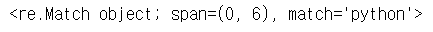
문자클래스 []
[abc]
-
[]사이의 문자들과 매치하는지 확인한다.
-
"a"는 정규식과 일치하는 문자인 "a"가 있으므로 매치함
-
"before"는 정규식과 일치하는 문자인 "b"가 있으므로 매치함
-
"dude"는 정규식과 일치하는 문자인 a, b, c중 어느 하나도 포함하고 있지 않으므로 매치되지 않음
-
하이픈을 사용하여 From-To로 표현 가능
ex) [a-c] = [abc], [a-zA-Z] = 알파벳 모두, [0-5] = [012345]
-
[]안에 ^를 사용할 경우 반대(not)라는 의미를 갖는다.
ex) [^0-9] = 숫자가 아닌 문자
자주 사용하는 문자 클래스
-
\d : [0-9]와 동일한 표현식, 숫자인 것
-
\D : [^0-9]와 동일한 표현식, 숫자가 아닌 것
-
\s : whitespace문자와 매치, 즉 공백을 의미한다.
-
\S : whitespace문자가 아닌것과 매치, 즉 공백이 아닌것을 의미한다.
-
\w : 알파벳, 숫자, _ 와 일치하는 것, [a-zA-Z0-9_]과 동일한 표현식
-
\W : 알파벳, 숫자, _ 가 아닌것, [^a-zA-Z0-9_]과 동일한 표현식
Dot(.)
a.b
-
줄바꿈(\n)을 제외한 모든 문자와 매치한다.
-
'abc'는 가운데 문자 'a'가 모든 문자를 의미하는 '.'과 일치하므로 정규식과 매치한다.
-
'a0b'는 가운데 문자 '0'이 모든 문자를 의미하는 '.'과 일치하므로 정규식과 매치한다.
-
'abc'는 'a'문자와 'b'문자 사이에 어떤 문자라도 하나는 있어야 하는 이 정규식과 일치하지 않으므로 매치되지 않는다.
반복(*)
ca*t
-
앞글자가 0번이상 반복되는 표현식 이다.
-
'ct'는 'a'가 0번 반복되므로 매치된다. ( 0번도 포함됨 )
-
'cat'는 'a'가 1번 반복되므로 매치된다.
-
'caaat'는 'a'가 3번 반복되므로 매치된다.
반복(+)
ca+t
-
앞글자가 1번이상 반복되는 표현식 이다.
-
'ct'는 'a'가 0번 반복되므로 매치되지 않는다. ( * 와의 차이점 )
-
'cat'는 'a'가 1번 반복되므로 매치된다.
-
'caaat'는 'a'가 3번 반복되므로 매치된다.
반복{m, n}
ca{2}t
-
앞글자가 2번만 반복되는 것을 찾는다.
-
'cat'는 'a'가 1번만 반복되어 매치되지 않는다.
-
'caat'는 'a'가 2번 반복되어 매치된다.
ca{2,5}t
-
앞글자가 2이상 5이하번 반복되는 것을 찾는다.
-
'cat'는 'a'가 1번만 반복되어 매치되지 않는다.
-
'caat'는 'a'가 2번 반복되어 매치된다.
-
'caaaaat'는 'a'가 5번 반복되어 매치된다.
반복(?)
ab?c
-
?는 앞글자가 0회 또는 1회 반복인 것을 찾는다.
-
'abc'는 'b'가 1번 사용되어 매치된다.
-
'ac'는 'b'가 0번 사용되어 매치된다.
정규표현식
- 정규표현식을 지원하는 re모듈을 import 해야 한다.
import re
p = re.compile('ab*')
m = p.match('python')
print(m)-
패턴객체(p)를 만들고 이것을 이용해 다른 문자열과 비교해볼 수 있다.
-
패턴객체를 이용하는 방법은 4가지(Match, Search, Findall, Finditer)가 있다.
Match
-
문자열의 처음부터 정규식과 매치되는지 조사한다.
-
match객체의 메서드는 4가지(group, start, end, span)가 있다.
- group() : 매치된 문자열을 리턴한다.
- start() : 매치된 문자열의 시작 위치를 리턴한다.
- end() : 매치된 문자열의 끝 위치를 리턴한다.
- span() : 매치된 문자열의 (시작, 끝)에 해당되는 튜플을 리턴한다.
✔ m이라는 match객체를 생성한다.
import re
p = re.compile('[a-z]+') # 소문자가 1번이상 반복되는지
m = p.match('python3')
print(m) # 매치된다
m = p.match('3python')
print(m) # 매치되지 않는다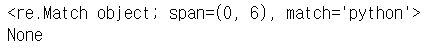
✔ match객체의 4가지 메서드
import re
p = re.compile('[a-z]+')
m = p.match('python')
print(m.group())
print(m.start())
print(m.end())
print(m.span())
Search
- 문자열 전체를 검색하여 정규식과 매치되는지 조사한다.
✔ m이라는 search객체를 생성한다.
import re
p = re.compile('[a-z]+')
m = p.search('3python')
print(m)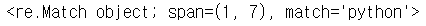
findall
- 정규식과 매치되는 모든 문자열을 리스트로 돌려준다.
✔ m이라는 findall객체를 생성한다.
import re
p = re.compile('[a-z]+')
m = p.findall('life is too short')
print(m)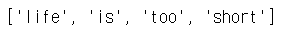
finditer
- 정규식과 매치되는 모든 문자열을 반복 가능한 match객체형태로 반복가능한 객체 하나로 돌려준다.
✔ m이라는 finditer객체를 생성한다.
m = p.finditer('life is too short')
print(m)
for x in m:
print(x)
컴파일 옵션
-
정규식을 컴파일할 때 다음 옵션을 사용할 수 있다.
-
DOTALL, S : . 이 줄바꿈(\n)문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
-
IGNORECASE, I : 대소문자에 관계없이 매치할 수 있도록 한다.
-
MULTILINE, M : 여러줄과 매치할 수 있도록 한다.
-
VERBOSE, X : verbose 모드를 사용할 수 있도록 한다. (정규식을 보기 편하게 만들수 있고 주석등을 사용할 수 있게 된다.) ( 긴 정규표현식을 나눠서 쓸 수 있게 만들어 준다. )
✔ 보통 re.DOTALL 옵션은 여러 줄로 이루어진 문자열에서 \n에 상관없이 검색할 떄 많이 사용한다.
import re
p = re.compile('a.b' , re.DOTALL)
m = p.match('a\nb')
print(m)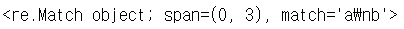
✔ [a-z]+ 정규식은 소문자만을 의미하지만 re.I 옵션으로 대소문자 구별 없이 매치된다.
p = re.compile('[a-z]+')
m = p.match('Python')
print(m)
p = re.compile('[a-z]+', re.I)
m = p.match('Python')
print(m)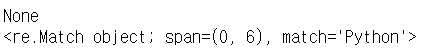
✔ ^ 는 문자열의 처음을 의미, $ 는 문자열의 마지막을 의미한다.
import re
p = re.compile('^python\s\w+')
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data))
✔ MULTILINE 실습 - ^ab 인 경우 문자열의 처음은 항상 ab로 시작해야하고, xy$ 인 경우 문자열의 마지막은 항상 xy로 끝나야 매치된다는 의미이다.
import re
p = re.compile('^python\s\w+', re.M)
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data))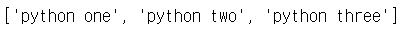
✔ VERBOSE 실습
import re
charref = re.compile(r'&[#](0[0-7]+|[0-9]+|x[0-9a-fA-F]+);')
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)백슬래시 문제
-
정규표현식에서 r''의 의미
-
정규패턴식 앞에 r이 붙어 있는 경우가 많다. 파이썬 정규식에는 Raw string이라고 해서, 컴파일 해야 하는 정규식이 Raw String(순수한 문자)임을 알려줄 수 있도록 문법이 있다.
-
만약 p = re.compile('\section') 이라고 쓴다면 \s는 공백문자를 의미하는 [ \t\n\r\f\v]이 되어버려서 원하는 결과를 찾지 못한다.
-
그래서 이스케이프 \를 활용해 \section이라고 해주면 되지만, 파이썬은 특수하게 r을 사용하면 백슬래쉬를 1개만 써도 두개를 쓴 것과 같은 효과를 갖는다.
