
기본미션
교차 검증을 그림으로 설명하기
기존 4장 까지는 학습 시 학습세트와 테스트 세트만 사용하여 모델을 학습 후 확인 만 하였다. ML(Machine Learning)에서는 이런방식은 Best practice라고 할 수 없다.
머신 러닝도 학습이기 때문에 현실 공부를 예를 들어서 설명하고자 한다. 검증 세트 없이 평가하는 것은 공부를 하고 모의고사 안보고 바로 수능보기라고 이해하면 될 것 같다.따라서 잘 공부가 되었는지 확인하려면 모의고사를 통해서 공부를 잘했는지 확인해야 한다.
여기서 교차 검증은 다양한 모의고사 문제를 N번 풀어보는 것이다. 모의고사 문제가 항상 동일하다면 제대로된 학습평가라고 할 수 없기에 다양한 범위(좀 애매하긴한데...)에 대하여 학습 결과를 확인하여 잘 학습되었는지 확인하는 것이다.
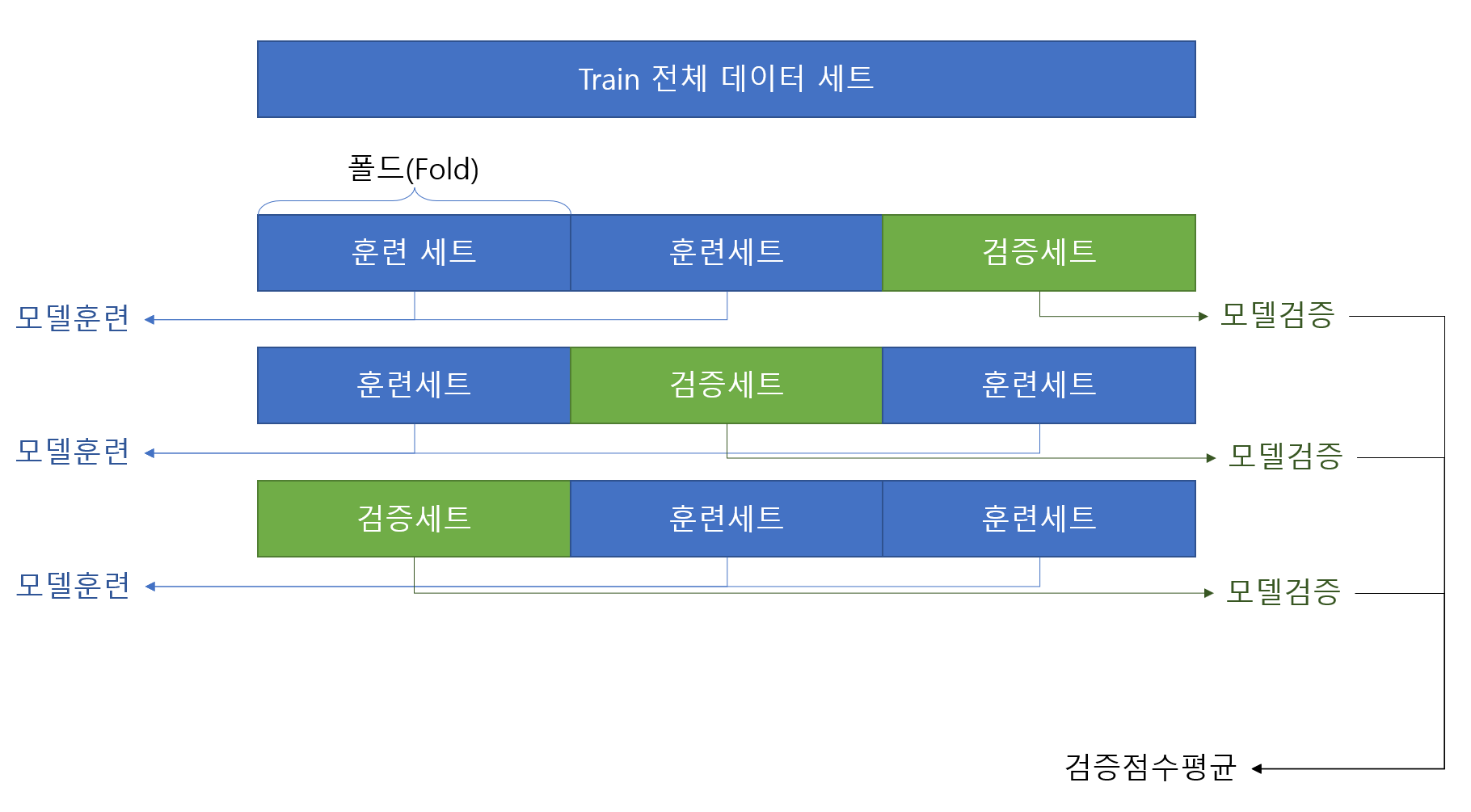
이 부분을 자동화 하여 제공한 module 이 cross_validate 이다.
from sklearn.model_selection import cross_validate
from pandas.core.common import random_state
from sklearn.model_selection import StratifiedKFold
#마지막 cv는 폴드 숫자로 StratifiedKFold 는 교차검증을 위한 폴드 분할기(splitter)이다.
scores= cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state= 42)
scores= cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))이런 교차 검증을 이용하여 모델의 최적의 하이퍼파라미터(책 248p 참고)를 탐색할 수 있다. 실제 학습의 예로 대입하여 보면 이것은 좋은 학원이나, 좋은 문제집을 찾는 과정이라고 이해해도 될 것 같다. 2가지 방식이 05-2장에 제시되어 있다.
1) GridSearchCV
from sklearn.model_selection import GridSearchCV
params={'min_impurity_decrease':np.arange(0.0001, 0.001, 0.0001),
'max_depth':range(5,20,1),
'min_samples_split':range(2,100, 10)}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(gs.best_params_)
print(dt.score(train_input, train_target))
print(np.max(gs.cv_results_['mean_test_score']))모든 경우의 수를 cross validation 해서 가장 좋은 하이퍼 파라미터를 찾아낸다. 시간이 많이 소요된다. colab 환경에서 약 31초 정도 소요되었다. 모델 평가 스코어는 0.89 정도
모든 문제집을 다풀어 보고 평가하면 시간도 오래 걸리겠지...
2) RandomizeSearchCV
params={'min_impurity_decrease':uniform(0.0001, 0.001),
'max_depth':randint(20,50),
'min_samples_split':randint(2,25),
'min_samples_leaf':randint(1,25)}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42,splitter='best'), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))적당히 샘플링된 하이퍼파라미터를 이용하여 cross_validate 하여 최적의 하이퍼파라미터를 찾는다. 비교적 적은 시간이 소요 되었다. colab에서 4초 정도 소요되었다. 모델 평가 스코어는 0.86
서점에서 몇개의 문제집을 샘플링해서 골라서 공부해보고 그나마 좋은 문제집을 찾는 과정이라고 보면된다.
선택미션
Ch.05(05-3)앙상블 모델 손코딩 코랩 화면 인증샷
앙상블(Ensemble) 참고할 사항
Bagging과 Boosting 계열로 나눌 수 있다.
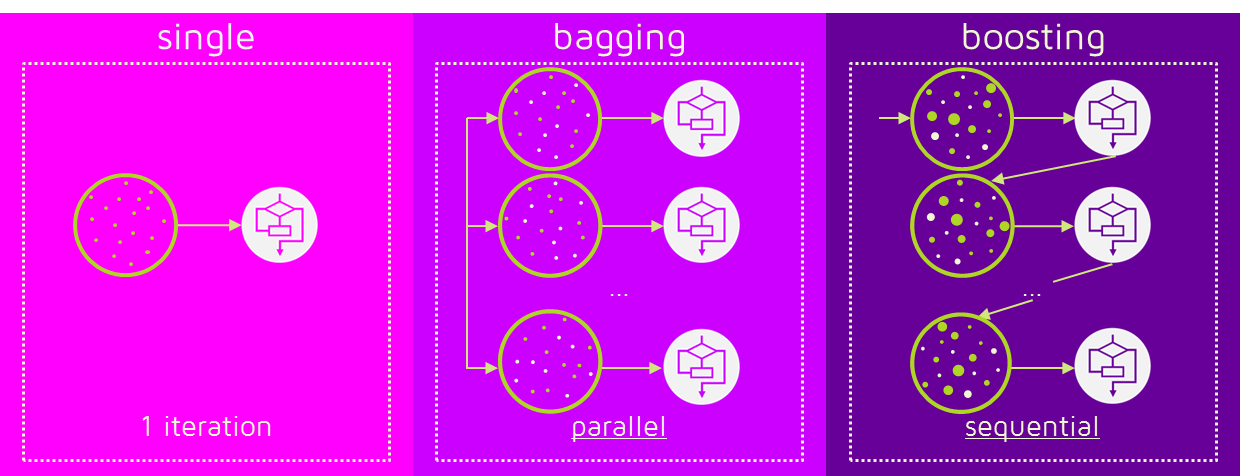 (출처-https://dokhakdubini.tistory.com/237)
(출처-https://dokhakdubini.tistory.com/237)
Gradient Boosting은 부스팅 하는 방식이 예측기(결정트리??)를 추가하는 방식으로 모델 학습을 한다. 평가하고 트리추가 요런 순서로 순차적으로 학습한다. (위의 그림에서 직관적으로 이해하기 살짝 어려운 것 같다. 위의 그림은 Adaboosting인 느낌..)
Bagging은 Bootstrap Aggregation의 약자라고 Bootstrap된 샘플(랜덤선택된) 샘플을 이용하여 병렬로 학습시켜서 만드는 모델이라고 이해하면 될 것 같다. 책의 266p를 보면된다.
