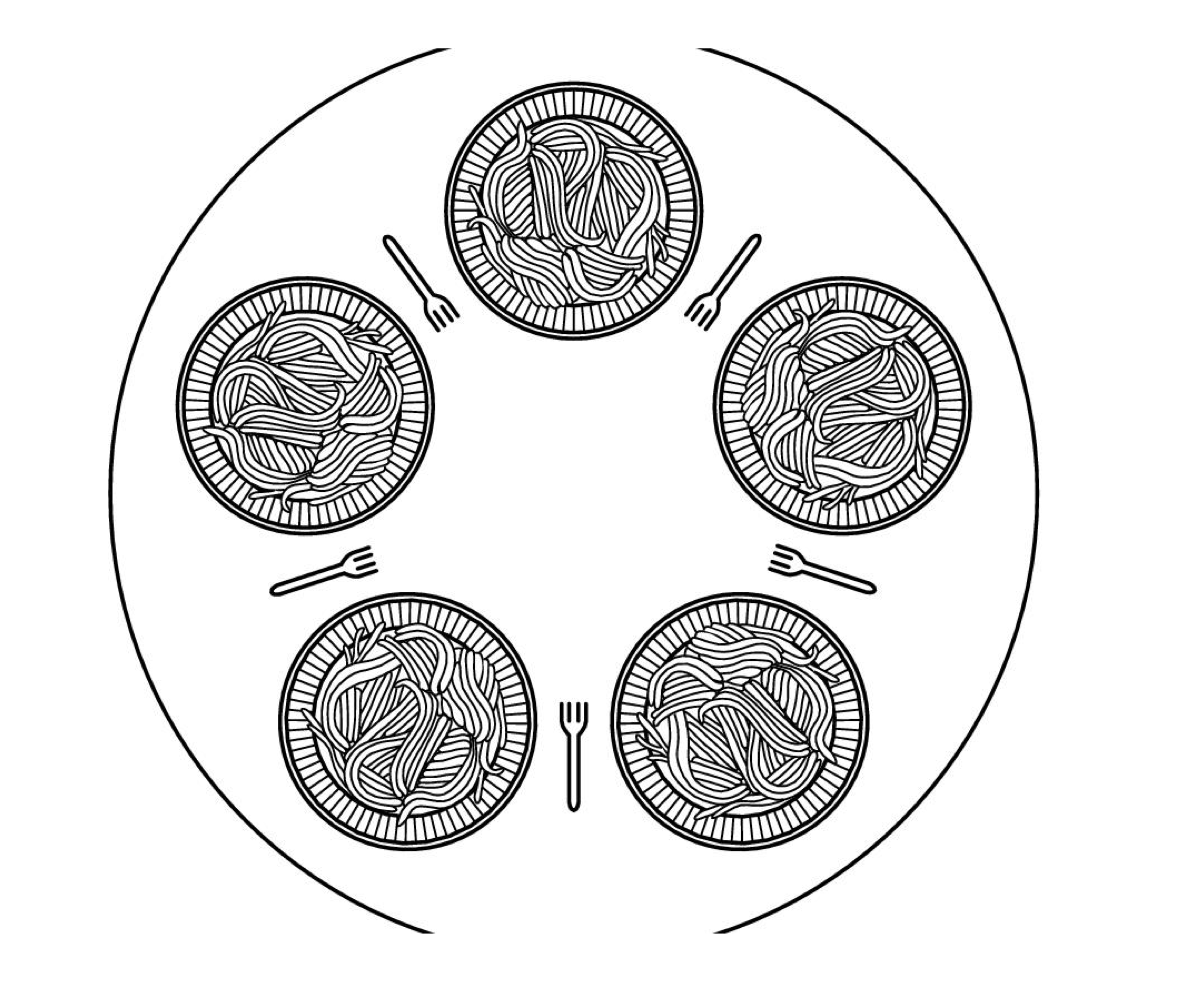
■ Dining Philosophers Problem
Dijekstra가 동기화 문제의 예제로 설명했다.
철학자가 5명 존재한다.
철학자가 식사를 하려면, 포크를 2개 집어야 한다.
// 각 스레드가 무한루프를 돌음
while(true){
think();
pick_fork(i); // 자기 왼쪽, 오른쪽 것 집어야 함. ex)1번 스레드는 0,4 집어야 함.
eat();
put_fork(i);
}실제로 돌리면 스레드 5개가 다 멈춘다.(DeadLock)
Dead Lock을 피하기 위해서는 다음과 같은 방법을 따라야 한다.
- 포크를 정하는 순서를 정한다. (짝수 철학자는 오른쪽 먼저, 홀수 철학자는 왼쪽 먼저)
- 2번의 경쟁 상황(왼쪽, 오른쪽)이 발생한다.
- 세마포어를 사용해서 위의 방법을 구현한다.
- 이 때, 세마포어 초기값은 0이다.
- test에서는 자신의 세마포어를 up하거나, 아니면 바로 리턴한다.
test에서 자신의 세마포어를 up한경우는 성공해서 슬립하지 않는다.
test에서 바로 돌아온 경우는 down(&s[i])에서 슬립한다.
void pick_fork(int i){
down(&mutex);
state[i] = HUNGRY;
test(i);
up(&mutex);
down(&s[i]); // 실패한 경우 슬립
}void put_fork(i){
down(&mutex);
state[i] = THINKING;
test(LEFT); // 나는 다 먹었으니까 옆에 사람 깨워야 함.
// i가 1이라고 하면, 마치 0번 인것처럼 test를 호출
test(RIGHT); // 나는 다 먹었으니까 옆에 사람 깨워야 함.
up(&mutex);
}void test(i){
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] != EATING) {
state[i] = EATING;
up(&s[i]);
}
}■ Reader Writer Problem
Multiple Readers/ Single Writer의 경우
rc(read count): 동시에 read하는 reader의 수
- Reader나 Writer는 db semaphore를 흭득해야 한다.
- Reader/Writer 둘 중 하나만 사용 가능하다.
- Reader는 여러개가 연속으로 읽기 가능하다.
void reader(){
while(TRUE){
down(&mutex);
rc = rc + 1;
if(rc == 1) down(&db); // 첫 reader인 경우
up(&mutex);
read_data_base();
down(&mutex);
rc = rc - 1;
if(rc==0) up(&db); // 마지막 reader인 경우
up(&mutex);
use_data_read();
}
}void writer(){
while(TRUE){
down(&db);
write_data_base();
up(&db);
}
}Writer에 Starvation이 발생 가능하다.
writer는 down(&db)에 멈춰있고, Reader는 계속 들어와서 읽어감
Readers Writers Problem with Writer Priority
Multiple Readers, Multiple Writers의 경우
-
read semaphore, write semaphore를 모두 흭득해야 Read/Write가 가능함.
단, 첫 Reader가 흭득한경우, 다음 애는 자동으로 write semaphore흭득한 채로 유지.(Writer도) -
항상 read semaphore -> write semaphore 순으로 흭득한다.
void reader() {
while(TRUE){
down(z);
down(rsem); // read semaphore 흭득
down(x);
readcount++;
if(readcount == 1) //첫 reader
down(wsem); // write semaphore 흭득
up(x);
up(rsem); // read semaphore 반납
up(z);
READUNIT();
down(x);
readcount--;
if(readcount == 0) // 내가 마지막 reader면
up(wsem); // write semaphore 반납
up(x);
}
}z가 필요한 이유: reader들끼리 상호배제.
- z를 가진 reader만 read semaphore를 가져올 수 있음
- down(rsem)에서 경쟁하는 상대는 writer밖에 없다.
- rsem을 가져가면, write semaphore는 자동으로 가져가게 되어있다.
하지만 reader의 starvation이 발생할 수 있다.
void writer() {
while(TRUE) {
down(y);
writecount++;
if(writecount == 1)
down(rsem);
up(y);
down(wsem);
WRITEUNIT();
down(y);
writecount--;
if(writecount == 0)
up(rsem);
up(y);
}
}- writer는 기다리고 있으면 한단계씩 전진한다.
✏️ Bands
Band는 특정한 작업 유형 또는 프로세스 그룹에 대한 우선순위를 나타낸다.
우선순위가 높을수록 번호가 작다.
- Swapper
- Block I/O device control
- File manipulation
- Character I/O device control
- User Process
다음과 같은 상황에서 우선순위가 중요한 요인이 된다.
- User Process에서 I/O 인터럽트가 걸린다.
Kernal Mode로 가서 서비스 루틴 실행 후 I/O 대기(block)- I/O 끝
- 잠시 우선순위가 File manipulation이 된다.
➜ 우선순위가 높으므로 빠르게 돌아온다.
REFERENCE
📚 Modern Operating Systems, Third Edition - Andrew S. Tanenbaum
