이전까지 Selection Operation 작업을 통해 SQL 에서 조건에 맞는 데이터를 뽑는 작업을 하였다.
이번엔 뽑은 데이터를 정렬하는 과정 Sorting Processing 에 대해 알아보자
Sorting
- Data 의 Sorting 은 DB 시스템에서 중요한 두 가지 이유가 존재한다
-
SQL Query 는 ORDER BY(Sort 연산)을 통해 데이터를 구체화 할 수 있다.
-
다른 관계연산들 (Join 등) 과 대등하게 Query Processing 에서 중요한데, 이는 첫 입력때 Sort 연산이 되어있을 시 효율적인 구현이 가능하다.
핵심은 논리적 정렬의 비효율성과 물리적 정렬의 필요성.
데이터 정렬 방식과 비용
1. 논리적 정렬 (Sorting Logically) - 인덱스 사용
테이블(릴레이션) 자체는 정렬되어 있지 않지만, -tree와 같은 인덱스를 사용해 정렬된 순서대로 레코드를 읽어 들이는 방식.
문제점: 높은 비용
인덱스는 레코드의 물리적 주소(포인터)를 저장하며, 이 포인터가 가리키는 실제 레코드들은 디스크에 분산되어 저장되어 있을 가능성이 높아서(특히 보조 인덱스나 힙 테이블) 인덱스 순서대로 다음 레코드를 읽을 때마다 디스크의 다른 임의의 위치로 헤드를 이동해야 하는 문제가 생긴다.
비용: 이는 레코드 하나당 (즉, )을 유발하며, 이는 매우 비효율적이다. (랜덤 I/O 비용).
2. 물리적 정렬 (Ordering Physically) - 디스크 인접
인덱스 기반 논리적 정렬의 비효율성 때문에, 대량의 데이터를 정렬 순서대로 효율적으로 읽기 위해서는 레코드를 디스크에 물리적으로 정렬하는 것이 바람직하다.
목표: 데이터가 물리적으로 정렬되면, 한 레코드를 읽은 후 다음 레코드는 바로 옆 블록에 있게 되어 탐색 시간() 없이 순차 I/O로 데이터를 매우 빠르게 읽을 수 있다. (클러스터형 인덱스의 장점)
물리적 정렬 방법 : 데이터의 크기가 메모리의 용량 따라 주요 알고리즘이 사용된다.
1. 메모리에 맞는 릴레이션 (Relations that fit in memory)
데이터 크기가 메인 메모리에 충분히 들어갈 경우, 와 같은 표준 내부 정렬 알고리즘을 사용해 모든 데이터를 한번에 빠르게 정렬할 수 있다.
2. 메모리에 맞지 않는 릴레이션 (Relations that don't fit in memory)
대용량 데이터(빅 데이터)는 한 번에 메모리에 올릴 수 없으므로, (외부 정렬-병합) 알고리즘을 사용해야한다.
작동 방식: 데이터를 메모리 크기만큼 분할하여 각각 정렬한 후(runs), 이 정렬된 분할 파일들을 디스크와 메모리를 오가며 하여 최종적으로 정렬된 파일을 생성한다.
External Merge Sorting - 외부 정렬 병합
데이터가 Main Memory에 한 번에 들어가지 못할 때 디스크 효율적 정렬 방식
1. 정렬된 Runs 생성
대규모의 릴레이션을 메인 메모리 크기만큼 작은 정렬된 Runs 들로 나눈다
- 초기 Run 의 index 를 0으로 설정
- 이후 3가지 작업을 반복
1. Memory Load : 한 Run 의 데이터를 디스크에서 메모리로 읽어 들인다
2. Memory Sort : 메모리로 불러온 Run 내의 레코드들을 QuickSort 실행
3. Run 저장 : 정렬된 Run의 데이터를 디스크에 R[i]로 저장. 저장 후 i를 증가시켜 다음 런 준비 - 결과 : 릴레이션 전체가 저장된 일련의 정렬된 조각들로 나뉨
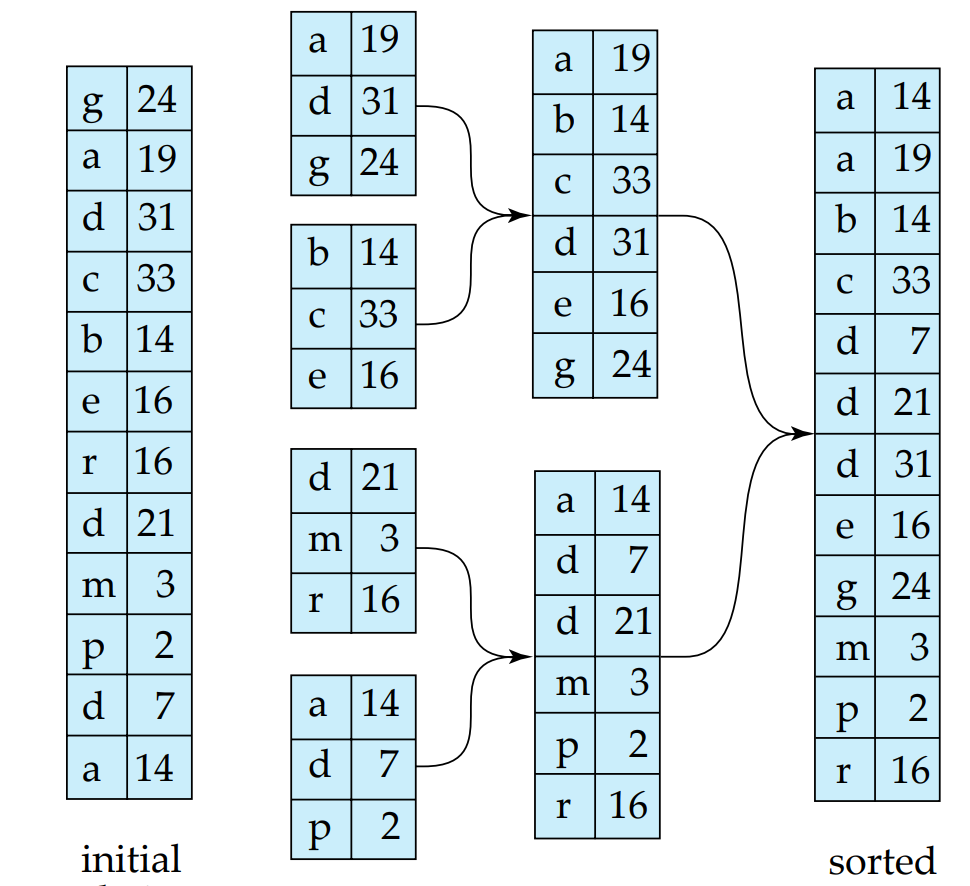
2. N - Way Merge
1에서 외부 정렬된 Run 들을 하나로 Merge 하여 최종적으로 완전히 정렬된 하나의 릴레이션을 만드는 단계
가정 : 현재는 병합할 Run 의 개수가 메모리 블록 수보다 작다고 가정 - 모든 런을 한번의 병합 단계로 처리 가능
메모리 할당
: N개의 런에 각각에 대응하는 입력 버퍼로 Run 개수 만큼 메모리 할당
- 최정 결과를 디스크에 쓰기 위한 출력 버퍼로 1블록의 메모리를 할당
-총 사용 메모리 : Run 개수 ()+ 1 만큼의 Run 용량
반복 병합 작업: 모든 입력 버퍼 페이지가 비워질 때까지 다음을 반복한다.
-
레코드 선택: 현재 개의 모든 입력 버퍼 페이지에 들어있는 레코드들 중에서 정렬 순서상 가장 작은 (또는 가장 큰) 레코드를 선택.
-
출력 및 버퍼 관리: 선택된 레코드를 출력 버퍼에 쓴다. 출력 버퍼가 가득 차면, 그 내용을 디스크에 출력.
-
입력 버퍼 관리:선택된 레코드를 해당 입력 버퍼 페이지에서 삭제. 만약 이 삭제로 인해 입력 버퍼 페이지가 비게 되면, 해당 런의 다음 블록 (있다면)을 디스크에서 읽어와 비어버린 버퍼 페이지를 채운다.
결과: 모든 런의 데이터가 개의 스트림으로 병합되어 디스크에 완전히 정렬된 하나의 릴레이션으로 저장된다.
