
▶텍스트 분류
앞의 포스팅에서도 작성했듯, 자연어 처리 기술을 활용해 글의 정보를 추출하고, 문제에 맞게 사람이 정한 범주(Class)로 분류하는 문제입니다. 이번 포스팅에서는 영어로 구성된 영화 감상평을 보고, 긍정인지 부정인지 분류해보겠습니다.
▶사용할 데이터
Bag of Words Meets Bags of Popcorn데이터입니다. 이 데이터셋은 인터넷 영화 데이터베이스(IMDB)에서 나온 영화 평점 데이터를 활용한 캐글 문제입니다. 각 데이터는 영화 리뷰 텍스트와 평점에 따른 감정(긍정 혹은 부정) 값으로 구성되어있습니다.
▶데이터 처리 과정
첫 번째 과정은 데이터를 불러오고, 정제되지 않은 데이터를 활용하기 쉽게 전처리하는 과정입니다. 두 번째 과정은 데이터를 분석하는 과정이고, 마지막 과정은 실제 문제를 해결하기 위해 알고리즘을 모델링하는 과정입니다.
(1) 데이터 분석
먼저 데이터를 불러온 뒤, 데이터의 구조, 데이터의 개수, 문장 길이 히스토그램, 라벨의 분포 등을 통해 데이터를 파악합니다.
(2) 데이터 전처리
리뷰 데이터 속에 존재하는 "
", "\","..."같은 특수문자 혹은 HTML태그를 제거합니다. 이후에는 조사, 관사 등 불용어를 제거해줍니다. 또한 모델에 입력으로 넣어주기 위해서는 자연어로 표현된 데이터를 수치값으로 바꿔줘야합니다. 문장의 길이는 모두 다르기 때문에, 통일 시켜주기 위해서, 짧은 데이터의 경우 0 값으로 패딩하는 작업을 진행합니다.
→경우에 따라 불용어가 포함된 데이터를 모델링하는 데 있어 노이즈를 줄일 수 있는 요인이 될 수 있기 때문에, 불용어를 제거해주는 것이 더 좋을 수 있습니다. 하지만, 데이터가 많고, 문장 구문에 대한 전체적인 패턴을 모델링하고자 한다면 불용어를 제거하지 않는 것이 좋습니다.
(3) 모델링
전처리된 데이터를 모델에 적용하고, 주어진 텍스트에 대해 감정이 긍정인지 부정인지 예측할 수 있는 모델을 만드는 것입니다. 모델은 선형 회귀, 랜덤 포레스트, 합성곱 신경망(CNN), 순환 신경망(RNN)모델에 대해 설명하겠습니다.
① 회귀 모델
선형 회귀 모델은 하나의 선형 방정식으로 표현해 예측할 데이터를 분류하는 모델입니다. 예를들어 <그림1>과 같은 데이터가 주어졌을때, 이 데이터를 2개의 범주로 분류해야합니다. 이때 하나의 직선으로 데이터를 구분하면 <그림2>와 같이 직선으로 표현할 수 있습니다.
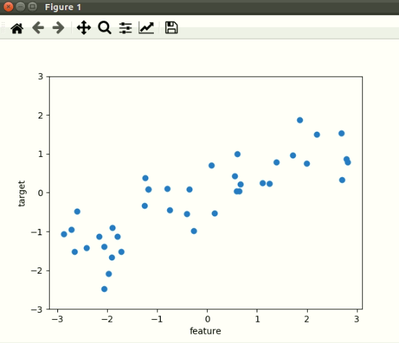
<그림1>
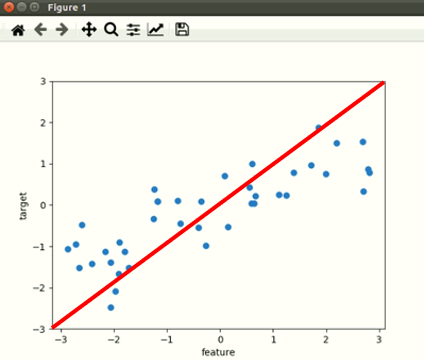
<그림2>
로지스틱 회귀 모델은 주로 이항 분류를 하기 위해 사용되는 가장 간단한 모델입니다. 위의 선형 회귀 모델의 결괏값에 로지스틱 함수를 적용하여 0~1사이의 값을 갖게한 뒤, 확률로 표현합니다. 이렇게 나온 결과를 통해 1에 가까우면 정답이 1, 0에 가까우면 정답이 0이라고 예측합니다.
② 랜덤 포레스트 분류 모델
랜덤 포레스트에서는 여러 개의 의사결정 트리의 결괏값을 평균낸 것을 결과로 사용합니다. 랜덤 포레스트를 통해 분류 혹은 회귀를 할 수 있습니다. 랜덤 포레스트를 알기 전, 의사결정 트리에 대해서 먼저 알아야 합니다. 의사 결정 트리는 자료구조 중 하나인 트리 구조 형태를 가지는 알고리즘입니다. 트리 구조의 형태에서 각 노드는 하나씩 질문이 되고, 질문에 따라 다음 노드가 달라지며, 몇 개의 질문이 끝난 후 결과가 나오는 형태입니다. 예를 들어서 설명하겠습니다.
아래의 4문장 중 고양이와 관련된 문장을 찾아야 한다고 하면, 의사 결정 트리는 <그림3>과 같이 구성될 수 있습니다.
-
고양이는 너무 귀여워
-
우리 강아지는 애교쟁이야
-
내 친구는 너무 예뻐
-
오늘 도서관에 갈 예정이야
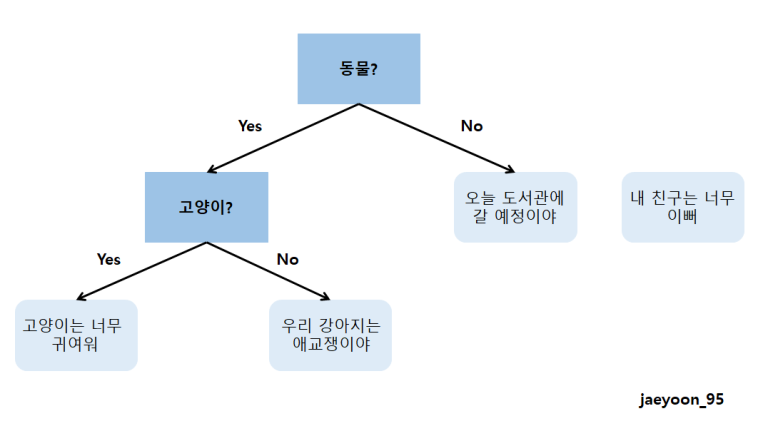
<그림3>
랜덤 포레스트는 위와 같은 트리 구조가 모여있는 형태입니다. 각 트리에서 구한 결과를 종합한 뒤, 결과를 도출하는 방법입니다. 즉, 많은 트리를 함께 사용함으로써 정확도를 높여주는 모델입니다. 이는 <그림4>와 같습니다.
<그림4>
③ 순환 신경망 분류 모델
순환 신경망(RNN)은 현재 정보가 이전 정보에 영향을 주며, 점층적으로 정보를 쌓아 표현할 수 있는 모델입니다. 따라서 시간에 의존적인 순차적 데이터에 대한 문제에 많이 활용됩니다. 이는 <그림5>와 같습니다.
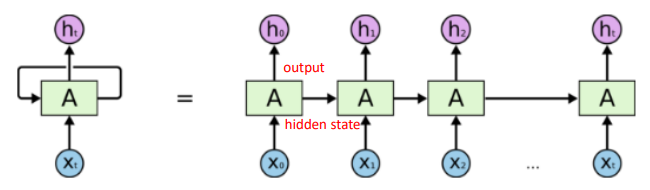
<그림5>
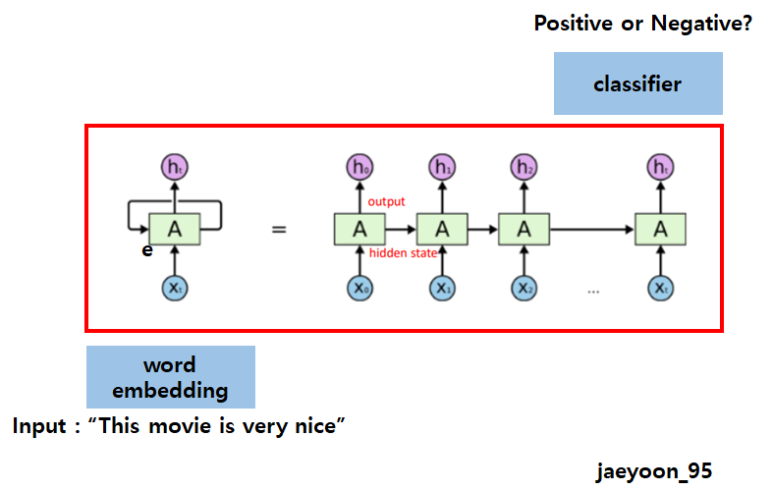
<그림6>
앞의 예와는 다르게, 각 시점의 은닉 상태를 출력하지 않고, 최종 은닉 상태만 출력하여 긍정인지 부정인지를 예측합니다.
※순환 신경망은 대체 뭐하는 모델인가요?
→앞에서는 다음 단어를 예측한다고 말씀드렸었고, 뒤에서는 최종 은닉 값만을 이용하여 분류한다고 말씀드려서 혼란스러우실수도 있습니다. 순환 신경망은 사용하고자하는 목적에따라 은닉상태를 출력해서 사용할수도 있고, 최종 은닉상태만 출력하여 사용할수도 있습니다. 순환 신경망의 사용은 <그림7>과 같이 다양합니다.
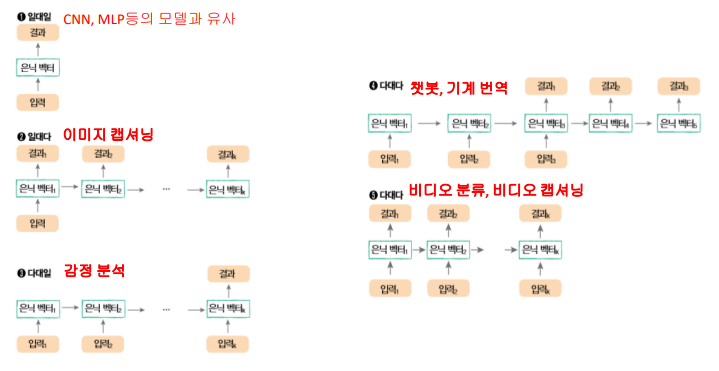
<그림7>
④ 합성곱 신경망 분류 모델
합성곱 신경망은 여러 계층의 합성곱 계층을 쌓은 모델입니다. 하나의 이미지를 입력받아 가장 좋은 특징을 만들어 내도록 학습하고, 추출된 특징을 활용하여 이미지를 분류하는 방식입니다. 보통 이미지 분류나 물체탐지에서 많이 사용되는데, 자연어 처리에서도 합성곱 신경망을 사용할 수 있습니다. 앞의 순환 신경망은 단어의 입력 순서를 중요하게 반영하였습니다. 반면 합성곱 신경망은 문장의 각 지역적인 정보를 보존하면서 각 문장 성분의 등장 정보를 학습에 반영하며 학습합니다. 따라서 학습할 때 각 필터 크기를 조절하면서 언어의 특징 값을 추출합니다. 기존의 n-gram방식과 유사하다고 보시면됩니다.
예를 들어 "이 영화에 나오는 배우들이 연기를 참 잘해"라는 문장에 2-gram을 사용할 경우 아래와 같은 결과값을 받을 수 있습니다.
이영/영화/화에/에나/나오/오는/는배/배우/우들/들이/이연/연기/기를/를참/참잘/잘해
