
논문
https://arxiv.org/pdf/2005.14165.pdf
Github
https://github.com/openai/gpt-3
이 논문은 GPT-3에 대한 논문입니다.
등장 배경
GPT-3는 아래와 같은 기존 모델들의 한계점들을 해결하기 위해 제안되었습니다.
-
자연어의 각 task에 대한 대용량의 라벨링된 데이터가 필요하다는 것은 언어 모델의 적용 가능성을 제한시킵니다.
-
사전 학습된 모델을 다시 미세 조정 시키는 것은 매우 협소한 task에 대해 미세 조정되는 것입니다.
-
사람의 학습법과 비슷하게, 적은 데이터를 이용하여 충분히 학습 가능합니다. 즉, 다양한 자연어 관련 task들과 skill들을 잘 섞어서 이용하는것이 더 효과적입니다.
해결 방법
-
GPT 시리즈에서 제안된 내용과 동일하죠. 라벨링되지 않은 대규모 데이터를 이용하여 학습합니다.
-
GPT-2에서와 유사하죠. 미세 조정을 하지 않고, 사전 학습만으로도 충분히 좋은 결과를 낼 수 있도록 학습하였습니다. 그만큼 데이터 량도 어마어마하게 증가하였죠.
-
이 부분은 Few-shot learning을 통해 해결하려고 하였습니다.
※ 미세 조정을 왜 없앤건가요?
한번 사전 학습된 모델을 다시 미세 조정 한다는 것은 시간도, 비용도 많이 드는 방법입니다. 또한 이미 미세 조정한 모델은 해당 task외에는 사용할 수 없다는 문제점이 존재합니다. 따라서 이러한 단점을 보완하고자 미세 조정 단계를 없앤것입니다.
※ Few-Shot Learning이 뭐죠?
few-shot learning이란 적용하고 싶은 task에 대한 데이터 10~100개 정도를 사용해서 모델에 알려준 뒤, 원하는 결과를 얻어내는 것을 뜻합니다. 예를 들어 사전 학습시킨 모델에게 강아지 사진 100장을 보여주며 "이게 강아지야!" 라고 알려주고, 새로운 강아지 사진을 주면서 이게 뭐냐고 물어보는것과 같죠. 이때 가중치 업데이트는 되지 않습니다!!
※ One-shot, Zero-Shot?
one-shot learning은 단 1가지의 예시를 이용하는것이고, zero-shot learning은 단 1개의 예시도 없이 모델을 바로 task에 사용하는 방법입니다. GPT-2의 실험을 보시면, 모두 zero-shot결과입니다.

모델 구조
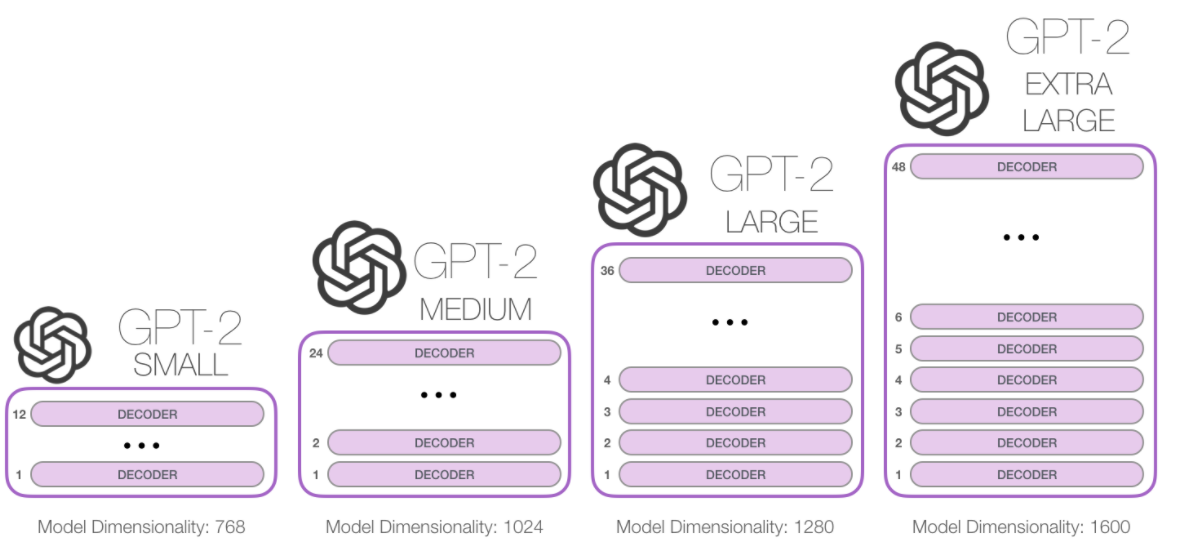
GPT-3역시 구조 보다는 어떻게 학습하냐를 더 중요시 여겼습니다. 자세한 구조는 Transformer를 참고해주세요. GPT-2구조와 동일합니다.
학습 방법
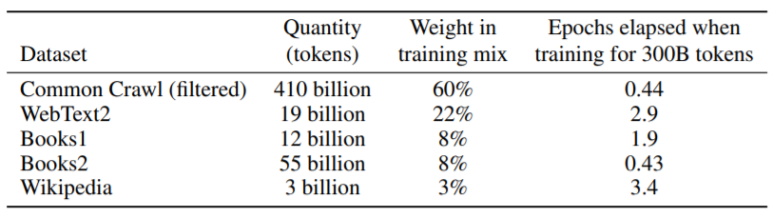
먼저 학습 전 데이터셋에서 잠시 말씀드리자면, GPT-2에 사용되었던 데이터보다 훨씬 많은 데이터를 이용하여 학습시켰습니다. 무려 570GB정도의 corpus가 사용되었다고합니다.
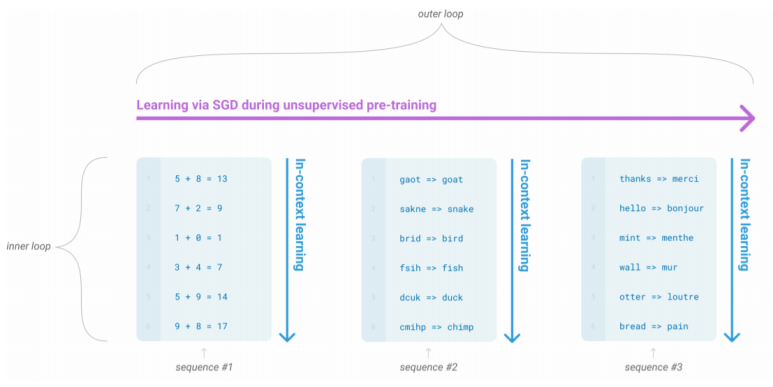
학습을 진행하면서 동시에 few-shot learning으로 사칙 연산, 오타 검색, 번역 등의 다양한 패턴 인지 능력을 학습시켰습니다. 아래 그림의 각 sequence는 전체 학습을 시킬 동안 내부적으로 반복 과정을 통해 학습합니다. 예를 들어서, 모델의 입력으로 긍정 또는 부정을 판별하는 주제에 대한 예제들을 입력해주면, 이 규칙을 파악하고 추론해야 하는 문제를 예제처럼 풀게 됩니다. 이를 문맥 내 학습(in-context learning)이라고 합니다. 이것의 장점은 다양한 task들에 대해서 적은 수의 데이터를 가지고 학습하는 능력을 가진다고 합니다.
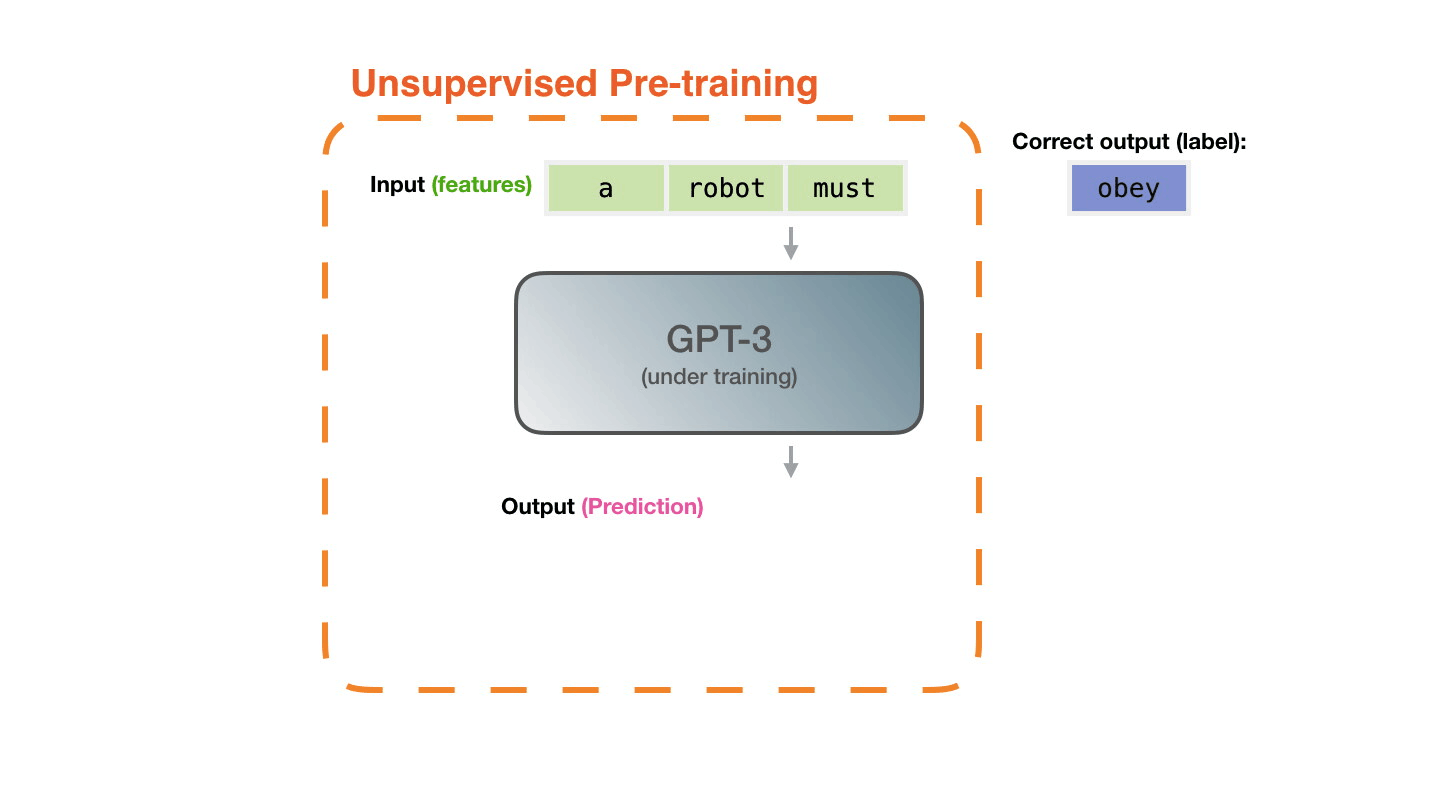
GPT-3의 학습 방법은 아래와 같습니다. GPT-2와 크게 다를 부분은없습니다.
결과
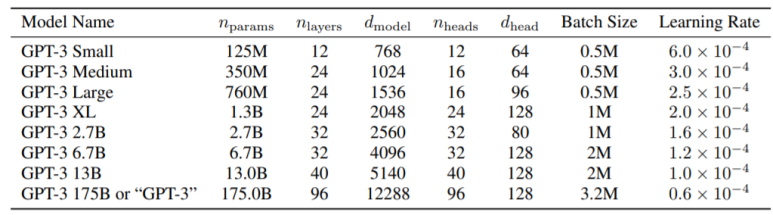
아래의 표는 각 파라미터수와, 계층 수, 입력 차원수를 나타냅니다.
GPT-3를 적용시킨 task는 정많많습니다.
(1) LAMBADA
문장 완성 task, 장기의존성을 모델링하는 task입니다.
(2) StoryCloze
다섯 문장의 긴 글을 끝맺기 적절한 문장을 고르는 task입니다.
(3) HellaSwag
짧은 글이나 지시사항을 끝맺기 가장 알맞은 문장을 고르는 task입니다.
위의 3가지 task에 대한 결과 표입니다.
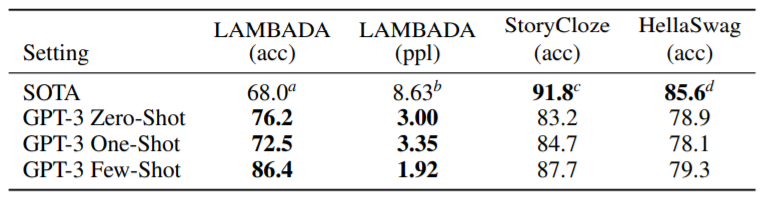
StoryCloze에서 zero-shot으로 비교했을 경우에는 10%넘게 더 높은 성능이 나왔다고 합니다.
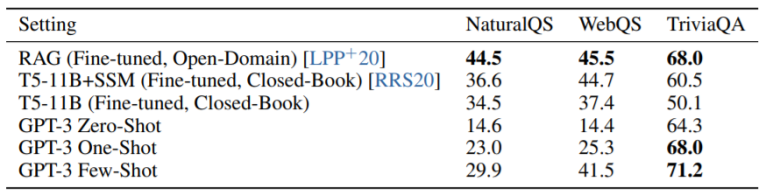
(4) TriviaQA
(5) WebQuestions
(6) Natural Questions
위의 세 가지 task들은 모두 폭넓은 지식에 대한 질문에 답변 하는 task입니다.
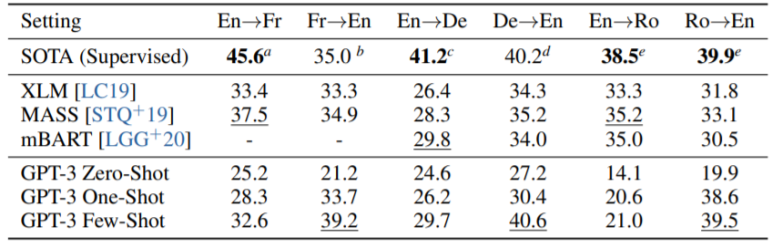
(7) Translation
번역하는 능력을 측정하는 task입니다.
(8) Winograd
대명사 지칭 문제입니다.
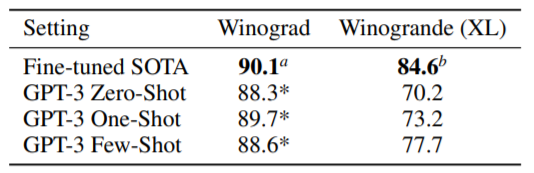
(9) PIOA
(10) ARC
(11) OpenBookQA
상식에 관련된 질문-응답을 하는 task입니다.
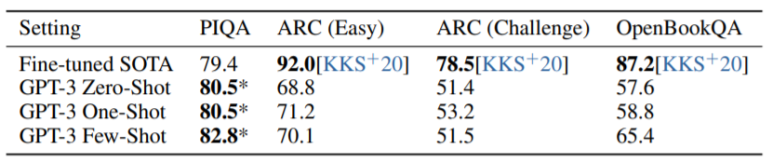
(12) CoQA
(13) DROP
(14) QuAC
(15) SQuADv2
(16) RACE
기계 독해 관련 task입니다.
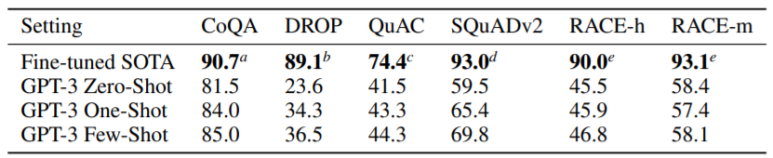
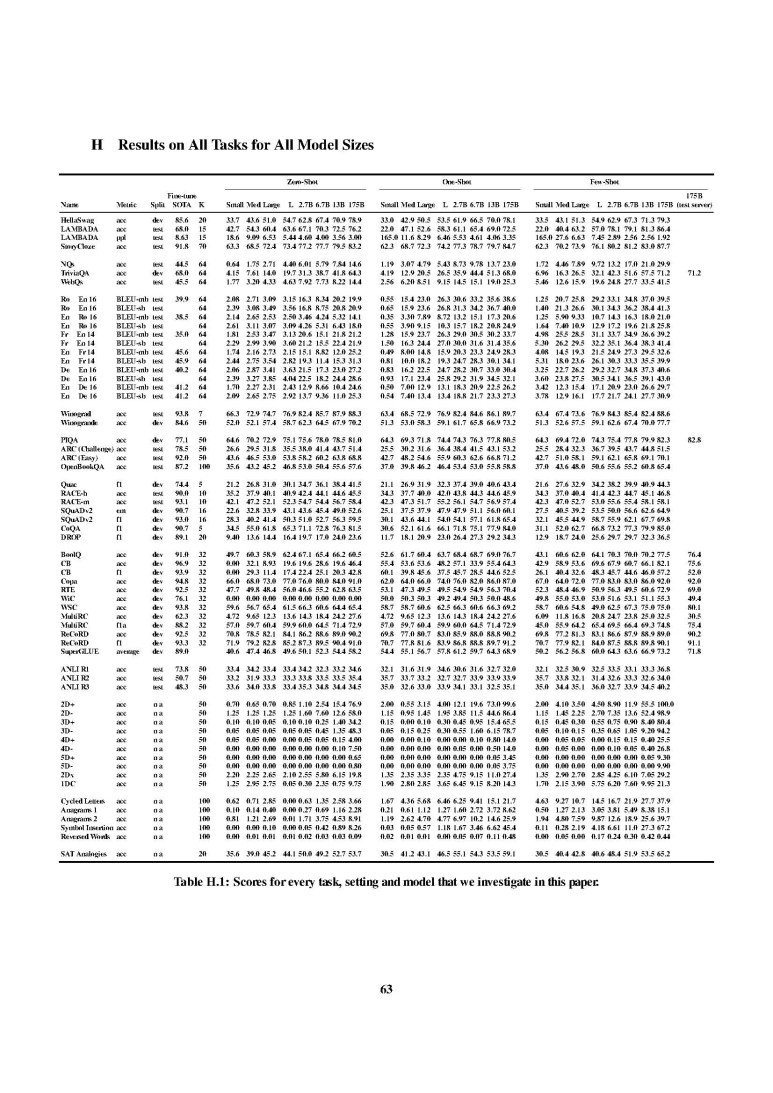
이 외에도 정말 많은 task들에 적용되었습니다. 아래의 표를 첨부하겠습니다.
결론
GPT-2보다 더 많은 데이터 량과 Few-Shot Learning을 이용하여, 더 범용적인 모델을 만들었습니다. 실제로 24개가 넘는 task에서 적용되었다고합니다.
