주요 개념
-
Sequential Data(순차 데이터): 텍스트나 시계열 데이터와 같이 순서에 의미가 있는 데이터
- ex) 글, 대화, 일자별 판매 실적
-
RNN(순환 신경망): 순차 데이터에 잘 맞는 인공 신경망의 한 종류, 순차 데이터를 처리하기위해 고안된 순환층을 1개 이상 사용한 신경망
-
순환 신경망에서는 셀의 출력을 hidden state라고 부름, hidden state는 다음 층으로 전달될 뿐만 아니라 셀이 다음 타임스텝의 데이터를 처리할 때 재사용됨
-
Corpus(말뭉치): 자연어 처리에서 사용하는 덱스트 데이터의 모음, 즉 훈련 데이터셋
-
토큰: 텍스트에서 공백으로 구분되는 문자열
-
원핫인코딩: 어떤 클래스에 해당하는 원소만 1이고 나머지는 모두 0인 벡터, 정수로 변환된 토큰을 원핫인코딩으로 변환하려면 어휘 사전 크기의 벡터가 만들어짐
-
Word Embedding: 정수로 변환된 토큰을 비교적 작은 크기의 실수 밀집 벡터로 변환함, 밀집 벡터는 단어 사이의 관계를 표현할 수 있기에 자연어 처리에서 좋은 성능을 보임
RNN으로 IMDB 리뷰 분류하기
- 데이터 가져오기
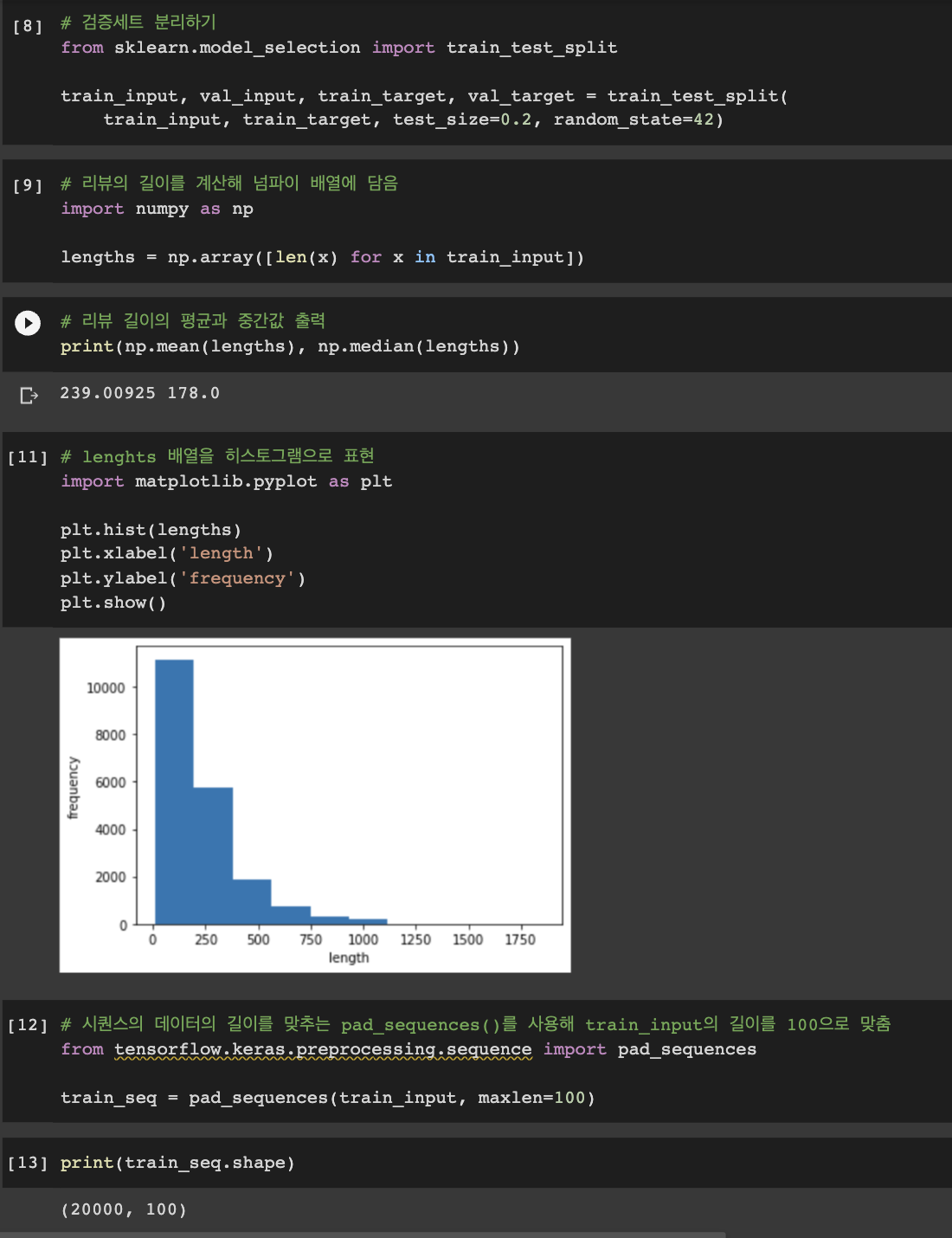
- 검증세트 분리하고 리뷰의 길이 계산해 나타내기
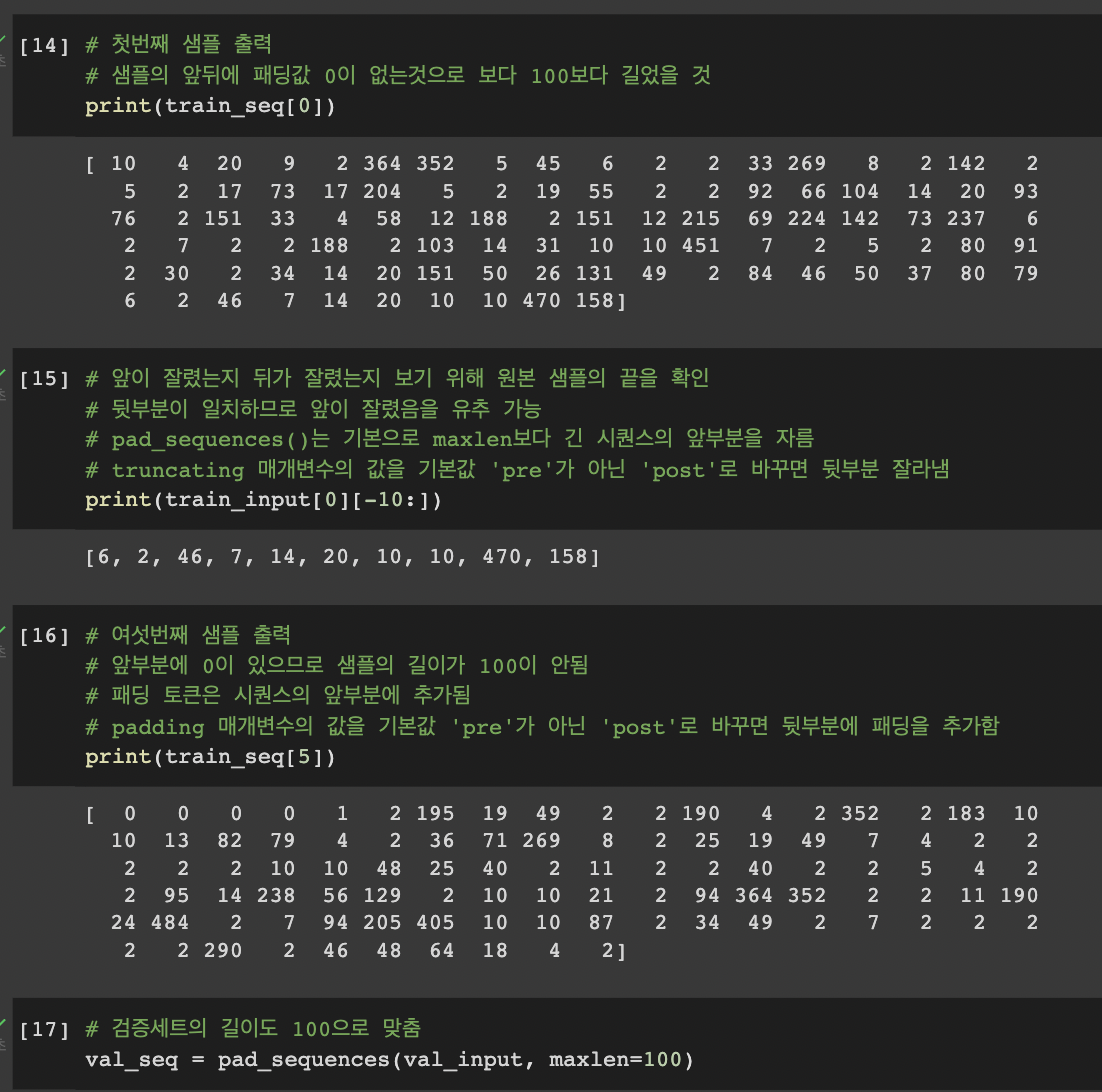
- 샘플 출력, 패딩 추가
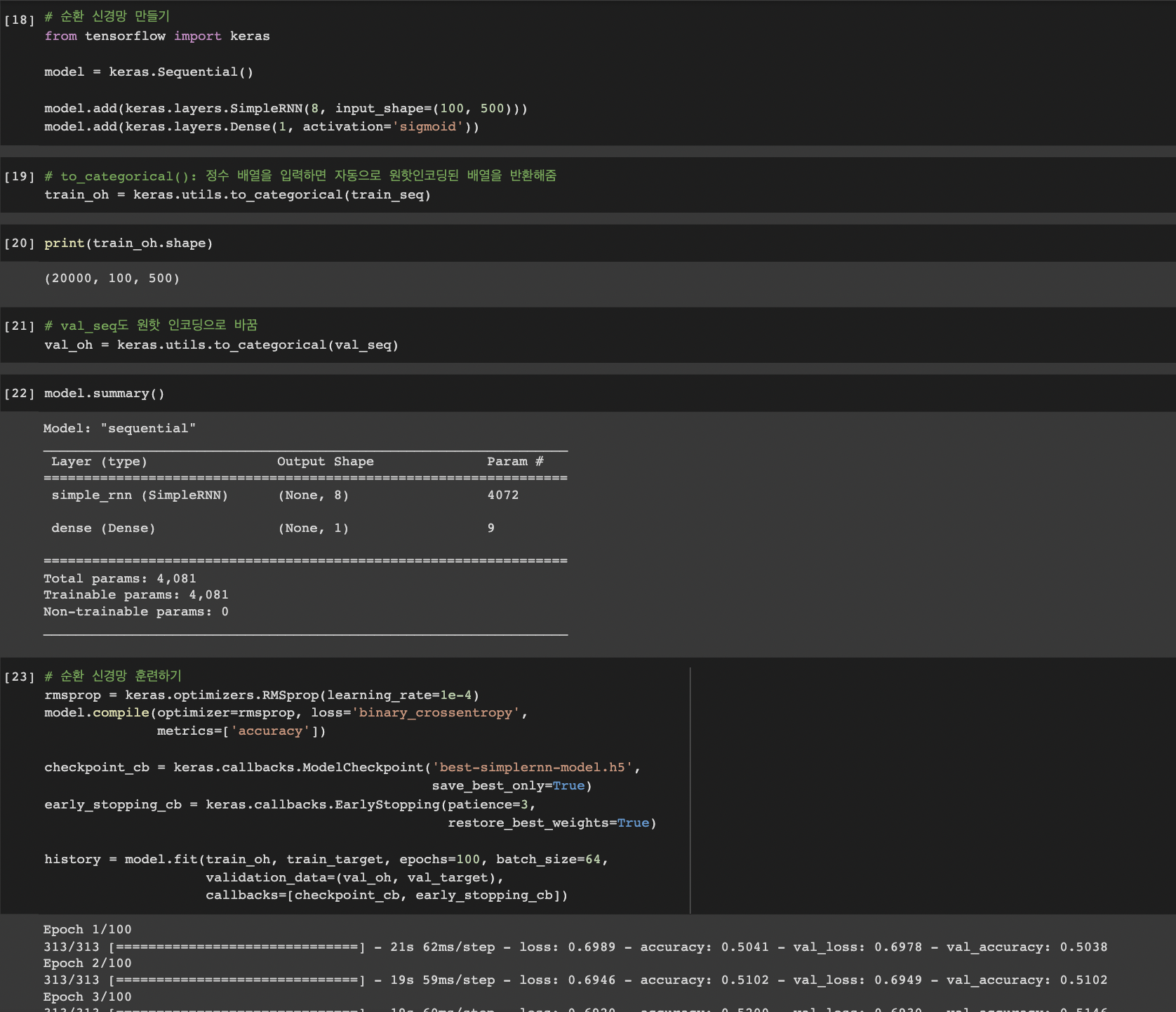
- 순환 신경만 만들고 훈련하기
colab 링크:
(9-1) https://colab.research.google.com/drive/1J6l7Q7Q6I5qarMN_CnDobQubpEE1hAC_?usp=sharing,
(9-2)
https://colab.research.google.com/drive/1j-o6ka_C7rUKEaIATRpPlKdYvL5nfiyH?usp=sharing
참고: 혼자 공부하는 머신러닝+딥러닝
