데이터베이스는 모든 가능한 Schedule이 다음을 보장하는 메커니즘을 제공해야 한다:
-
conflict serializable 또는 view serializable가 가능한 스케줄이어야 한다.
-
스케줄은 recoverable하고 가능하면 cascadeless 을 지원해야 한다.
다시 한번 짚고 넘어가자
-
Serializability : 직렬화 가능은 여러 트랜잭션이 동시에 실행되었을 때, 그 실행 결과가 직렬적으로 실행된 것과 동일한 결과를 만들어낸다면 그 트랜잭션들의 스케줄은 직렬화 가능하다
-
conflict serializability: 두 트랜잭션이 동시에 실행될 때, 그 실행 순서를 직렬화 가능한 순서로 바꿀 수 있어야 한다는 것.트랜잭션들이 충돌을 일으키지 않도록 하여 일관된 결과를 보장해야 합니다.
-
view serializability: 트랜잭션들이 동시 실행되더라도 결과적으로 동일한 데이터베이스 상태를 만들 수 있어야 한다는 것입니다.
-
recoverable: 트랜잭션이 실패했을 때, 실패한 트랜잭션이 롤백(rollback) 될 수 있어야 하며, 다른 트랜잭션이 실패한 트랜잭션의 영향을 받지 않도록 해야 한다는 것입니다.
-
cascadeless: 트랜잭션이 롤백되면 그 트랜잭션과 연결된 다른 트랜잭션들도 자동으로 롤백되지 않도록 해야 한다는 것입니다. 이렇게 하면 불필요한 롤백을 피할 수 있다.
Lock Protocol
Lock 은 데이터에 대한 Concurrency control 하는 하나의 메커니즘
Lock 에는 Exclusive Lock , Shared Lock 이 존재한다.
Exclusive Lock( Lock-X(T) )
-
Lock-X는 해당 트랜잭션에 대해 본인만 데이터 항목에 대해 읽기와 쓰기 모두 가능하게 하는 잠금 모드. X-lock을 설정하면 다른 트랜잭션은 해당 데이터 항목을 읽거나 쓰는 작업을 할 수 없게 된다.
-
예를 들어, T1이 X-lock을 요청하여 데이터 항목 A에 배타적 잠금을 걸면, T2는 그 데이터 항목 A에 대해 읽기/쓰기를 할 수 없다.
Shared Lock( Lock-S(T) )
-
Lock-S 는 해당 본인만 데이터 항목을 읽기만 가능하게 하는 잠금 모드. Lock-S을 설정하면 여러 트랜잭션이 해당 데이터를 읽을 수 있지만, 수정은 할 수 없다.
-
예를 들어, T1이 S-lock을 요청하여 데이터 항목 A에 Lock-S을 걸면, 다른 트랜잭션 T2, T3, T4 등은 A를 읽을 수 있지만 수정할 수는 없다.

Consistency vs Deadlock
Lock 기능을 사용하면 필연적으로 DeadLock 상황을 맞이할 수 밖에없다.
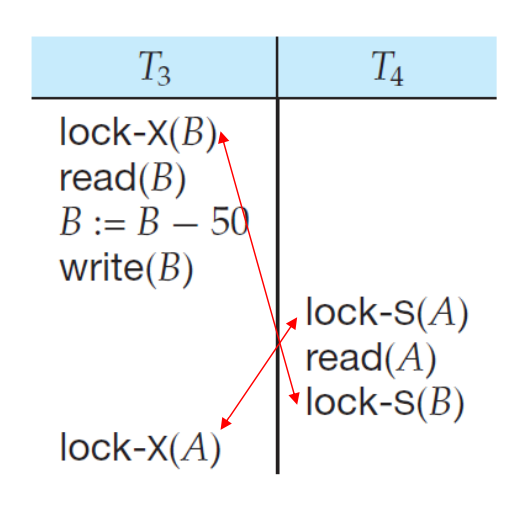
DeadLock 이 발생하면 , 트랜잭션들은 상호 배타적 자원을 기다리고 있지만, 어떤 트랜잭션도 자원을 해제하지 않아서, 결국 무한 대기에 빠지게 된다. 결국 두 트랜잭션 중 하나는 Rollback 해야한다.
Deadlock의 발생 원인
- Lock 을 사용하지 않거나, 너무 일찍 Lock을 해제할 경우:
Lock을 사용하지 않거나 트랜잭션이 데이터 항목을 너무 빨리 해제하면, 다른 트랜잭션이 해당 데이터를 읽거나 쓸 수 있는 시점에 데이터의 무결성 없는 상태(inconsistent state)가 발생한다.
- Lock을 과도하게 해제하지 않고 다른 데이터 항목에 대해 잠금을 요청할 경우:
Lock 을 너무 안 풀면 DB의 Concurrency(동시성)가 줄어듬
Lock 을 사용하면 DeadLock 은 자연히 발생한다.
따라서 적당한 DeadLock 대처 방안을 사전에 정립해야 한다.
Starvation Problem (기아 상태)
- T2 → Q 에 대해 S 락 요청 ,
- T1 → Q 에 대해 X 락 요청 - 두 요청은 Compatible 불가 , T1 은 대기 상태로 진입
- T3 → Q에 대해 S 락 요청 - t1 ,t3 요청은 Compatible 가능 , T3 는 요청 grant
- T2 → Q 에 대해 S 락 해제 하지만 T3 에 의해 S 락이 걸려있음
- T4 → Q 에대해 S 락 요청 , T3 S 락 해제 , T4에 의해 S 락이 걸려있음
- 이런 일이 반복되면 T1 은 평생 X 락 요청 승인이 되지 않는다.
Starvation Problem 의 해결책
Compatibility 만 보는게 아니라 다른 요청 대기중인게 있는지 확인
2PL(2-Phase-Locking)
두 단계 잠금 프로토콜(2PL):
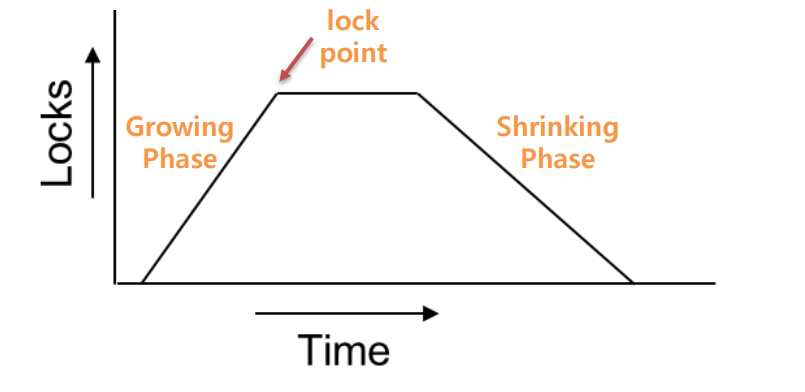
- 트랜잭션이 잠금을 획득하기만 하는 Growing phase
- 트랜잭션이 잠금을 해제하기만 하는 Shrinking phase
-> 획득 단계에서는 Lock 만 가능 , 해제 단계에서는 Unlock 만 가능
-> 이에 의해 이 프로토콜은 Conflict serializability를 보장.
- But, DeadLock 를 해결하지는 않음 (당연히)
- 또한 Lock 획득을 유동적으로 할 수 없어 트랜잭션이 긴 식나을 소모하거나 병목 현상 발생
- 한 트랜잭션에서 Lock 과 Unlock 을 반드시 끝내야 한다.
두 단계 잠금 프로토콜 (2PL) 세부 설명
- 트랜잭션이 커밋(commit)될 때까지 모든 Lock 을 유지(쌓음)하게 하여 커밋되지 않은 데이터에 대한 접근을 차단.
- 다 얻었으면 Lock 을 Release 하기 시작한다.
Strict Two-Phase Locking Protocol (엄격한 2단계 잠금)
“모든 배타 락(Exclusive Lock, X-lock) 은 트랜잭션이 commit 또는 abort 될 때까지 절대 해제하지 않는다.”
Rigorous Two-Phase Locking Protocol (준엄한 2단계 잠금)
트랜잭션이 획득한 모든 락(공유 S락, 배타 X락 모두) 을
커밋(commit) 또는 롤백(abort) 될 때까지 절대 해제하지 않는다.
Lock Conversion
S 락 → X 락 을 Lock 업그레이드 , X 락 → S 락 을 Lock 다운그레이드로 Lock Conversion (전환) 을 도입
X 락을 필요로 안하면 S 락으로 다운그레이드 가능 - Shrinking Phase 에서만 Read Operation 원활히 이루어짐
- Growing Phase
• can acquire a lock-S on item
• can acquire a lock-X on item
• can convert a lock-S to a lock-X (upgrade) - Shrinking Phase
• can release a lock-S
• can release a lock-X
• can convert a lock-X to a lock-S (downgrade)
Lock 의 자동 획득 및 구현
트랜잭션이 명시적 잠금 요청 없이 데이터를 읽거나 쓰는 경우 자동으로 잠금 요청을 처리한다.
Read - Lock 획득 과정
- 락을 가지고 있는지 확인
- 있으면 Read 진행
- 없으면 X 락을 기다리는 요청이 있으면
- S 락 허락 , Read 진행
Write - Lock 획득 과정
- X 락을 가지고 있는지 확인
- 있으면 write 진행
- 없으면 S 락을 가지고 있는지 확인
- 있으면 X 락으로 업그레이드
- 없으면 X 락 허락 , Write 진행
Implementation of Locking
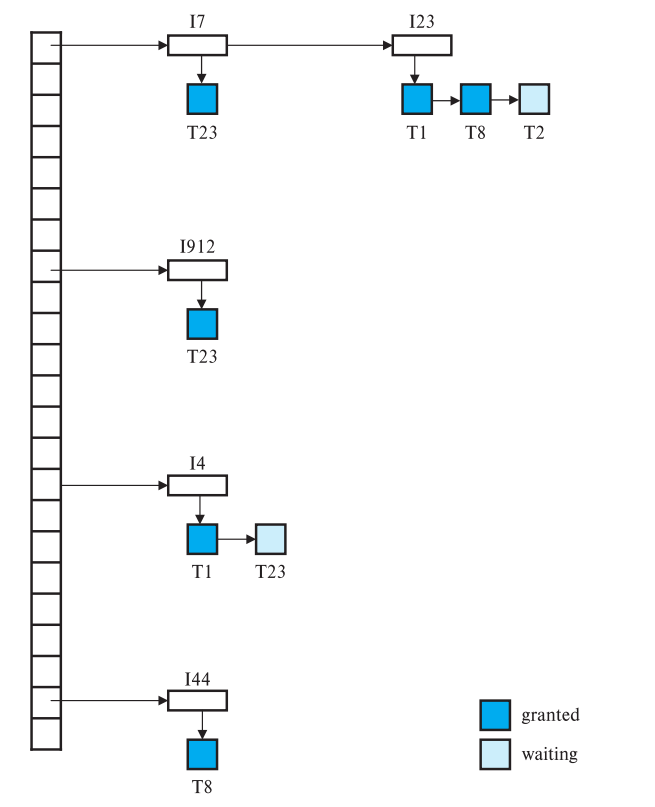
Granularity
무언가가 작고 개별적인 조각으로 구성된 정도
Deadlock Prevention
Lock 을 사용하는 순간 Deadlock 은 필요악 , 필수불가결 한 존재이다.
그러나 Deadlock 은 시스템 성능에 심각한 영향을 미치므로 이를 방지해야한다.
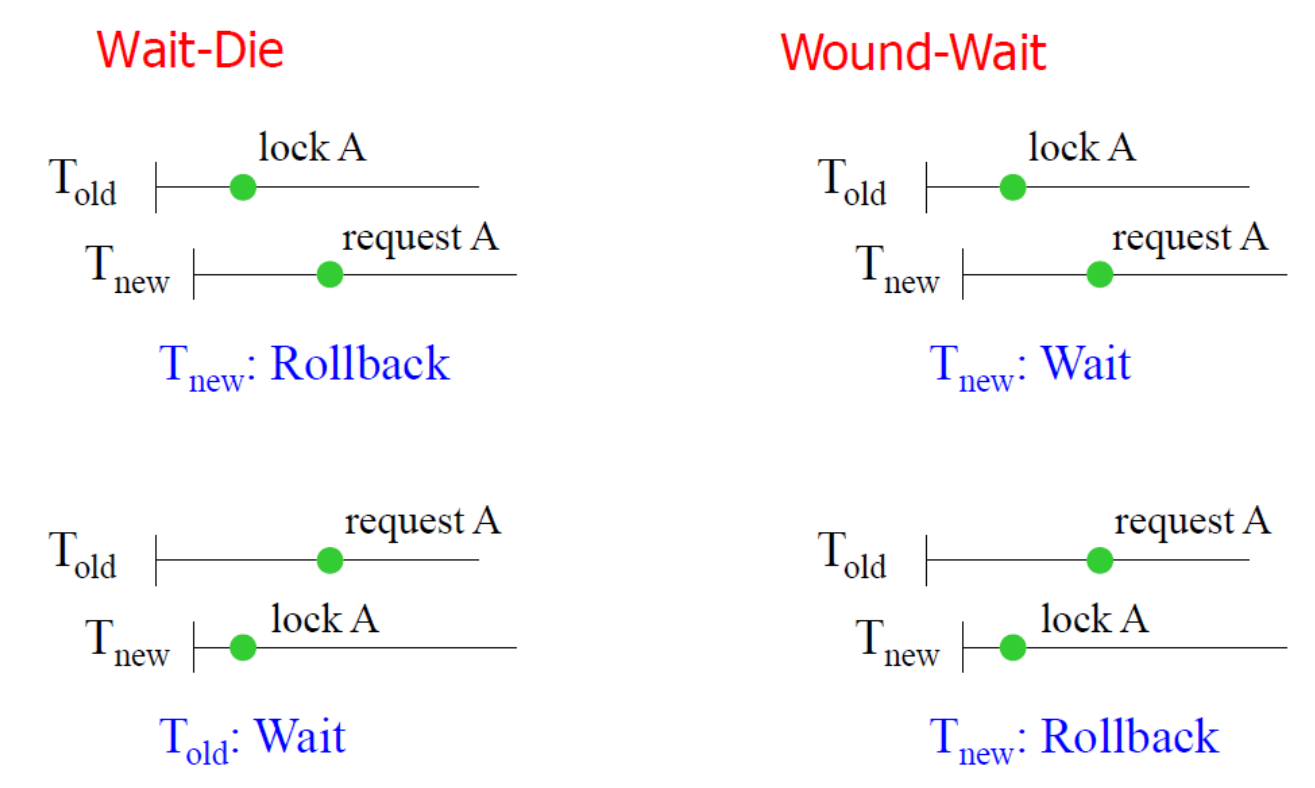
Wait - Die : Non-Preemptive (비강제적)
Old Transaction - Wait
New Transaction - Die
old 한 T 가 New T가 락을 내려놓기를 기다린다.
New T는 old T를 기다리지 않고 롤백된다.
Wound - wait : Preemptive (강제적)
New Transaction 자원을 기다리는 동안
Old Transaction 자원을 강제로 가져가게 된다.
새로운 트랜잭션은 롤백되어야 하며, 이로 인해 교착 상태가 발생할 수 있는
상황을 미리 방지할 수 있다.
T1: write(X) (자원을 점유)
T2: read(X) (T1이 자원을 점유하고 있으므로 대기)
Timeout-Based Schemes
일정시간이 지나면 락이 걸린걸 알아서 인지하고 롤백
적절한 Timeout Interval 을 찾는 것이 관건
Multiple Granularity (다중 수준 잠금)
데이터 항목을 다양한 크기로 분할하고, 그에 맞는 잠금 전략을 정의하는 방식
데이터 항목의 크기와 계층화 (Hierarchy of Data Granularities)
다양한 크기의 데이터 항목을 다룬다고 말하는데, 데이터는 트리 구조로 계층적으로 관리될 수 있다. 예를 들어, 데이터 항목을 파일, 테이블, 레코드, 컬럼, 셀과 같은 다양한 수준으로 구분할 수 있습니다.
이 트리 구조에서 상위 노드는 더 큰 범위의 데이터를 포함하고, 하위 노드는 더 세부적인 데이터 항목을 포함합니다.
명시적 잠금 (Explicit Locking)
트랜잭션이 트리의 특정 노드에 대해 명시적으로 잠금을 설정하면, 해당 노드의 하위 모든 노드들에 대해서도 자동으로 동일한 잠금 모드가 적용됩니다.
예를 들어, 테이블 수준에서 잠금을 설정하면, 그 테이블 내의 모든 레코드에 대해서도 동일한 잠금이 적용되는 것입니다.
잠금의 세분화 수준 (Granularity of Locking)
잠금은 트리에서 설정되는 수준에 따라 다르게 적용됩니다. 세부 수준에서 잠금을 설정할수록 잠금의 범위가 더 좁고, 상위 수준에서 잠금을 설정할수록 잠금의 범위가 넓습니다.
세밀한 잠금 (Fine Granularity)
트리에서 하위 수준의 노드에 잠금을 설정하면, high concurrency을 제공하지만, locking overhead가 많이 발생한다. 트랜잭션이 서로 다른 레벨에서 자원을 동시에 사용할 수 있어 성능이 높아지지만, 각 잠금의 관리가 복잡하고 비용이 커집니다.
굵은 잠금 (Coarse Granularity)
트리에서 상위 수준의 노드에 잠금을 설정하면, 잠금 오버헤드가 적지만 동시성은 낮아집니다. 즉, 자원을 더 적은 수준에서 잠그기 때문에 관리가 쉬운 대신 여러 트랜잭션이 동시에 자원을 사용할 수 있는 기회가 줄어든다
Granularity Hierachy
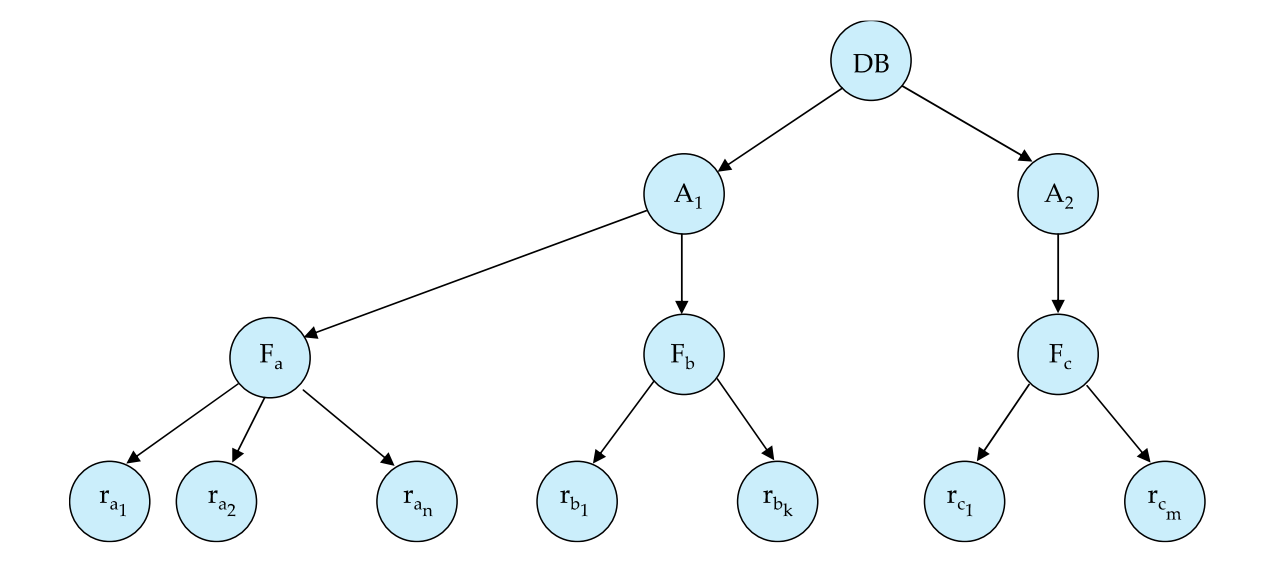
그림을 보면 위에서부터 상위 DB , Area (A) , File (F) , 하위 Record(F) 수준으로 나눈다.
여기서 상위 수준의 잠금을 설정할 때 하위 수준의 잠금에 대한 의도를 나타내는 잠금 모드가
Intention Lock 이다
Intention Lock
Intention Lock의 종류
Intention Shared Lock (IS):
IS 잠금은 공유 잠금(Shared Lock)을 설정하려는 트랜잭션이 상위 수준 노드에 설정한다. 이는 트랜잭션이 하위 수준의 여러 항목을 공유 모드로 잠글 의도가 있음을 나타낸다.
-> 즉, 여러 트랜잭션이 같은 자원에 대해 읽기만을 하도록 허용하는 의도를 표시합니다.
Intention Exclusive Lock (IX):
IX 잠금은 배타적 잠금(Exclusive Lock)을 설정하려는 트랜잭션이 상위 수준 노드에 설정한다. 이는 트랜잭션이 하위 수준의 항목에서 배타적 잠금을 설정할 의도가 있음을 나타낸다.
예를 들어, 트랜잭션이 특정 레코드를 쓰기 위해 잠글 수 있도록 허용하는 의도이다.
Shared Lock (S):
S 잠금은 다른 트랜잭션들이 데이터를 읽을 수 있도록 하지만, 쓰는 작업은 제한하는 잠금입니다.
Exclusive Lock (X):
X 잠금은 트랜잭션이 데이터를 수정할 때 사용되는 배타적 잠금으로, 다른 트랜잭션이 읽거나 쓰는 것을 모두 막습니다.
