
우리가 스레드를 배우고 여러 질문에 대답을 할 때, 스레드 풀을 배우고 대답하게 된다.
스레드 풀이 왜 존재하는가?
이건 쉽다. OS가 요청을 받아서 메모리 공간을 할당해주고 그 메모리에 스레드를 할당해준다. 스레드는 동일한 메모리 영역에서 생성되고 관리되지만, 생성/수거에 드는 비용이 매우 크다! 그래서 요청 들어올때 마다 만들기엔 프로그램 퍼포먼스에 영향을 줄 수 있기에 미리 만들어놓고 가져다 쓰는 거다!
위의 질문데 대답을 했다면 다시 한번 대답을 곱씹어 보자.
스레드 생성/수거에 드는 비용이 매우 크다!
아 그래? 그럼 얼마나 큰데? Umm...?
이 질문을 시작으로 열심히 서칭을 해보았고 공부를 하면서 정리하게 된다.
누군가가 굳이 묻지 않더라도 내가 하는 대답의 정확한 근거가 있어야 하니까.
우린 오늘 크게 2가지를 깊게 알아볼 것이다.
- 자바에서 스레드 생성 비용이 얼마나 될까?
- 스레드 생성 비용이 비싸다면 언제부터 스레드 풀이 효율적일까?
이 글은 내가 이 곳을 참고하여 공부한 글이다.
- 스레드는 단순한 실행 흐름이 아니다. 메모리를 가지고 있다.
- 메모리 할당은 비싼 작업이다.
- 자바는 Executor 인터페이스를 통해 기본적으로 스레드 라이프 사이클을 관리 할 수 있다.
- 64bit JVM은 기본적으로 스레드 스택 메모리를 1MB 예약 할당한다.
- 현대 메모리 할당은 물리 메모리의 가상 매핑이기에, 최대 사용 시 1MB까지 (스택 깊이에 따라 달라지지만) 기본적으로 16KM의 '물리적 메모리'를 사용한다.
- 이러한 스레드는 무분별한 생성을 막기위해 스레드 풀을 사용함
- 스레드 풀은 교착 상태와 무한 대기가 발생할 수 있음
- 스레드 풀이 어느정도부터 효율적일까는 어떤 스레드 풀을 어떻게 사용하느냐에 따라 달라짐.
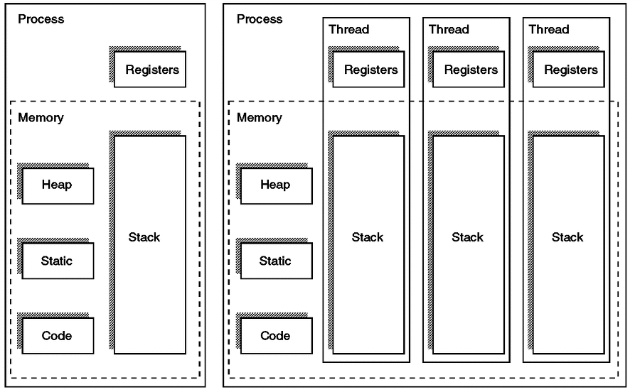
스레드

-
스레드가 단순히 하나의 실행 흐름이라기엔 스레드는 실행흐름을 포함하는거지 스레드 자체도 레지스터와 스택을 가진다.
(+ 스택에는 파라미터값, 리턴값, 메서드 내부 변수 등의 값들이 들어가기에 개별적인 흐름을 만들어준다 그래서 개별 실행 흐름을 가진다.) -
스레드도 Context Swtiching을 한다. 그러니 스레드의 생성도 메모리의 할당이라는 비용 때문에 수많은 스레드가 생성되길 원하지 않는다.
자바의 스레드 생성 비용
-
스레드는 프로세스가 할당받은 메모리를 사용한다.
즉, JVM이 할당받은 메모리 내에서 메모리를 재할당하기에 스레드의 생성 비용은 고스란히 JVM 메모리의 소비가 된다. -
64bit Java8과 Java11에선 스레드에겐 기본적으로 1MB의 메모리를 예약 할당해준다.
스택의 깊이가 최대로 늘어났을 때 1MB까지 할당되는 것이지만, 그래도 최소한 16KB 이상의 메모리를 소비한다!
이런 스레드 비용에서 작업 요청이 엄청 많이(1천개 이상) 들어오면?
(스레드 하나에 16KB라고 쳐도...엄청 날 수 있다)
스레드 풀
- 말 그대로 스레드의 모음
- 제한된 리소스를 이용하여 최대한의 효율을 내기 위한 최적화 기법?
- Bottle Neck 현상이 발생하는 I/O 작업과 DB 작업이 주로 해당된다.
ex)
1. 1000개의 요청이 들어왔다
2. 1000개의 스레드가 생성되었다.
3. 1000개의 스레드가 작업을 하려한다.
4. 누가 먼저 접근하지?
결국 1000개의 스레드가 아무리 빠르게 생성되더라도 시스템 스케쥴러에 의해 스레드의 우선순위를 매번 할당해야 한다.
이럴떄 스레드 풀을 사용하면?
1. 1000개의 요청이 들어왔다.
2. 우선순위가 높은 작업에 일정 스레드가 이미 생성되어 스레드 풀에 의해 라이프 사이클이 관리된다.
3. 스레드 풀에 의해 작업이 큐를 이용하여 우선순위가 배분되고 처리된다.
문제점

이렇게 효율적인 스레드 풀을 사용했지만 스레드 1,2,3에 나눠 배분된 작업 1,2,3 중 작업 1이 가장 먼저 끝나면 어떻게 될까?
1은 그냥 논다. 목적이 스레드에게 작업을 배분하는 거였기에!
🆖 리소스를 효율적으로 사용하려고 최적화했는데 리소스가 놀다니?
스레드 풀의 개선 (Fork Join Thread Pool)
기존 스레드 풀을 개선하기 위한 방법으로 Java7 이상의 스레드 풀에서 사용된다.
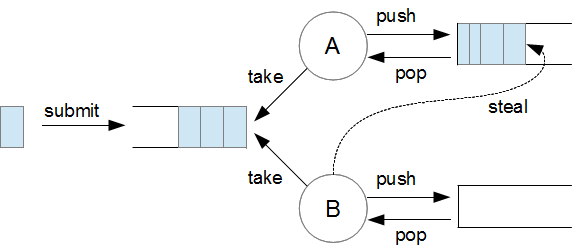
1. 작업을 하나의 큰 작업들로써 제공해준다.
2. 첫 스레드가 작업을 가져와 자신의 로컬 큐에 할당, 분할 한다.
3. 두 번째 스레드가 가져올 작업이 없다면, 첫 스레드의 큐에 있는 분할된 작업을 훔쳐간다.
4. 나머지 스레드도 마찬가지.
이러면 100개의 작업을 3개의 스레드가 50 25 25 정도로 분배하여 작업한다.
결론
위에서 2가지를 중점적으로 알아보자고 했다.
다시 질문을 보자.
✋ 자바에서 스레드 생성 비용이 얼마나 될까?
하나의 스레드가 생성되는 데에는 최소 16kb에서 최대 1mb까지 메모리를 차지 한다고 하였다. 그리고 그 메모리는 결국 프로세스가 CPU로부터 할당 받은 메모리를 나눠쓴다. 많이 생성해서 좋을 거 없다는 건 최소 16kb가 증명해준다.
✋ 스레드 생성 비용이 비싸다면 언제부터 스레드 풀이 효율적일까?
효율적인 스레드 풀이 없다. 늘 그 상황에 최선만 있다. 위에서 알아보았듯 스레드 풀을 만들어도 놀게 되는 스레드도 있었다. 그런 상황을 개선하기 위해 Fork Join Pool 방식이 채택되었다. 늘 그 상황을 개선 시키는 최선의 방법들만이 존재한다.
Reference
