statoil iceberg classifier-challenge
statoil iceberg classifier challenge
- 빙산을 가능한 한 빨리 감지하고 차별하는 방법을 찾기
- 원격으로 감지된 것이 선박인지 빙산인지 자동으로 식별하는 알고리즘 구축
- 결과 : 테스트 세트의 각 ID에 대해 이미지에 빙산이 포함될 확률 예측 (0~1 숫자)
📌 데이터 탐색 -> 모델 구성 -> 모델 훈련 -> 평가 -> 예측
1. 데이터 탐색
데이터 
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
#plt.rcParams['figure.figsize'] = 12, 8
%matplotlib inline
# notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해주는 것
#Take a look at a iceberg
# plotly -> 시각화 툴, matplotlib보다 더 세련된 데이터 시각화 툴
# 코드가 더 간결
import plotly.offline as py
import plotly.graph_objs as go
from plotly import tools#Ignore warnings
# 경고메시지 무시하고 숨기기
import warnings
warnings.filterwarnings('ignore')
py.init_notebook_mode(connected=True)
# plotly 를 jupyter notebook 에 사용하려면 이 커맨드를 입력해야 합니다7z 으로 압축되어 있기 때문에 이것을 풀어주어야 한다.
!pip install py7zr
import py7zr
import os
if not os.path.exists('/kaggle/train/') :
os.makedirs('/kaggle/train/')
if not os.path.exists('/kaggle/test/') :
os.makedirs('/kaggle/test/')
with py7zr.SevenZipFile("/kaggle/input/statoil-iceberg-classifier-challenge/train.json.7z", 'r') as archive:
archive.extractall(path="/kaggle/train")
with py7zr.SevenZipFile("/kaggle/input/statoil-iceberg-classifier-challenge/test.json.7z", 'r') as archive:
archive.extractall(path="/kaggle/test")
for dirname, _, filenames in os.walk('/kaggle'):
for filename in filenames:
print(os.path.join(dirname, filename))압축으로 풀어준 train, test data들을 각각 변수에 넣어준다.
train = pd.read_json('/kaggle/train/data/processed/train.json')
test = pd.read_json('/kaggle/test/data/processed/test.json')이것을 head()를 통해 보여줄 수 있다.
train.head()
# Bar Charts로 보여주기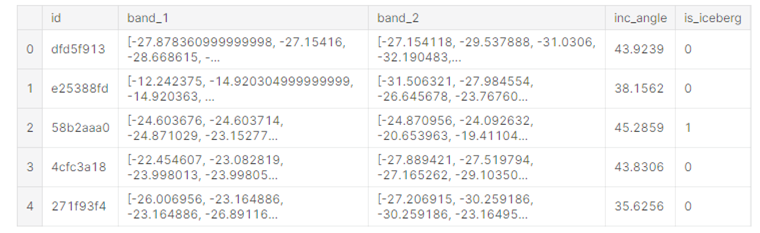
이를 통해 데이터에서 볼 수 있는 것을 알 수 있다.
=> id, band_1, band_2, inc_angle, is_iceberg
데이터
- id : 이미지의 ID
- band_1, band_2 : 위성에서 쏜 radar가 특정 object를 만나 튕겨서 다시 돌아오게 되는데 이를 이미지로 저장한 것 (이미지), 1과 2는 서로 각도가 다르다.
- inc_angle : 이미지가 촬영된 입사각, 훈련데이터에는 "na"로 표시도니 누락 데이터가 있다.
- is_iceberg : 목표 변수, 빙산 = 1, 선박 = 0 이며 train.json에만 존재한다.
전처리
train['inc_angle'].value_counts()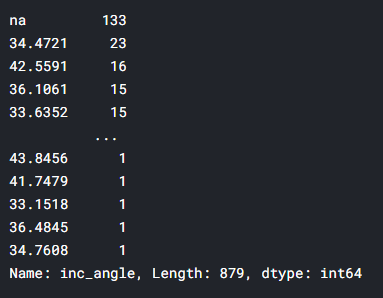
value_count()는 개수를 카운트 한다
ex ) A A A B B C --> A 3 B 2 C 1
"na"로 누락된 데이터를 0으로 바꾸어 준다.
train.inc_angle = train.inc_angle.replace('na',0)
train['inc_angle'].value_counts()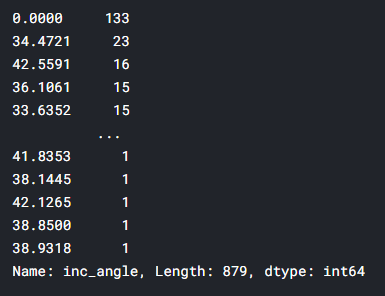
band_1 과 band_2가 HH,HV 2채널로 이루어져 있기 때문에 3채널로 만들어준다.
# reshape(75 ,75)=> 75개줄로 75개씩
X_band_1=np.array([np.array(band).astype(np.float32).reshape(75, 75) for band in train["band_1"]])
X_band_2=np.array([np.array(band).astype(np.float32).reshape(75, 75) for band in train["band_2"]])
#np.concatenate해서 새로운 채널을 하나더 만들어주는 것이다 컬러이미지이기 때문에
X_train = np.concatenate([X_band_1[:, :, :, np.newaxis], X_band_2[:, :, :, np.newaxis],((X_band_1+X_band_2)/2)[:, :, :, np.newaxis]], axis=-1)
#np.nexaxis = None, indexingㅇ로 길이가 1인 새로운 축 추가..?
X_band_test_1=np.array([np.array(band).astype(np.float32).reshape(75, 75) for band in test["band_1"]])
X_band_test_2=np.array([np.array(band).astype(np.float32).reshape(75, 75) for band in test["band_2"]])
X_test = np.concatenate([X_band_test_1[:, :, :, np.newaxis]
, X_band_test_2[:, :, :, np.newaxis]
, ((X_band_test_1+X_band_test_2)/2)[:, :, :, np.newaxis]], axis=-1)
데이터 확인
빙산일 때와 선박일 때 데이터가 어떻게 다른지 확인해 보아야 한다.
이때 0,1,3,4는 선박(0), 2번은 빙산(1)인 것을 확인할 수 있다.
시각화 하는 plot_contour_2d 함수를 만든다.
def plot_contour_2d(band1, band2, label):
fig = tools.make_subplots(rows=1, cols=2, specs=[[{'is_3d': True}, {'is_3d':True}]])
fig.append_trace(dict(type='surface', z=band1, colorscale='RdBu_r',
scene='scene1', showscale=False), 1, 1)
fig.append_trace(dict(type='surface', z=band2, colorscale='RdBu_r',
scene='scene2', showscale=False), 1, 2)
fig['layout'].update(title='3D surface plot for "{}" (left is from band1, right is from band2)'.format(label), titlefont=dict(size=30), height=800, width=1200)
py.iplot(fig)
#여기 밑에 부분은 이제 z축 없이 위에서 보는 부분 보여주는 코드
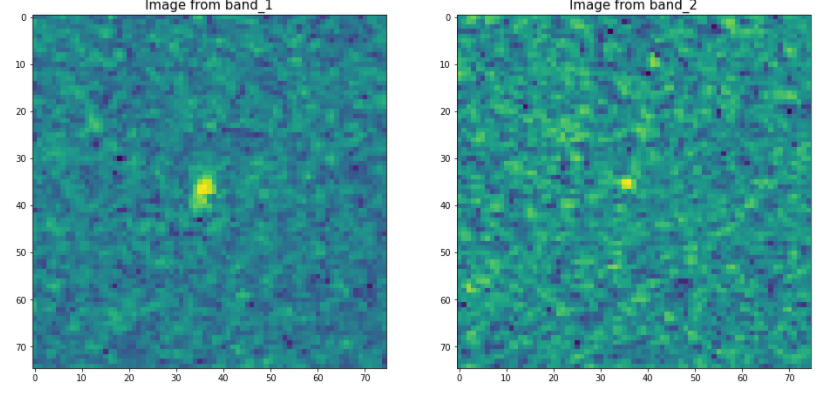
fig, ax = plt.subplots(1,2,figsize=(16,10))
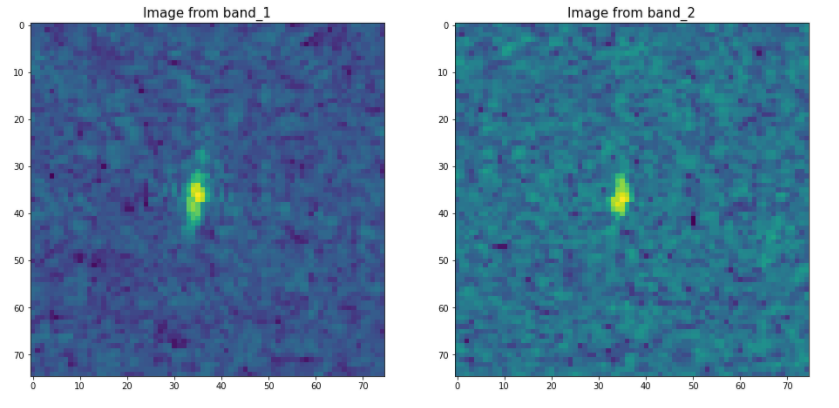
ax[0].imshow(X_band_1[num,:,:])
ax[0].set_title('Image from band_1', fontsize=15)
ax[1].imshow(X_band_2[num,:,:])
ax[1].set_title('Image from band_2', fontsize=15)
plt.show()위에서 확인했던 선박인 0번과 빙산인 2번을 확인해보자
num = 0
label = 'iceberg' if (train['is_iceberg'].values[num] == 1) else'ship'
plot_contour_2d(X_band_1[num,:,:], X_band_2[num,:,:], label)
num = 2
label = 'iceberg' if (train['is_iceberg'].values[num] == 1) else'ship'
plot_contour_2d(X_band_1[num,:,:], X_band_2[num,:,:], label)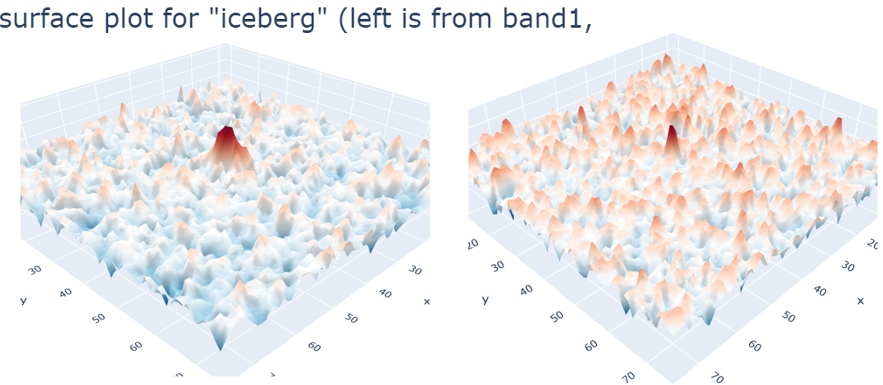
2. 모델 구성
먼저 Keras를 import 해준다.
#Import Keras.
from matplotlib import pyplot
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dense, Dropout, Input, Flatten, Activation
from keras.layers import GlobalMaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.layers.merge import Concatenate
from keras.models import Model
from keras import initializers
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint, Callback, EarlyStopping모델을 만들어 주는 함수를 만든다.
#define our model
def getModel():
#Building the model
gmodel=Sequential()
#Conv Layer 1
gmodel.add(Conv2D(64, kernel_size=(3, 3),activation='relu', input_shape=(75, 75, 3)))
# 64 = 컨볼루션 필터 수(연결되어있는 뉴런 수)
# relu = 0보다 작으면 0반환, 0보다 크면 그 값 그대로 반환
# 사이즈 75*75 컬러사진 ==> 3
gmodel.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# input size를 줄인다. 특징을 뽑아서
# overfitting 조절한다. 쓸데없는 파라미터 수 줄어들어서 train만 높은 성능x
# 특징 잘 뽑아낸다. pooling 했을 때 특정한 모양 더 잘 인식가능
gmodel.add(Dropout(0.2))
# overfitting해소, 일부로 덜 독똑하게 만든다
#Conv Layer 2
gmodel.add(Conv2D(128, kernel_size=(3, 3), activation='relu' ))
gmodel.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
gmodel.add(Dropout(0.2))
#Conv Layer 3
gmodel.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
gmodel.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
gmodel.add(Dropout(0.2))
#Conv Layer 4
gmodel.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
gmodel.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
gmodel.add(Dropout(0.2))
#Flatten the data for upcoming dense layers
gmodel.add(Flatten())
#Dense Layers
gmodel.add(Dense(512))
gmodel.add(Activation('relu'))
gmodel.add(Dropout(0.2))
#Dense Layer 2
gmodel.add(Dense(256))
gmodel.add(Activation('relu'))
gmodel.add(Dropout(0.2))
#Sigmoid Layer
#Adam 은 모델을 최적화 시켜주는 기능을 한다,
gmodel.add(Dense(1))
gmodel.add(Activation('sigmoid'))
mypotim=Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
gmodel.compile(loss='binary_crossentropy',
optimizer=mypotim,
metrics=['accuracy'])
gmodel.summary()
return gmodel
def get_callbacks(filepath, patience=2):
es = EarlyStopping('val_loss', patience=patience, mode="min")
msave = ModelCheckpoint(filepath, save_best_only=True)
return [es, msave]
file_path = ".model_weights.hdf5"
callbacks = get_callbacks(filepath=file_path, patience=5)이때 callback을 사용하여, loss가 더 줄지 않을 때 학습을 멈춰준다.
💡 EarlyStopping
: 더 이상 개선의 여지가 없을 때 학습을 종료시키는 콜백함수
- ‘val_loss’를 관찰한다.
- patience : 개선이 없다고 바로 종료 하지 않고 개선이 없는 에포크를 얼마나 기다려 줄 것인가
ex) patience = 10, 개선 없는 에포크 10번째 지속될 경우 학습 종료- mode : 관찰 대상에 대해 개선이 없다고 판단하기 위한 기준 지정
- min = 관찰하고 있는 항목이 감소되는 것을 멈출 때 종료
💡 ModelCheckpoint
: 모델을 저장할 때 사용되는 콜백함수
- filepath : 모델을 저장할 경로
- save_best_only : True, False
- True인 경우 ,monitor되고 있는 값을 기준으로 가장 좋은 값으로 모델 저장
- False인 경우, 매 에포크마다 모델이 filepath{epoch}으로 저장 (model0, model1, …)
3. 모델 훈련
target_train = train['is_iceberg']
X_train, X_valid, y_train, y_valid = train_test_split(X_train,
target_train,
random_state=1,
train_size = 0.8)
# train_test_split 으로 기존 train set을 train, vaild로 나누기gmodel=getModel()
gmodel.fit(X_train, y_train,
batch_size=24,
epochs=10,
verbose=1,
validation_data=(X_valid, y_valid),
callbacks=callbacks)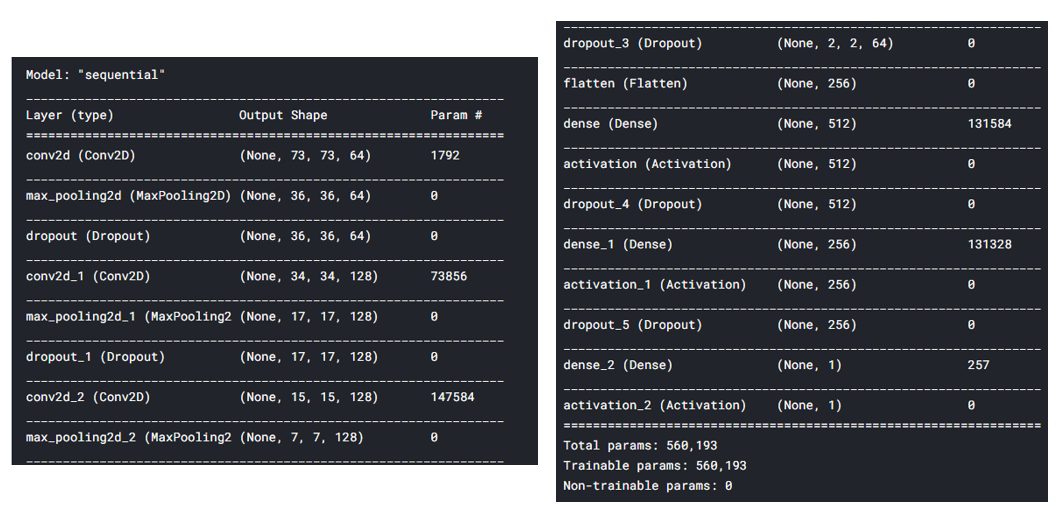
4. 평가
gmodel.load_weights(filepath=file_path)
score = gmodel.evaluate(X_valid, y_valid, verbose=1)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
5. 예측
predicted_test = gmodel.predict_proba(X_test)predicted_test
submission = pd.DataFrame()
submission['id']=test['id']
submission['is_iceberg']=predicted_test.reshape((predicted_test.shape[0]))
submission.to_csv('sub.csv', index=False)sub.csv 파일을 열어보면
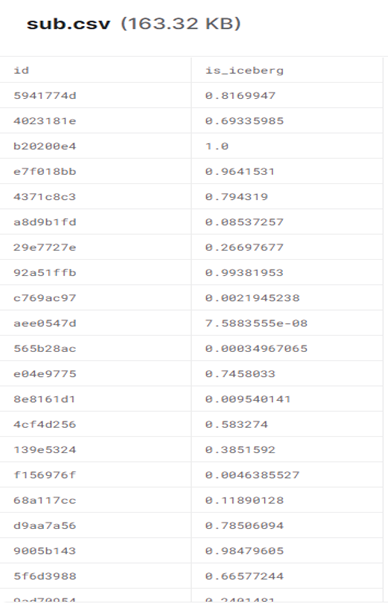
다음과 같은 값이 저장된다.
새로 알게 된 내용
-
시각화 툴 plotly, matplotlib보다 간결
-
콜백 함수 EarlyStopping : 더 이상 개선 여지없을 때 학습 종료
-
콜백 함수 : Modelcheckpoint : 모델 저장할 때 사용
피드백
모델을 극단적으로 바꾸어 봤을 때 어떤 변화?
- 레이어 수, 뉴런 수 조절하며 변화 보기
실행하는 것도 중요하지만 깊이 있게 분석
