부스트코스 강의 딥러닝 기초 다지기 중 '최적화의 주요 용어 이해하기, Gradient Descent Methods, Regularization'를 정리한 내용이다.
최적화의 주요 용어 이해하기
-
Generalization
- Training error가 0에 가까워도 test error가 커 generalization gap이 크면 일반화 성능이 좋다할 수 없다.
-
Underfitting vs Overfitting
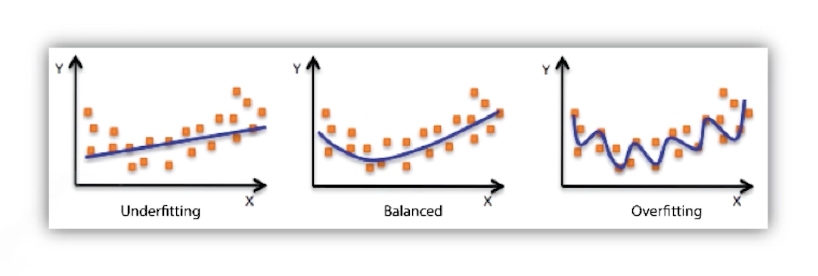
-
Cross-validation
- Cross-validation을 해서 최적의 하이퍼파라미터값을 찾고, 이 하이퍼파라미터값을 고정시킨 후 학습시킬 때는 모든 데이터를 사용한다. Test data는 어떤 경우에도 사용하지 않는다.
-
Bias and Variance
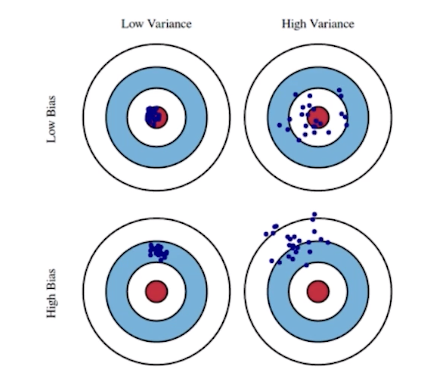
- Bias and Variance Tradeoff
- 학습데이터에 노이즈가 있을 때 minimize하는 것은 3가지 파트: bias^2, variacne, noise 로 구성되는데, 서로 tradeoff관계에 있어 하나가 감소하면 다른 것이 증가한다는 것

- 학습데이터에 노이즈가 있을 때 minimize하는 것은 3가지 파트: bias^2, variacne, noise 로 구성되는데, 서로 tradeoff관계에 있어 하나가 감소하면 다른 것이 증가한다는 것
- Bias and Variance Tradeoff
-
Booststrapping
- 학습데이터 중 일부를 활용한 모델을 여러 개 만들어 예측하는 값들로 결과를 내는 것
-
Bagging vs Boosting
-
Bagging(Bootstrapping aggregating)
- 학습데이터를 여러 개 만들어 여러 개 모델을 만들고 그 output으로 평균을 내는 것
-
Boosting
- 학습데이터가 여러 개 있을 때 이를 sequential하게 봐서, 간단한 모델을 만들고 다음 모델은 기존 모델에서 잘 되지 않은 데이터만 신경써서 만드는 것
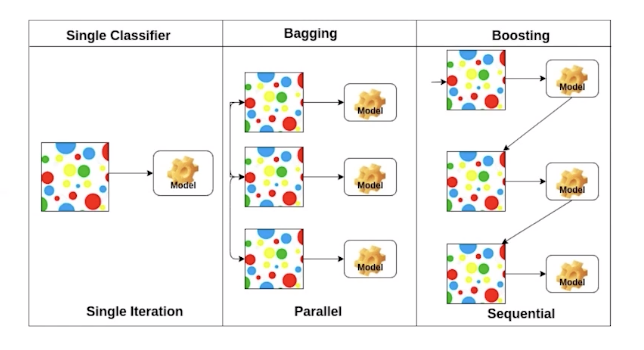
-
Gradient Descent Methods
-
Stotachastic gradient descent(SGD)
- 하나의 샘플을 통해 gradient를 구하는 것
-
Mini-batch gradient descent
- batch size개의 샘플을 통해 gradient를 구하는 것
-
Batch gradient descent
- 한번에 다 써서 gradient를 구하는 것
-
Batch Size의 중요성
- 배치 사이즈를 작게 쓰면 일반적으로 성능이 좋다. Flat Minimum에 가까운 것으로, training function에서 약간만 멀어져도 Testing function이 크게 달라지지 않는다.
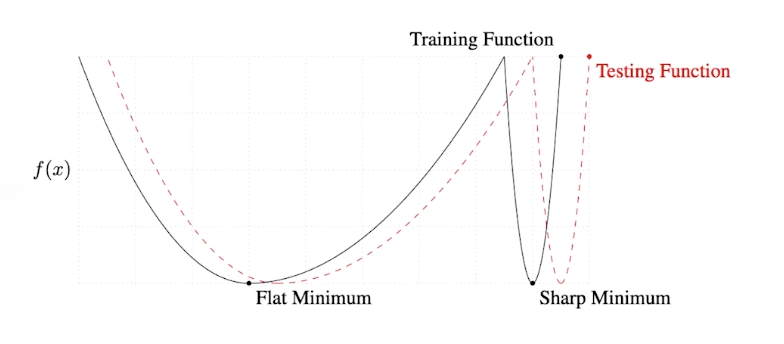
- 배치 사이즈를 작게 쓰면 일반적으로 성능이 좋다. Flat Minimum에 가까운 것으로, training function에서 약간만 멀어져도 Testing function이 크게 달라지지 않는다.
- (Stochastic) Gradient descent
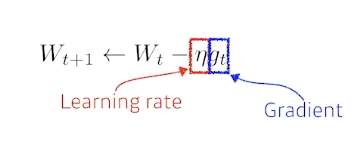
- learning rate을 적절히 잡아주는게 중요하다.
- Momentum
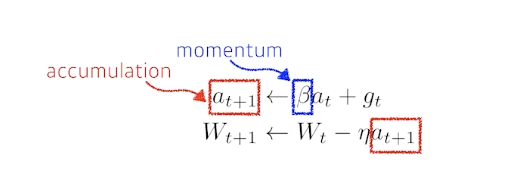
- 한번 흘러간 gradient를 어느정도 유지시켜주기해 잘 학습한 효과가 있다.
-
Nesterov Accelearted Gradient
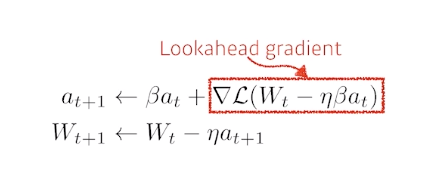
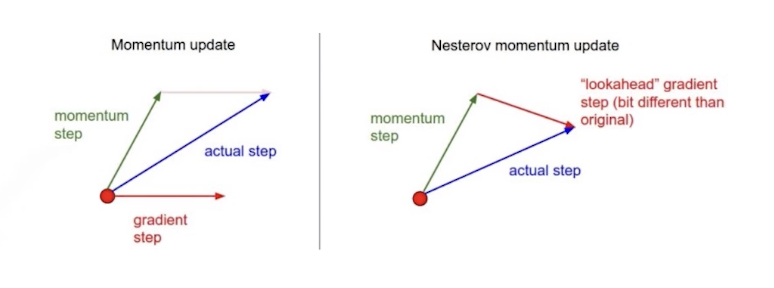
- local minimum을 계산할 때 좀 더 빠르게 할 수 있다.
- Adagrad
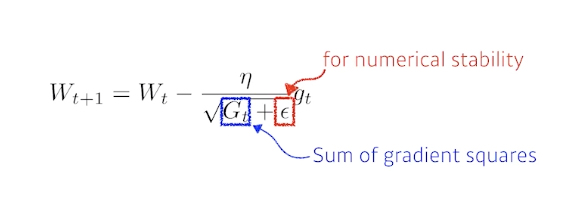
- 파라미터가 얼마나 변화해왔는지를 보고, 많이 변한 파라미터에 대해서는 적게 변화시키고 적게 변한 파라미터는 많이 변화시킨다.
- 지금까지 얼마나 많이 변했는지가 G
- Adadelta

- learning rate이 없는 것이 특징이다.
- RMSprop
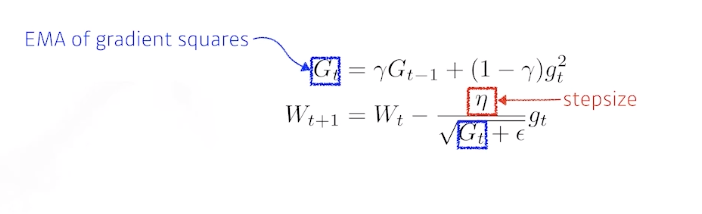
- stepsize를 추가해준 것으로, 효과가 좋다.
- Adam
- gradient square에 따라서 adaptive하게 learning rate를 바꾸는 것과 momentum을 같이 활용하는 것
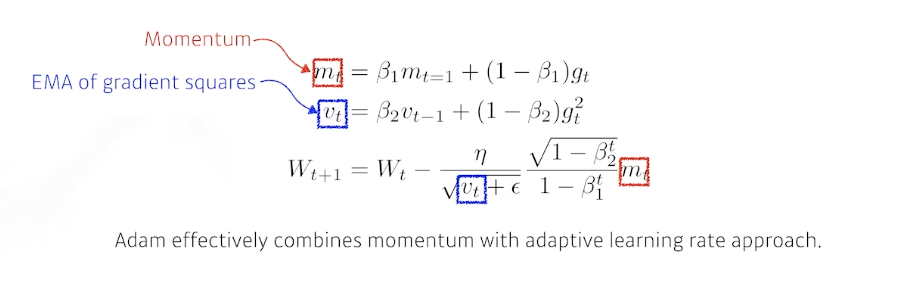
Regularization
-
Regularization: Generalization을 위해 학습에 반대되도록 규제를 거는 것, Test data에도 잘 적용되도록 도와준다.
-
Early stopping
- iteration이 돌아감에 따라 학습이 진행될수록 validation error가 높아지는데 학습을 중간에 멈춰주는 것으로, Loss가 커지기 시작할 때 멈춰준다.
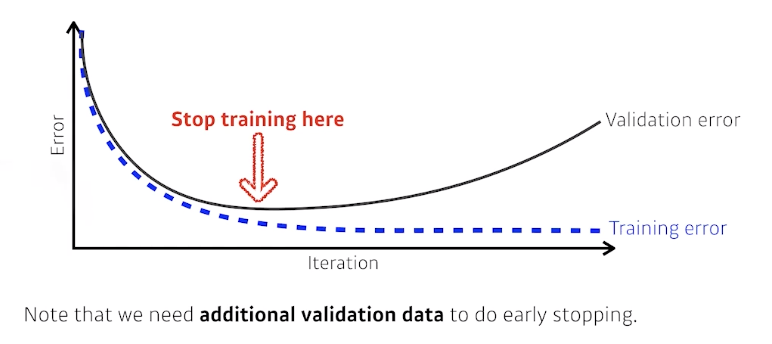
- iteration이 돌아감에 따라 학습이 진행될수록 validation error가 높아지는데 학습을 중간에 멈춰주는 것으로, Loss가 커지기 시작할 때 멈춰준다.
-
Parameter Norm Penalty
- NN 파라미터가 너무 커지지 않게 해주는 것으로, 파라미터들을 다 제곱한 후 다 더한 값을 같이 줄이는 것이다.

- NN 파라미터가 너무 커지지 않게 해주는 것으로, 파라미터들을 다 제곱한 후 다 더한 값을 같이 줄이는 것이다.
-
Data Augmentation
- Data가 많을수록 성능이 좋아지므로 주어진 데이터를 다양한 방법으로 늘리는 것이다.
- Data가 많을수록 성능이 좋아지므로 주어진 데이터를 다양한 방법으로 늘리는 것이다.
-
Noise Robustness
- 입력데이터와 weight에 노이즈를 넣어주면 결과가 잘 나온다.

- 입력데이터와 weight에 노이즈를 넣어주면 결과가 잘 나온다.
-
Label Smooting
- 분류문제에서 데이터 두 개를 뽑아 섞어주면 성능이 올라가기도 한다.

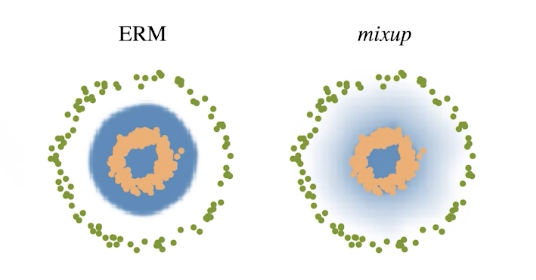
- 분류문제에서 데이터 두 개를 뽑아 섞어주면 성능이 올라가기도 한다.
-
Dropout
- Neural Network의 weight를 일부 0으로 바꿔주는 것
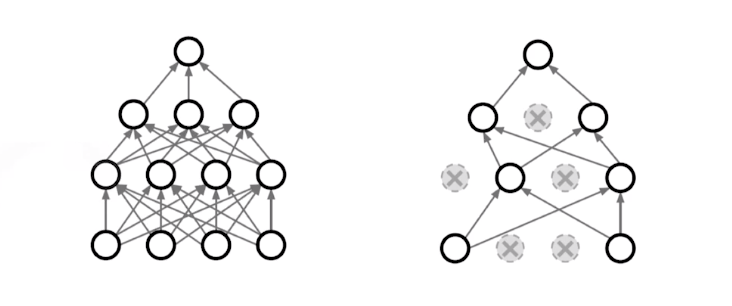
- Neural Network의 weight를 일부 0으로 바꿔주는 것
-
Batch Normalization
-
분류문제에서 일반적으로 layer가 깊게 쌓아져있을 때 성능이 올라간다.
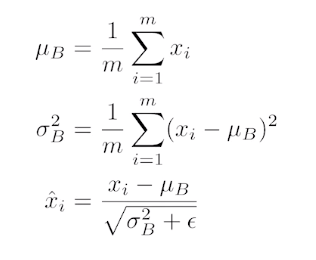
-
Batch Normalization보다는 다양한 normalization이 있다.
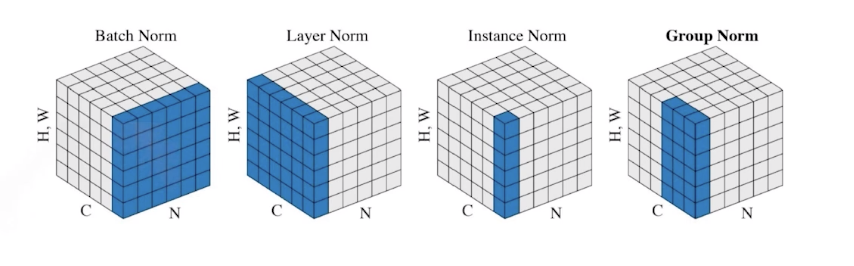
-
