프로젝트가 끝이나고 노트북 반납을 위해 정리를 다 했다고 생각했는데 마지막 프로젝트 파일만 안넣고 초기화 시켜서 고생아닌 고생을 하게되었다...(안심한 순간이 제.일.위.험)
어차피 버그나 수정할 부분도 있어서 심신안정 후 글을 써본다.
- 네이버맵 v5
- macOS
네이버맵을 선택한 이유
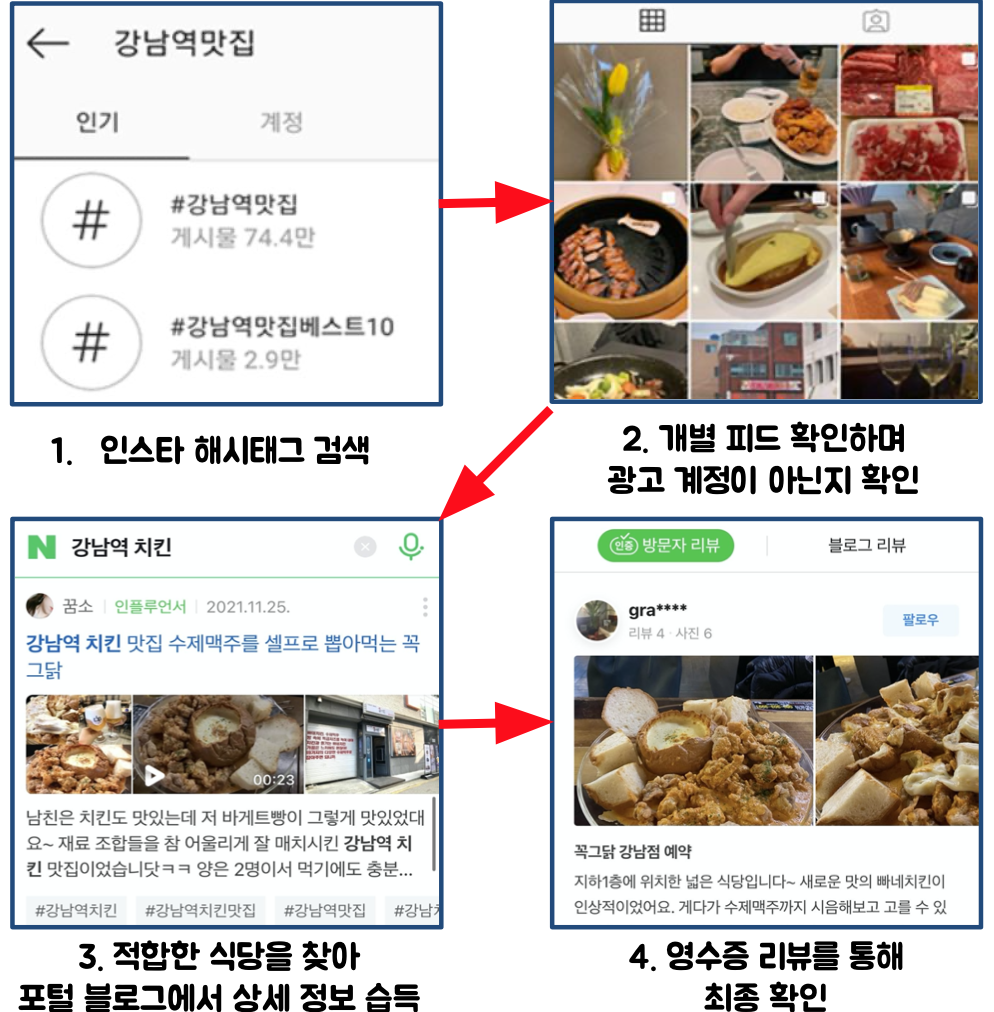
대부분 젊은세대(MZ세대)들이 맛집(음식점)을 찾을 때 인스타그램,포털 사이트 검색,블로그 리뷰를 기본적으로 탐색하고 식당들을 찾아간다.
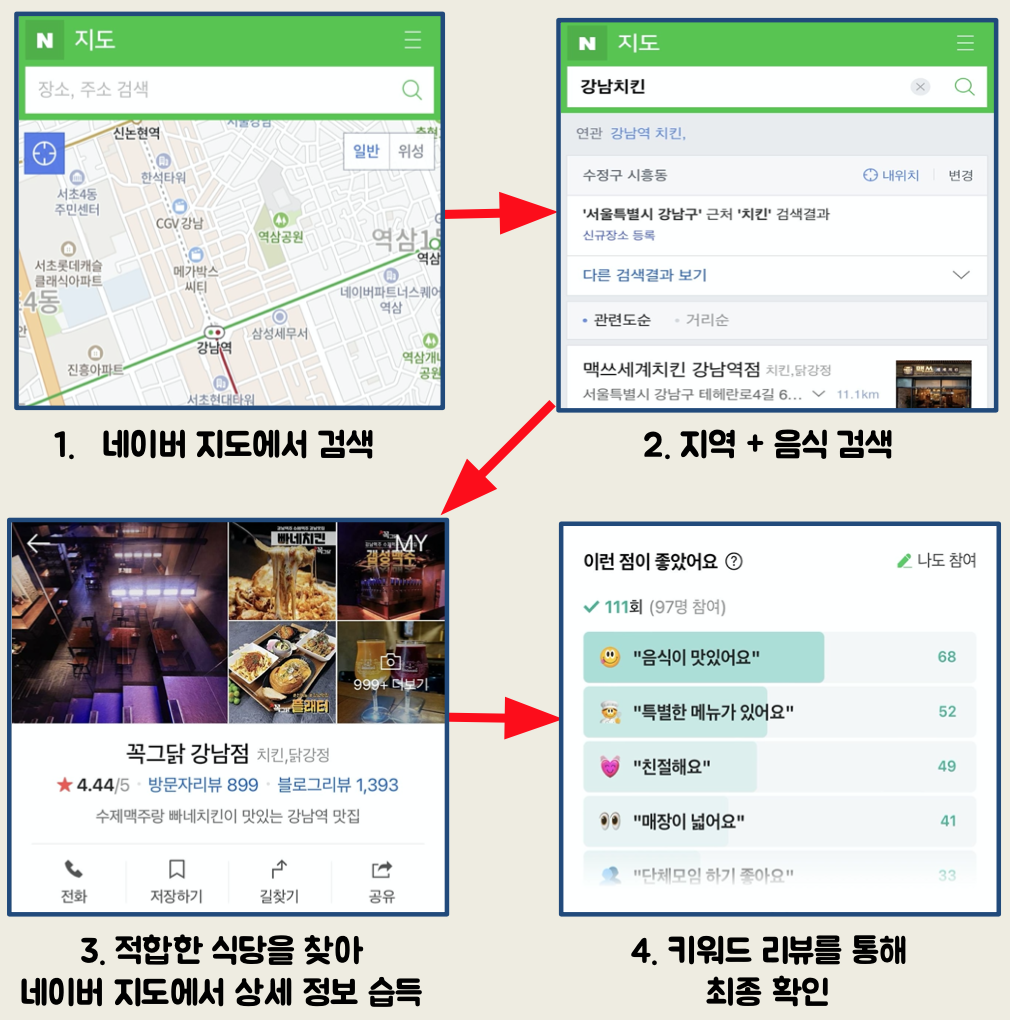
네이버맵을 선택한 이유 : 정보와 사용자들이 많음
식당검색 -> 식당명 클릭 -> 키워드 리뷰(네이버MY플레이스)를 기준점으로 추천하는 사이트를 결정
(영수증 리뷰는 조작하기 어렵다고 판단 (단, 부정적인 리뷰는 선택사항에 없고 한정적인 키워드)
코드
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
from bs4 import BeautifulSoup
import re
import json
# --크롬창을 숨기고 실행-- driver에 options를 추가해주면된다
# options = webdriver.ChromeOptions()
# options.add_argument('headless')
url = 'https://map.naver.com/v5/search'
driver = webdriver.Chrome('./chromedriver') # 드라이버 경로
# driver = webdriver.Chrome('./chromedriver',chrome_options=options) # 크롬창 숨기기
driver.get(url)
key_word = '강남구 치킨' # 검색어
# css 찾을때 까지 10초대기
def time_wait(num, code):
try:
wait = WebDriverWait(driver, num).until(
EC.presence_of_element_located((By.CSS_SELECTOR, code)))
except:
print(code, '태그를 찾지 못하였습니다.')
driver.quit()
return wait
# css를 찾을때 까지 10초 대기
time_wait(10, 'div.input_box > input.input_search')
# 검색창 찾기
search = driver.find_element_by_css_selector('div.input_box > input.input_search')
search.send_keys(key_word) # 검색어 입력
search.send_keys(Keys.ENTER) # 엔터버튼 누르기
res = driver.page_source # 페이지 소스 가져오기
soup = BeautifulSoup(res, 'html.parser') # html 파싱하여 가져온다
sleep(1)
# frame 변경 메소드
def switch_frame(frame):
driver.switch_to.default_content() # frame 초기화
driver.switch_to.frame(frame) # frame 변경
res
soup
# 페이지 다운
def page_down(num):
body = driver.find_element_by_css_selector('body')
body.click()
for i in range(num):
body.send_keys(Keys.PAGE_DOWN)
# frame 변경
switch_frame('searchIframe')
page_down(40)
sleep(5)
# 매장 리스트
store_list = driver.find_elements_by_css_selector('._1EKsQ')
# 페이지 리스트
next_btn = driver.find_elements_by_css_selector('._2ky45 > a')
# dictionary 생성
store_dict = {'매장정보': []}
# 시작시간
start = time.time()
print('[크롤링 시작...]')
# 크롤링 (페이지 리스트 만큼)
for btn in range(len(next_btn))[1:]: # next_btn[0] = 이전 페이지 버튼 무시 -> [1]부터 시작
store_list
for data in range(len(store_list)): # 매장 리스트 만큼
page = driver.find_elements_by_css_selector('.OXiLu')
page[data].click()
sleep(2)
try:
# 상세 페이지로 이동
switch_frame('entryIframe')
time_wait(5, '._3XamX')
# 스크롤을 맨밑으로 1초간격으로 내린다.
for down in range(3):
sleep(1)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# -----매장명 가져오기-----
store_name = driver.find_element_by_css_selector('._3XamX').text
# -----평점-----
try:
store_rating_list = driver.find_element_by_css_selector('._1A8_M').text
store_rating = re.sub('별점', '', store_rating_list).replace('\n', '') # 별점이라는 단어 제거
except:
pass
print(store_rating)
# -----주소(위치)-----
try:
store_addr_list = driver.find_elements_by_css_selector('._1aj6-')
for i in store_addr_list:
store_addr = i.find_element_by_css_selector('._1h3B_').text
except:
pass
print(store_addr)
# -----전화번호 가져오기-----
try:
store_tel = driver.find_element_by_css_selector('._3ZA0S').text
except:
pass
print(store_tel)
# -----영업시간-----
try:
store_time_list = driver.find_elements_by_css_selector('._2vK84') # 아니 태그가 그세 바뀌네ㅡ,.ㅡ
for i in store_time_list:
store_time = i.find_element_by_css_selector('._3uEtO > time').text
except:
pass
print(store_time)
# -----메뉴-----
try:
menu_list = driver.find_elements_by_css_selector('._1XxR5')
menu_name = [] # 메뉴이름
menu_price = [] # 메뉴가격
for i in menu_list:
name = i.find_element_by_css_selector('._1q3GD').text
menu_name.append(name)
price = i.find_element_by_css_selector('._3IAAc').text # 텍스트를 넣을 변수 생성
price = re.sub('원\d{2},\d{3}', '', price) # 할인 전 가격 제거 # 재정의
menu_price.append(price) # 추가
except:
pass
# -----메뉴2 (다른 태그의 메뉴)-----
try:
menu_list_two = driver.find_elements_by_css_selector('._20R25')
menu_name_two = []
menu_price_two = []
for i in menu_list_two:
name_two = i.find_element_by_css_selector('._2E0Gk').text
name_two = re.sub('\n사진|\n대표', '', name_two)
price_two = i.find_element_by_css_selector('._3GJcI').text
menu_name_two.append(name_two)
menu_price_two.append(price_two)
except:
pass
# 메뉴 리스트 합체
menus = menu_name + menu_name_two
prices = menu_price + menu_price_two
print(menus)
print(prices)
# -----키워드 리뷰 가져오기-----
try:
keyword_list = driver.find_element_by_css_selector('._28hFN') # 키워드가 담긴 리스트 클릭
keyword_list.click()
except: # 키워드리뷰 없으면 다음 음식점으로
print('키워드리뷰 없음 >>> 다음으로',)
switch_frame('searchIframe')
continue
try:
keyword_review_list = driver.find_elements_by_css_selector('._3FaRE') # 리뷰 리스트
kwd_title = []
kwd_count = []
sleep(2)
for i in keyword_review_list:
keyword_title = i.find_element_by_css_selector('._1lntw').text # 키워드리뷰
keyword_count = i.find_element_by_css_selector('.Nqp-s').text # 리뷰를 선택한 수
# db에 넣을 때 편의를 위해 요청하였음
title_re = re.sub('"', '', keyword_title) \
.replace('양이 많아요', '1').replace('음식이 맛있어요', '2').replace('재료가 신선해요', '3') \
.replace('가성비가 좋아요', '4').replace('특별한 메뉴가 있어요', '5').replace('화장실이 깨끗해요', '6') \
.replace('주차하기 편해요', '7').replace('친절해요', '8').replace('특별한 날 가기 좋아요', '9').replace(
'매장이 청결해요',
'10') \
.replace('인테리어가 멋져요', '11').replace('단체모임 하기 좋아요', '12').replace('뷰가 좋아요', '13').replace(
'매장이 넓어요',
'14') \
.replace('혼밥하기 좋아요', '15')
title_num = list(map(str, range(1, 16))) # 1~15만 리스트에추가 (이외에 다른 키워드들은 추가하지않음)
count_keyword = re.sub('이 키워드를 선택한 인원\n', '', keyword_count)
if title_re in title_num:
kwd_title.append(title_re)
kwd_count.append(count_keyword)
else:
pass
except:
pass
kwd_count = list(map(int, kwd_count)) # int 형변환
print(kwd_title)
print(kwd_count)
# -----썸네일 사진 주소-----
try:
thumb_list = driver.find_element_by_css_selector('.cb7hz') \
.value_of_css_property('background-image') # css 속성명을 찾는다
store_thumb = re.sub('url|"|\)|\(', '', thumb_list) # url , (" ") 제거
except:
pass
print(store_thumb)
# ---- dict에 데이터 집어넣기----
dict_temp = {
'name': store_name,
'tel': store_tel,
'star': store_rating,
'addr': store_addr,
'time': store_time,
'menu': menus,
'price': prices,
'kwd': kwd_title,
'kwd_count': kwd_count,
'thumb': store_thumb
}
store_dict['매장정보'].append(dict_temp)
print(f'{store_name} ...완료')
switch_frame('searchIframe')
sleep(1)
except:
print('ERROR!' * 3)
# 다음 페이지 버튼
if page[-1]: # 마지막 매장일 경우 다음버튼 클릭
next_btn[-1].click()
sleep(2)
else:
print('페이지 인식 못함')
break
print('[데이터 수집 완료]\n소요 시간 :', time.time() - start)
driver.quit() # 작업이 끝나면 창을닫는다.
# json 파일로 저장
with open('data/store_data.json', 'w', encoding='utf-8') as f:
json.dump(store_dict, f, indent=4, ensure_ascii=False)
대부분의 에러들은 시간초과(태그를 찾지못하는 경우)가 많았다.
넘어가는 구간마다 sleep으로 에러잡기 (슈퍼컴은 필요없을듯...ㅠ)
🔥주의사항
클래스명이 자주 변경 되므로 주의하시고 직접 개발자도구(inspect) 사용하셔서 확인하시는게 좋습니다.
멋진 개발자분들은 참고용 코드로만 보시고 더 좋은 코드로 만들어서 사용해 주세요😊

13개의 댓글

안녕하세요 좋은 코드 감사합니다. 혹시 실행시 터미널에
File "c:\Users\LEE_JIEUN32\Desktop\기본 네이보 지도 웹 크롤링 코드.py", line 253, in
if page[0]: # 마지막 매장일 경우 다음버튼 클릭
NameError: name 'page' is not defined. Did you mean: 'range'?
라고 뜨는 건 어떻게 해결하면 좋을까요?

안녕하세요, 한줄기의빛을 만들어 주셔서 정말 감사합니다.
코드 실행 도중에 에러가 떠서 여쭈어봅니다. 혹시 page의 css_selector 찾는 법을 물어도 될까요.
page를 인식을 못해서 에러가 자꾸 뜨네요... ㅠㅠ


안녕하세요 정말 많은 도움이 되었습니다. 근데 처음 for에서 page를 왜 쓰는건지 정확히 저 변수가 어떤 역할을 하는지 궁금해서 여쭤보고 싶어서 댓글 답니다. 감사합니다.
안녕하세요. 좋은 참고자료 감사합니다. 제가 막 웹 크롤링을 입문했습니다만, 크롤링할 때 의 find_element_by_css 안의 '.cb7hz' 라거나 '._28hFN' 등은 직접 페이지 소스를 뜯어보면서 발견하신 것인지요 ?