
일반적인 큐는 FIFO의 구조이다.
먼저 들어간 데이터가 먼저 반환되게 되어 있다.
우선순위 큐
이런 큐의 특성과 약간의 차이가 있는 우선순위 큐는
들어간 순서에 상관없이 일정한 규칙에 따라 우선순위를 정하고 우선순위가 높은 데이터 순서대로 반환되게 된다.
병원에서의 응급환자를 생각하자.
먼저 오게 되더라도 위급한 환자가 먼저 이지 않을까? 그런 개념이다.
- 큐가 선형적인 형태라면 우선순위 큐는 트리형태를 생각하라고 한다.
- 우선순위 큐는 최대 힙을 이용해서 구한다.
사용하기
일반적인 큐를 사용하듯 peek(), poll(), add(), offer()를 사용할 수 있따.
- 배열, 연결리스트, 힙 3가지로 구할 수 있다.
👋 배열이나 연결리스트로 구하는 경우를 보자.
배열이나 연결리스트로 구현할 경우 간단하게 구현이 가능하지만, 데이터 삽입과 삭제 과정에서 데이터를 한 칸씩 당기거나 밀어야 하는 연산을 계속 하여야 한다..
또 삽입의 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야 한다..
연결리스트의 경우, 삽입의 위치를 찾기 위해 첫번째 노드부터 시작해 마지막 노드에 저장된 데이터와 우선순위 비교를 진행해야 할 수도 있다. -> 성능 저하
그래서, 우선순위 큐를 구현할때는 일반적으로 힙으로 구현한다.😇
최대힙으로 구현한다.
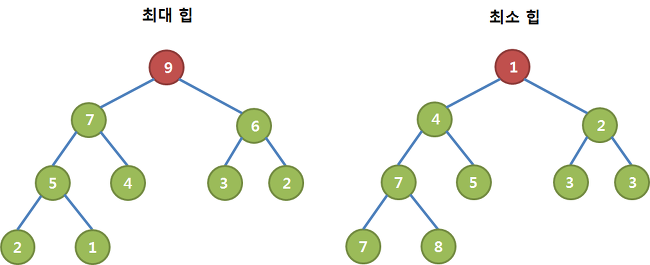
최대힙(Max Heap)?
- 부모노드가 자식노드보다 값이 큰 완전 이진트리.
- 모든 부모노드가 자식보다 큰 값을 가져야한다.
- 최대힙의 root node는 항상 최대값을 가진다.
- 전체 트리가 최대 힙 구조를 유지하도록 만들어야한다.
출처 : [자료구조]힙이란?
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.add(4); //offer(); 메소드를 사용해도 동일하게 추가된다.
priorityQueue.add(3);
priorityQueue.add(2);
priorityQueue.add(1);
Integer poll = priorityQueue
System.out.println(poll); //출력결과 1일반적인 큐와 다르게 가장 먼저 들어간 4가 아니라, 우선순위가 높은 1이 들어갔습니다.
기본적으로 숫자는 낮은 것이 우선순위를 높게 봅니다. (기본적으로 오름차순)
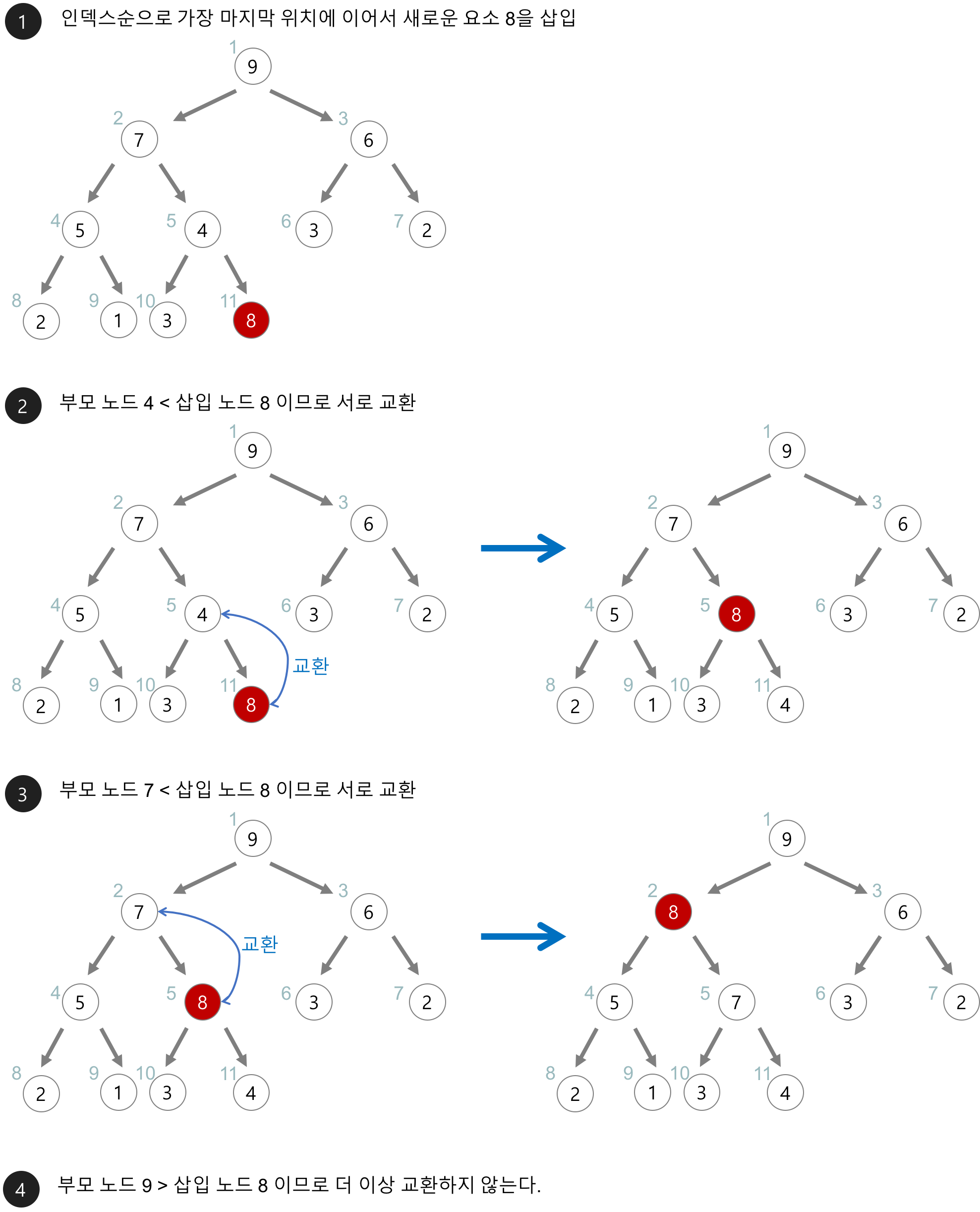
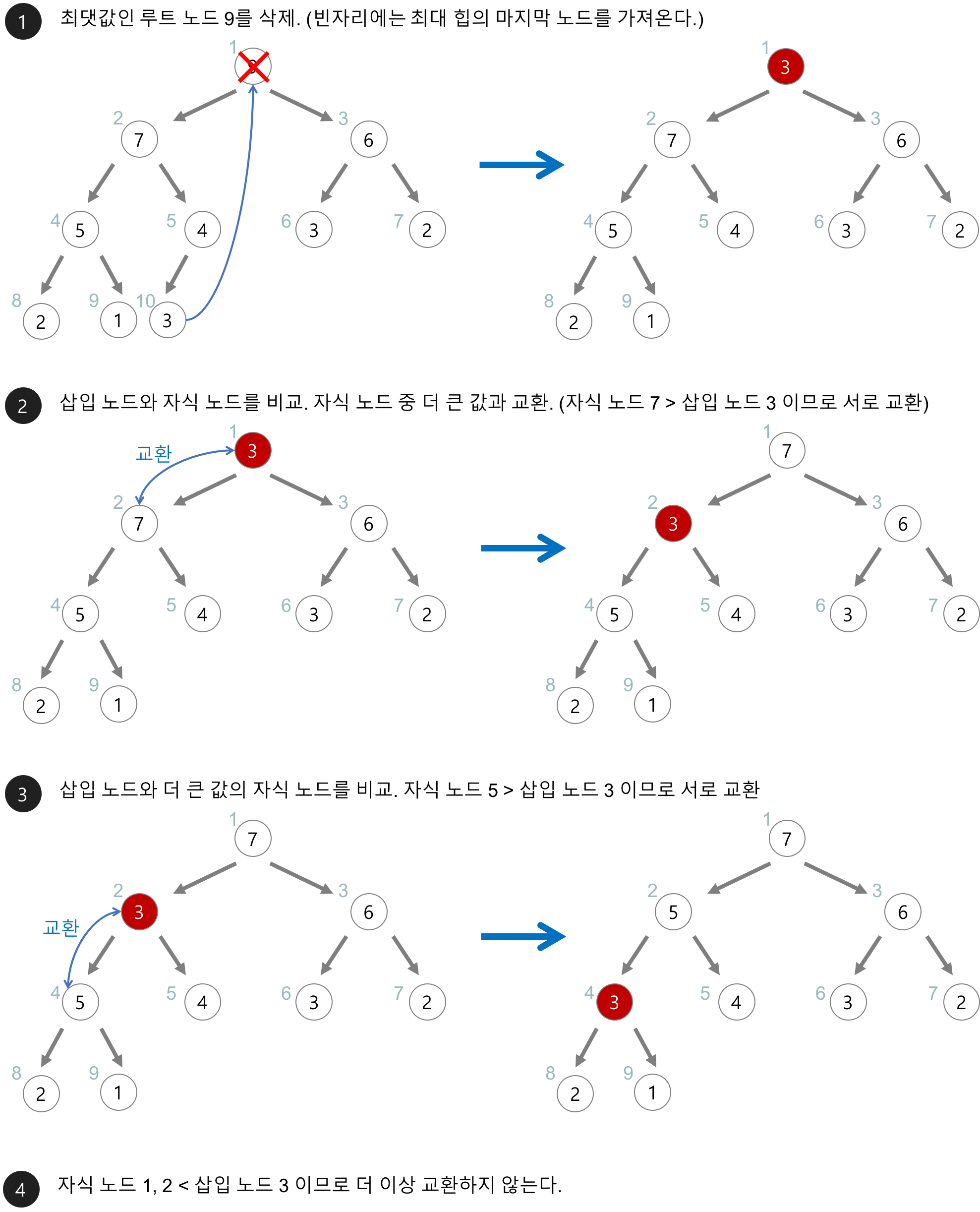
🥸 우선순위 힙에서 데이터를 삭제한다면?
어떠한 말보다 우수한 그림 설명이 있어서 가져왔따.. 감사합니다..
출처 : [자료구조]힙이란?
우선순위 변경하기
우선순위를 정하는 기준은 Java의 정렬기준과 동일하다.
Java는 기본적으로 낮은 숫자부터 큰 숫자까지 오름차순으로 정렬하게 되는데, 만약 다른 오름차순으로 사용하고 싶다면 Compartor 클래스나 Comparable 인터페이스를 이용해야 한다.
정렬기준으로 정하는 것과 동일하다.
Integer와 같은 숫자는 Collections.reversOrder()를 사용하면 간편하게 우선순위를 변경할 수 있다.
위에서 본 최대 힙이 아닌 최소 힙으로 구성하는 것이다.
//우선순위를 높은 숫자위주로 변경
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Collections.reverseOrder()); //내림차순 바꿔줌
priorityQueue.add(1); //offer(); 메소드를 사용해도 동일하게 추가된다.
priorityQueue.add(2);
priorityQueue.add(3);
priorityQueue.add(4);
Integer poll = priorityQueue.
System.out.println(poll); //출력결과 4왜 우선순위큐를 쓸까?
궁금해졌다. 큐가 있는데 굳이? 근데 굳이가 아니였따..
먼저 우선순위 큐를 쓰지 않고 일반 큐를 써도 결과에는 차이가 없다.
하지만 우선순위 큐를 쓰는 이유는 속도에 이점이 있기 때문이다.
다익스트라 알고리즘에서 속도에 영향을 주는 요소는 큐에서 노드를 꺼내오는 횟수와 우선순위 큐의 갱신 횟수이다.
자세한 예제와 설명은 [해당 블로그(http://jaegualgo.blogspot.com/2017/07/dijkstra-priority-queue.html)를 보자. 설명일 잘 나와있따.😄
