
기본미션
Ch.07(07-1) 확인 문제 풀고, 풀이 과정 정리하기
1.어떤 인공신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런의 갯수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개인가요?
✔1)1000개
2)1001개
3)1010개
4)1100개
모델파라미터는 학습을 통해서 결정되는 값이라고 보면된다. 예를 들어,로지스틱 회귀는 학습후 결정되는 기울기와 절편는 값이다.
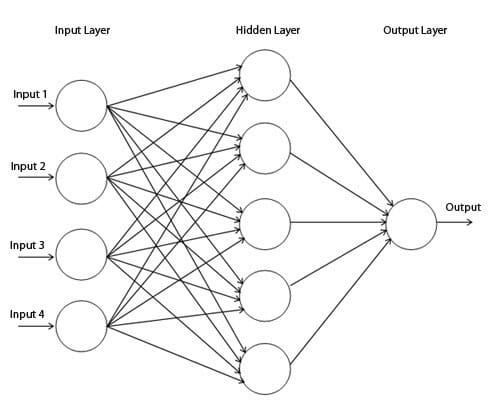
출처-ZDNet
밀집층(위 그림에서 Input Layer 와 Hidden Layer 노드의 관계)의 경우 입력특성과 결정된 뉴런의 갯수가 모두 연결되어 있으므로 100*10 으로 1000개의 파라미터가 된다.
2.케라스의 Dense를 사용해 신경망의 출력층을 만들려고 합니다. 이 신경망이 이진 분류 모델이라면 activation 매개변수에 어떤 활성화 함수를 지정해야 하나요?
1)'binary'
✔2)'sigmoid'
3)'softmax'
4)'relu'
2진 분류이기 때문에 0~1 사이에 확률로서 표현이 되는 sigmoid를 사용하면 된다.
3.케라스의 모델에서 손실 함수와 측정 지표등을 지정하는 메서드는 무엇인가요?
1)configure()
2)fit()
3)set()
✔4)compile()
Sequential로 모델을 구성한 이후 책에서 나온 메소드는 다음과 같다.
- compile - 모델을 훈련 시키기 전에 설정단계에서 사용, 손실 함수, 출력지표 등을 설정함
- fit - 실제로 데이터를 반영하여 훈련을 진행함
- evaluate - 검증 값으로 모델 훈련을 평가함
4.정수 레이블을 타깃으로 가지는 다중분류 문제일때 케라스 모델의 compile() 메서드에 지정할 손실 함수로 적절한 것은 무엇인가요?
✔1)'sparse_categorical_crossentropy'
2)'categorical_crossentropy'
3)'binary_crossentroypy'
4)'mean_square_error'
책 내의 설명은 다음과 같다.
- binary_crossentropy - 이진 분류인경우
- categorical_crossentropy - 다중 분류인경우
- sparse_categorical_crossentropy - 클래스 레이블이 정수일 경우 (다중 분류 중)
- mean_square_error - 회귀 모델일 경우
약간 문제가 혼란스러울 수 있는데 정수레이블 vs 원핫인코딩 된 레이블 이렇게 분류해서 생각하면된다.
분류 시 특정 레이블만 1로 표시 하도록 분류하는 것([0,0,1],[0,1,0],[1,0,0])이 one hot encoding 이고,
분류 시 1,2,3 처럼 분류하는 것이 문제에서 제시한 정수로 레이블 하는 것이라고 생각하면 된다.
선택미션
Ch.07(07-2) 확인 문제 풀고, 풀이 과정 정리하기
1.다음 중 모델의 add() 메서드 사용법이 올바른 것은 어떤 것인가요?
1) model.add(keras.layers.Dense)
✔2) model.add(keras.layers.Dense(10, activation='relu'))
3) model.add(keras.layers.Dense, 10, activation='relu')
4) model.add(keras.layers.Dense)(10, activation='relu')
이 부분은 실제로 동작해보면 다른 것들은 에러가 난다. Dense 층을 구성하고 그것을 모델에 추가하는 것이다. 출력갯수(뉴런갯수) 및 활성화 함수가 Dense의 파라미터 이다.
2.크기가 300*300 인 입력을 케라스 층으로 펼치려고 합니다. 다음 주 어떤 층을 사용해야 하나요?
1)Plate
✔2)Flatten
3)Normalize
4)Dense
책에서 설명이 되어 있다. Plate Layer는 없고 , Normalize 는 없고 Normalization 층이 있는데, 특정축으로 정규화(?-전체 구간을 0~1 사이의 값으로 맞춰줌)하는 유틸, Flatten은 1차원 배열로 펼쳐주는 기능이다.
3.다음 중 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는 무엇인가요?
1) linear
2) sigmoid
✔3) relu
4) tanh
이것도 책에 설명이 되어 있다.
4.다음 중 적응적 학습률을 사용하지 않는 옵티마이저는 무엇인가요?
✔1) SGD
2) Adagrad
3) RMSprop
4) Adam
적응형은 학습하면서 learing_rate가 변경되는 옵티마이져이다. SGD는 학습을 진행하면서 변경되지 않아서 적응형이 아니다.
