list
- list [] : 순서가 있는 수정이 가능한 데이터 타입이다.
✔ 리스트 안에는 다 들어갈 수 있음
ls = [1, 2, 'three', [4, 5], True, 3.14]
type(ls), ls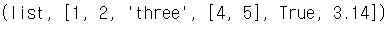
✔ append : 가장뒤에 값 추가, pop : 가장 마지막 데이터를 출력하고 출력한 데이터를 삭제, sort : 오름차순 정렬
ls = [1, 5, 2, 4]
ls.append(3)
print(ls)
ls.sort()
print(ls)
ls.pop()
print(ls)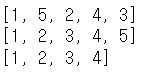
✔ 얕은복사 : 주소값을 복사하므로 복사본을 수정하면 원본도 바뀜
a = [1, 2, 3]
b = a # 얕은복사
b[0] = 7
print(a)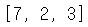
✔ 깊은복사 : 내부의 객체들까지 모두 새롭게 copy가 되는 것이다. 따라서 복사본을 수정해도 원본은 바뀌지 않는다. (copy.deepcopy메소드 사용)
import copy
a = [[1,2], [3,4]]
b = copy.deepcopy(a)
b[1].append(5)
print(a)
print(b)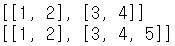
✔ 문자열 리스트로 만들기
s = 'abcde'
tmp = list(s)
print(tmp) # ['a','b','c','d','e'] 출력tuple
-
tuple () : 순서는 있지만 수정이 불가능한 데이터 타입이다.
-
튜플은 같은 데이터를 가졌을때 리스트보다 공간을 적게 사용한다.
✔ 튜플 생성시 ()를 쓰지 않아도 된다.
tp1 = 1, 2, 3
tp2 = (4, 5, 6)
type(tp1),type(tp2),tp1,tp2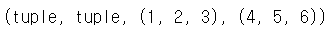
dict
- dict {} : 순서가 없고 { key : value }로 구성되어 있는 데이터 타입이다.
✔ 키는 정수, 문자열 데이터 타입만 사용 가능하다.
dic = { 1 : 'one',
'two' : 2,
'three' : [1, 2, 3]
}
dic['two'], dic[1]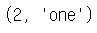
✔ dic.keys(), dic.values(), dic.items()
for x, y in dic.items():
print(y)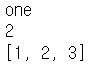
set
-
중복을 허용하지 않는다.
-
순서가 없다.(인덱싱 불가)
-
교집합, 합집합, 차집합을 구할 때 아주 유용하게 사용된다.
✔ 기본사용 방법
s1 = set( [1, 2, 3] )
print(s1)
s2 = set('Hello')
print(s2)
✔ 교집합(&) 또는 intersection사용
s1 = set( [1,2,3,4,5,6] )
s2 = set( [4,5,6,7,8,9] )
s1 & s2 # {4, 5, 6} 출력
s1.intersection(s2) # {4, 5, 6} 출력✔ 합집합(|) 또는 union사용
s1 | s2 # {1,2,3,4,5,6,7,8,9} 출력
s1.union(s2) # {1,2,3,4,5,6,7,8,9} 출력✔ 차집합(-) 또는 difference사용
s1 - s2 # {1,2,3} 출력
s2.difference(s1) # {8,9,7} 출력✔ 값 1개 추가하기(add)
s1 = set()
s1.add(7)
s1 # {7} 출력✔ 값 여러개 추가하기(update)
s1 = set()
s1.update( [2,1,5,4] )
s1 # {1,2,4,5} 출력✔ 특정 값 제거하기(remove)
s1 = set()
s1.update( [2,1,5,4] )
s1.remove(2)
s1 # {1,4,5} 출력
Study note