들어가기 전에
-
이 포스팅은 https://medium.com/@victorsmelopoa/an-introduction-to-elasticsearch-with-kibana-78071db3704 에 있는 포스팅을 번역한 것입니다. 오역이나 의역이 있을 수 있습니다. 지적해주시면 확인 후 바로 정정하겠습니다.
-
original source of this posting is from https://medium.com/@victorsmelopoa/an-introduction-to-elasticsearch-with-kibana-78071db3704 If the original author requests deletion, it will be deleted immediately.
-
Translated by Jake Seo (서진규)
- https://velog.io/@jakeseo_me - https://github.com/n00nietzsche

이 문서는 정확히 엘라스틱서치가 무엇인지보다는 엘라스틱서치를 실제로 어떻게 사용하느냐에 초점이 맞추어져 있습니다. 엘라스틱서치와 엘라스틱서치의 시각화 플러그인인 키바나에 집중합니다.
엘라스틱서치(Elasticsearch)란 무엇인가?
엘라스틱서치는 확장성이 매우 좋은 오픈소스 검색엔진입니다. 여러분이 많은 양의 데이터를 보관하고 실시간으로 분석할 수 있게 해줍니다.
엘라스틱서치는 JSON 문서 파일과 함께 동작합니다. JSON 문서 파일의 내부적 구조를 이용하여, 데이터를 파싱합니다. 파싱을 통해 여러분이 필요한 정보에 대한 거의 실시간 검색(Near real time)을 지원합니다.
빅데이터를 다룰 때 매우 유용합니다.
몇가지 정의와 알아야 할 것들
이번 아티클의 컨셉(실용적이고 간단한 것만 알자!)과 다르게 엘라스틱서치에 관련된 지루한 기술적인 내용이지만 반드시 알아야 할 유용한 정보들이 있습니다.
- 엘라스틱서치는 실시간, 분산형, 분석 엔진이다.
- 오픈 소스이며, 자바로 개발되었다.
- 테이블과 스키마 대신에 문서 구조로 된 데이터를 사용합니다.
엘라스틱서치와 관련된 장점 중 눈에 띄는 것은 속도와 확장성입니다. 엘라스틱서치는 쿼리가 매우 빠르게 수행될 수 있도록 구현되었습니다. 그리고 확장성에 대해서는, 엘라스틱서치는 그냥 여러분의 노트북에서 돌 수 도 있고, 페타바이트의 데이터를 가진 몇백개의 서버 내부에서 돌 수도 있습니다.
속도와 확장성에 더불어, 에러에 대한 높은 탄성도 가지고 있습니다. 그리고 데이터 타입에 매우 유연합니다.
다시한번 말하지만, 엘라스틱서치는 빅데이터를 처리할 때 매우 유용합니다. 백만개의 데이터를 거의 실시간에 검색이 가능하고, 분석이 가능합니다. 이것이 바로 엘라스틱서치가 가진 마법입니다.
하지만 어떻게 이 모든 데이터를 검색할 수 있을까요? 그것을 위해서, 여러분은 쿼리를 사용해야 합니다.
쿼리: 많은 종류의 검색 이를테면 구조화된, 비구조화된 검색을 조합하고 수행할 언어입니다. 여러분은 "무엇이든 원하는대로" 쿼리를 만들 수 있습니다.
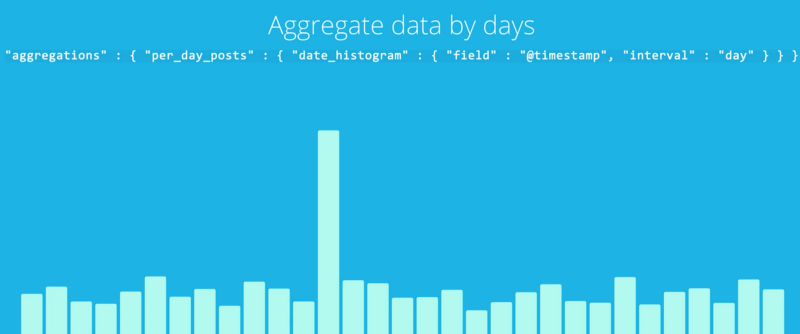
그리고 분석과 관련해서는, 엘라스틱서치는 몇백만줄의 로그를 이해하기 쉽게 해줍니다. 엘라스틱서치가 제공하는 집계(aggregations)는 여러분의 데이터 내부에서의 트렌드와 패턴이 무엇인지 더욱 쉽게 알아볼 수 있도록 해줍니다.
예를 들면, 만일 여러분이 500개의 노드를 가진 클라우드를 갖고 있다면, 여러분은 로그기록들을 엘라스틱서치에 넣음으로써 짧은 시간 이내에 전체 인프라스트럭쳐를 점검할 수 있습니다. 그리고 그 응답을 기반으로, 여러분은 인프라스트럭쳐의 핵심 이슈사항이 무엇인지 알 수 있습니다.
다른 사용 예제
- 특정한 값을 가진 데이터 찾기. 이를테면 23살 이상의 모든 유저를 데이터베이스에서 가져올 수 있습니다.

- 지리적 정보에 의한 검색

- 날짜에 의한 집계
엘라스틱서치를 쓰는 고객들
Mozila, GitHub, Stack Exchange, Netflix, 그리고 많은 유저들이 엘라스틱서치를 사용합니다.
이제 엘라스틱서치에 대해 조금 알았을 것입니다. 그럼 실용적인 부분에 대해 학습해봅시다.
설치
엘라스틱서치를 설치하기 위해서는, 여러분은
- 자바를 설치해야 합니다. 8버전이나 그보다 높은 버전을 설치해야합니다.
- 엘라스틱서치를 설치해야 합니다. elastic.co에서 다운로드할 수 있습니다. 그리고 여러분의 운영체제에 맞춘 몇가지 단계를 따라가면 됩니다. 만일 여러분이 Homebrew가 설치된 맥 운영체제를 사용한다면, 그냥
brew install elasticsearch명령어 한 줄로 간단하게 엘라스틱서치를 설치할 수 있습니다.
인터페이스
엘라스틱서치를 사용하기 위해, 여러분은 인터페이스가 필요할 것입니다. 여기에서는 Kibana를 사용할 것입니다. 엘라스틱서치의 데이터를 다루고 시각화하기 위한 아주 좋은 웹 인터페이스입니다.
elastic.co에서 다운로드할 수도 있고 다음 단계를 따라가도 설치할 수 있습니다. 만일 Homebrew가 설치된 맥OS를 이용 중이라면 다음 커멘드를 입력하면 됩니다. brew install kibana
엘라스틱서치와 키바나를 위해 호환되는 같은 버전을 다운로드할 필요가 있습니다.
미래에, 엘라스틱서치와 상호작용할 소프트웨어를 개발할 필요가 있을 때, 여러분은 엘라스틱서치와 통신하기 위해 다음과 같은 프로그래밍 언어를 사용 가능합니다.
- Java
- C#
- Python
- JavaScript
- PHP
- Perl
- Ruby
기본 개념
이제 여러분은 키바나와 엘라스틱서치를 설치했습니다. 일단 사용 전에, 엘라스틱서치에 관한 몇가지 유용한 개념을 알고 갑시다.
엘라스틱 서치는 다음과 같은 구성요소로 만들어졌습니다.
클러스터(Cluster)
클러스터는 모든 데이터를 함께 가지고 있는 한개 또는 그 이상의 노드의 집합입니다. 클러스터는 연합된 인덱싱과 모든 노드를 검색할 수 있는 기능을 제공합니다. 그리고 클러스터는 유일한 이름(unique name)으로 판별(identified)됩니다. (기본 값은 'elasticsearch'입니다.)
노드(Node)
노드는 클러스터의 일부로 단일서버입니다. 노드는 데이터를 보관하고 클러스터 인덱싱과 검색 능력에 관여합니다.
인덱스(Index)
인덱스는 비슷한 특성을 가진 도큐먼트(Document)의 집합입니다. 그리고 이름으로 구분됩니다. 이 이름은 인덱싱, 검색, 업데이트, 삭제를 수행하는 동안에 인덱스를 참조하기 위해 사용됩니다. 그리고 삭제 명령은 인덱스 내부의 도큐먼트에 대해 이뤄집니다. 단일 클러스터에서, 여러분은 원하는 만큼 많은 인덱스를 정의할 수 있습니다.
도큐먼트(Document)
도큐먼트는 인덱싱될 수 있는 정보의 기본 단위입니다. 도큐먼트는 유비쿼터스 인터넷 데이터 교환 포맷인 JSON으로 표현됩니다.
샤드(Shards)
엘라스틱서치는 인덱스를 샤드라 불리는 여러개의 조각으로 다시 나눌 수 있는 기능을 제공합니다. 각각의 샤드는 그 자체의 내부에서 완전히 기능하며 클러스터 내부의 어떤 노드에서도 관리될 수 있는 독립된 "인덱스"입니다. 인덱스가 단일 노드에 들어가면, 단일 노드 내의 디스크 사용 가능 공간보다 더 많은 공간을 차지할 때, 샤드가 유용합니다. 다른 노드들 사이에서 인덱스는 그 때 다시 한번 또 나누어집니다. 게다가, 샤드는 여러분이 샤드를 거쳐 명령을 분배하고 병렬적으로 처리될 수 있게 해주어 퍼포먼스를 올려줍니다.
레플리카(Replicas)
'레플리카 샤드' 또는 '레플리카'로 불리는 것들은 여러분의 인덱스의 샤드에 대한 한개 이상의 복사본입니다. 노드가 깨졌을 때를 대비하여 높은 가용성을 제공합니다. 그리고 레플리카는 여러분의 검색이 모든 레플리카에서 병렬적으로 실행될 수 있게 해주기 때문에 검색의 볼륨 스케일업을 해줄 수 있습니다.
엘라스틱서치, 키바나 실행하기
이제 직접 엘라스틱서치를 다뤄봅시다. 엘라스틱서치가 설치된 곳으로 가서 다음 명령어를 실행해주세요.
./elasticsearchHomebrew를 이용해서 설치한 분들은 엘라스틱서치가 설치된 디렉토리로 갈 필요없이 elasticsearch만 터미널에 쳐보시면 실행이 될 것입니다.
엘라스틱서치 시작됨
이제 엘라스틱서치가 실행되었으니, 다른 터미널을 열고 키바나를 실행해봅시다. 키바나가 설치된 디렉토리로 가서 ./kibana 명령어를 입력하시면 됩니다. Homebrew를 이용하여 설치했다면 터미널에서 $kibana를 입력하시면 됩니다.
키바나 시작됨
만일 알맞게 명령어를 입력했다면, 두개 전부 올바르게 실행되고 있을 것입니다. 확인하기 위해서는 웹브라우저를 켜고 http://localhost:9200에 접속해보시면 됩니다.
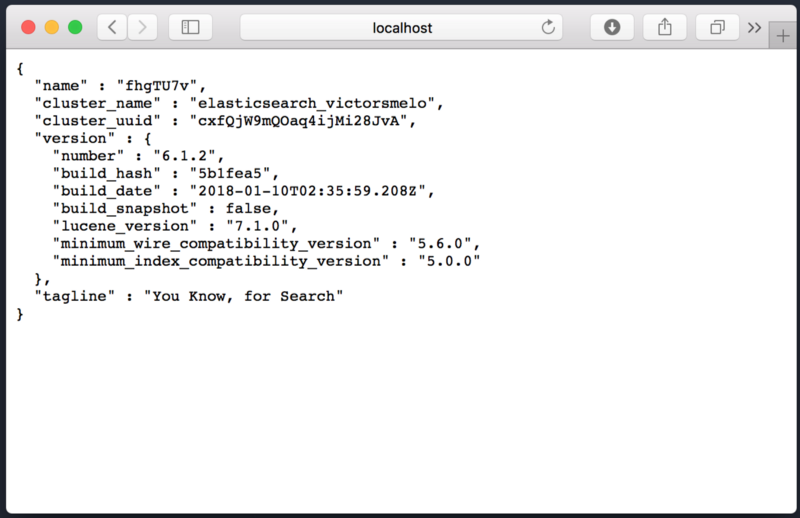
엘라스틱서치가 실행중임을 나타내는 화면
위와 비슷한 화면이 나왔다면, 엘라스틱서치가 제대로 실행되고 있다는 뜻입니다.
키바나 인터페이스를 보고싶다면, http://localhost:5601에 접속해보시면 됩니다.
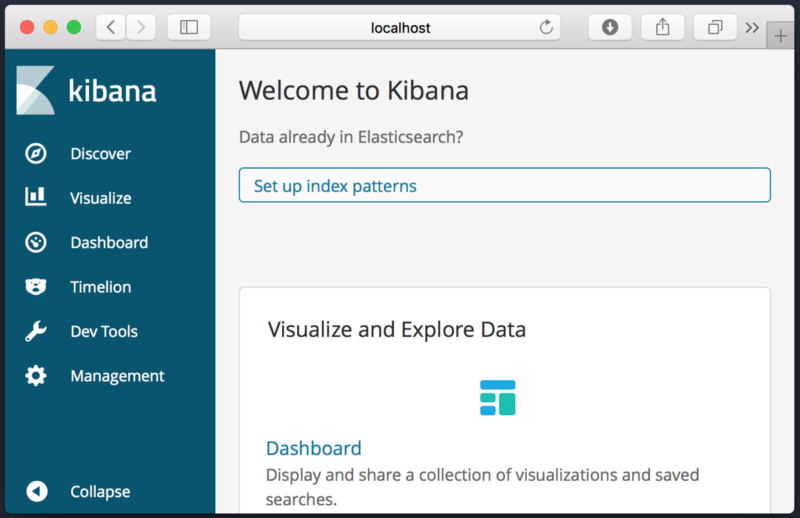
키바나 인터페이스
명령어
키바나 인터페이스에서, 메뉴에서 Dev Tools를 선택하세요. 왼쪽에 명령어를 입력할 수 있는 콘솔이 보이고 오른 쪽에는 결과를 나타내는 창이 보일 것입니다.
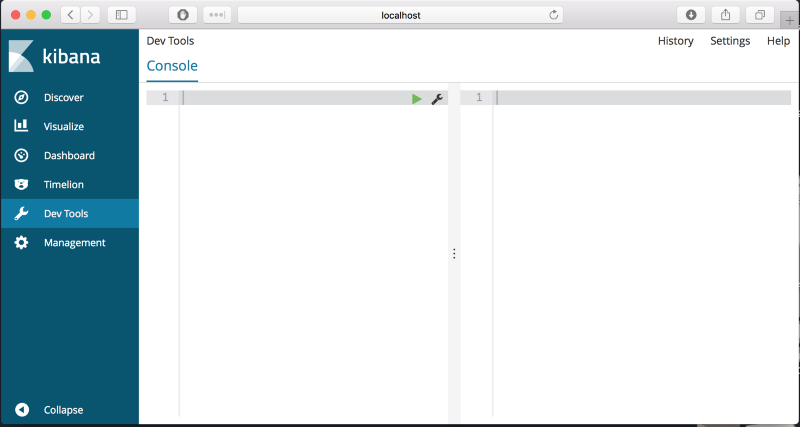
데이터를 다루기 위한 명령어를 알아봅시다.
PUT
PUT 명령어는 새로운 document를 엘라스틱서치에 삽입하도록 허용해줍니다. 아래의 코드를 콘솔에 입력하고 초록색 play 버튼을 눌르고 결과를 봅시다.
PUT /my_playlist/song/6
{
"title" : "1000 years",
"artist" : "Christina Perri",
"album" : "Breaking Dawn",
"year" : 2011
}결과가 다음과 같이 나올 것입니다.
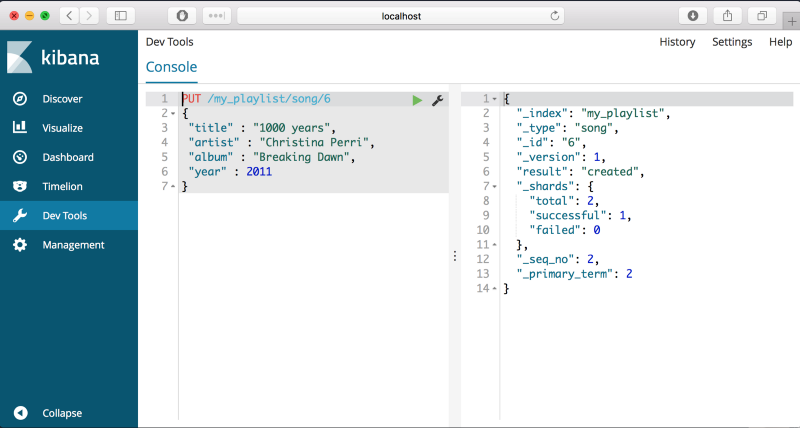
위의 결과가 의미하는 것은 엘라스틱서치에 document가 하나 추가됐따는 것입니다. 예제에서와 같이 우리는 /my_playlist/song/6에 노래 데이터가 하나 있습니다.
my_playlist: 여러분의 데이터가 들어갈 인덱스의 이름입니다.song: 만들어질 document의 이름입니다.6: 엘리먼트 인스턴스의 아이디입니다. 이 경우에는 song id입니다.
만일 my_playlist가 존재하지 않았다면, 새로운 인덱스인 my_playlist가 만들어질 것입니다. document인 song과 id인 6도 똑같이 만들어집니다.
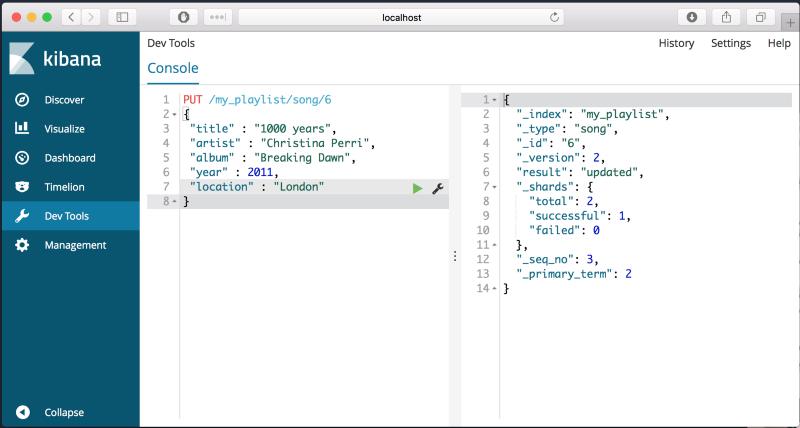
값을 업데이트 하기 위해서는 PUT 명령어를 동일한 document에 사용하면 됩니다. 예를 들면, 새로운 파라미터, 위치를 삽입하고 싶다면, 다음과 같은 방법으로 가능합니다.
PUT /my_playlist/song/6
{
"title": "1000 years",
"artists": "Christina Perri",
"album": "Breaking Dawn",
"year": 2011,
"location": "London"
}결과는 다음과 같습니다.
GET
GET 명령어는 여러분의 데이터에 대한 정보를 가져오도록 해줍니다. 다음 예제를 입력해봅시다.
GET /my_playlist/song/6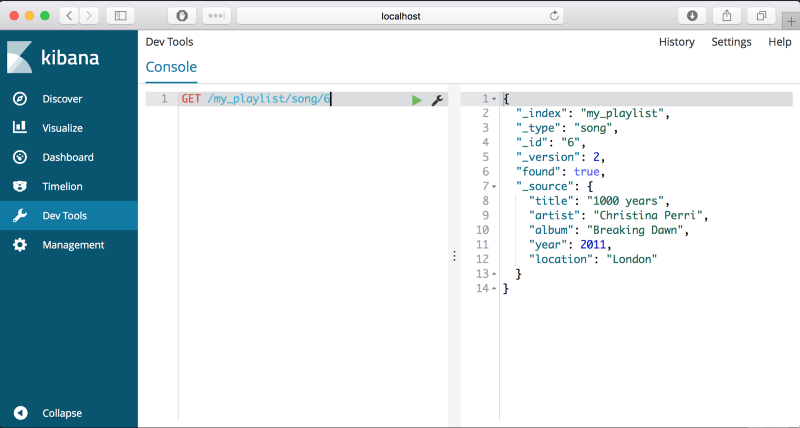
여러분이 방금 추가했던 데이터가 보이죠?
DELETE
document를 삭제하기 위해서는, 다음과 같은 명령어를 입력해보세요.
DELETE /my_playlist/song/6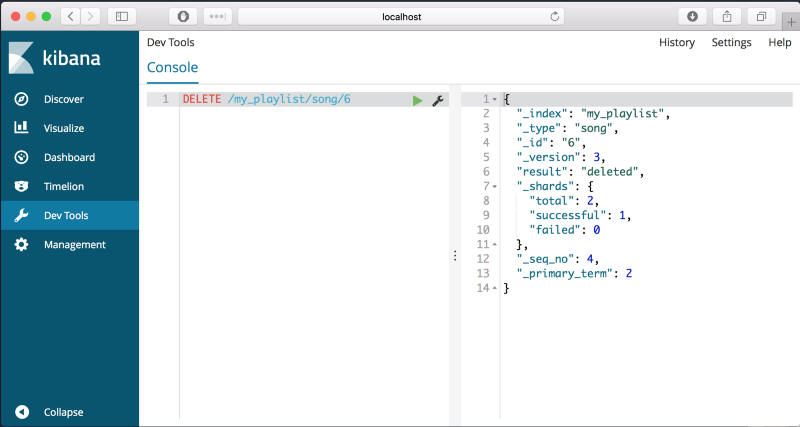
데이터 검색
이제 몇가지 명령어를 사용하는 법에 대해서 알아봤습니다. 하지만, 매우 간단한 예제만 다루어 보았습니다. 엘라스틱서치에 대해 좀 더 깊게 알아가면, 좀 더 복잡한 쿼리도 실행할 수 있습니다.
서로 다른 사용 용례를 가진 검색 API들이 있습니다. 간단하게 설명하기 위해, 몇가지 간단한 예제를 보여줄 것입니다. 만일 간단한 예제보다 좀 더 알고 싶다면, 여기에서 알아보시면 됩니다.
예제에서 사용된 파라미터는 q, URI를 통해 실행되는 쿼리를 나타냅니다.
이 예제에서 우린 accounts라는 예제 데이터를 사용할 건데, 여기에서 다운로드 가능합니다.
엘라스틱서치로 데이터를 불러오기 위해서, 터미널을 열고 파일이 다운로드된 디렉토리로 향하여, 다음과 같은 명령어를 입력해줍시다. curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
만일, search-guard 플러그인이 설치되어 있다면 --user
id:pw의 옵션을 추가해주어야 합니다.
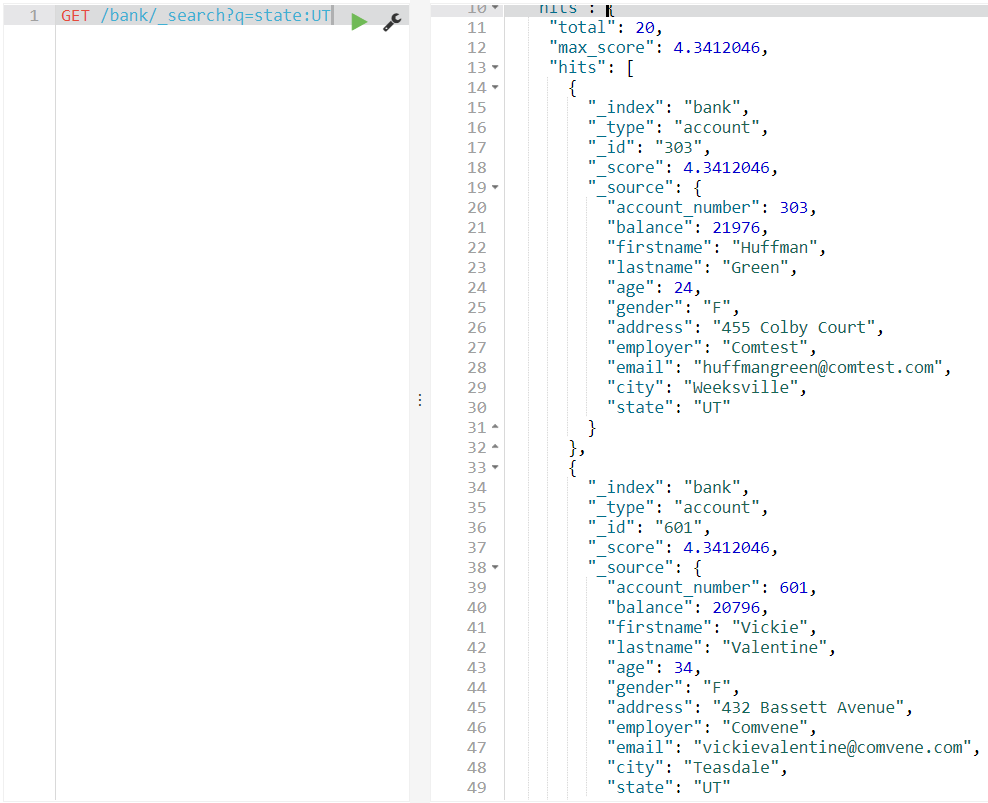
state가 UT인 모든 데이터 가져오기
state가 UT인 데이터 가져오기
GET /bank/_search?q=state:UT
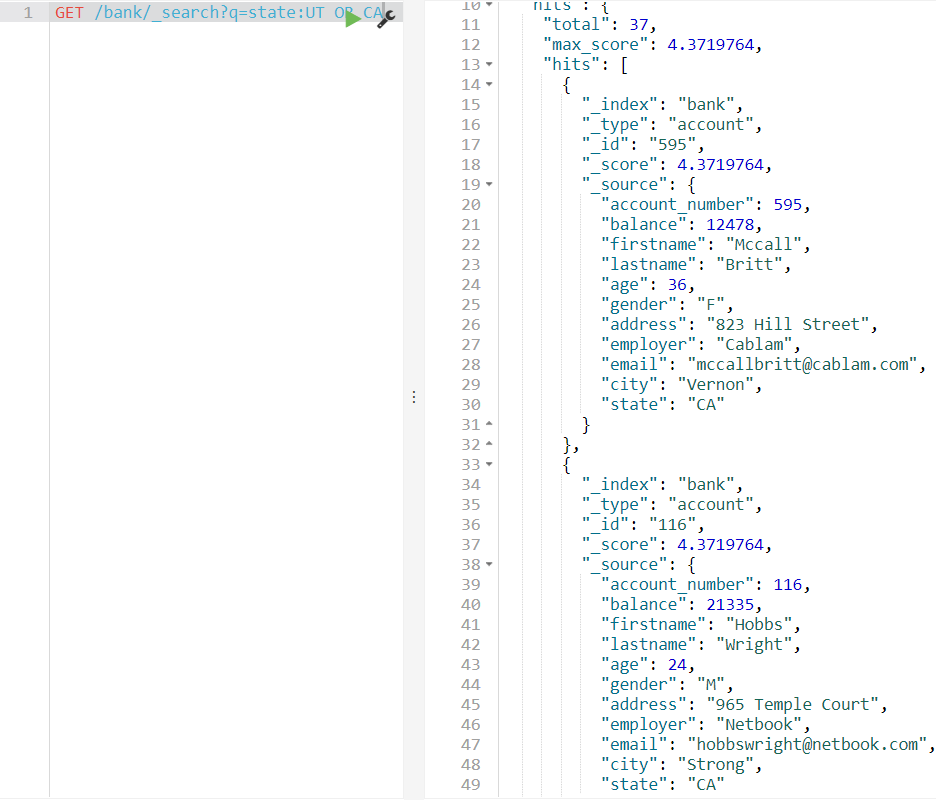
state가 UT이거나 CA인 데이터 가져오기
GET /bank/_search?q=state:UT OR CA
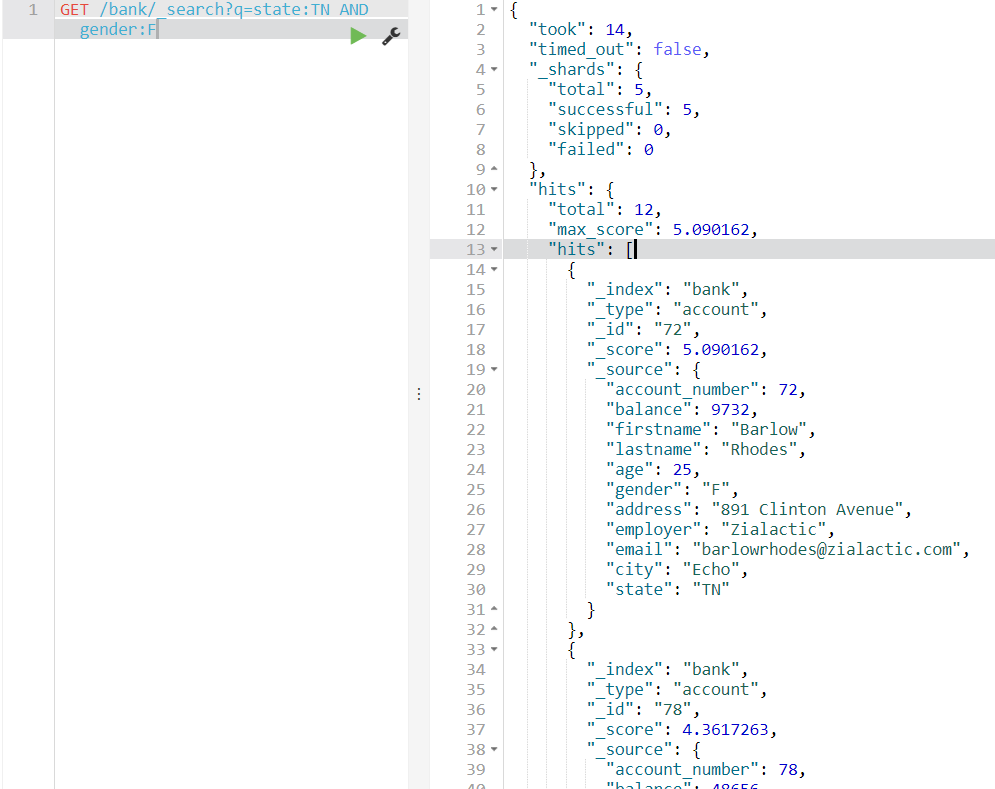
state가 TN이면서 여성(female)인 데이터 가져오기
GET /bank/_search?q=state:TN AND gender:F
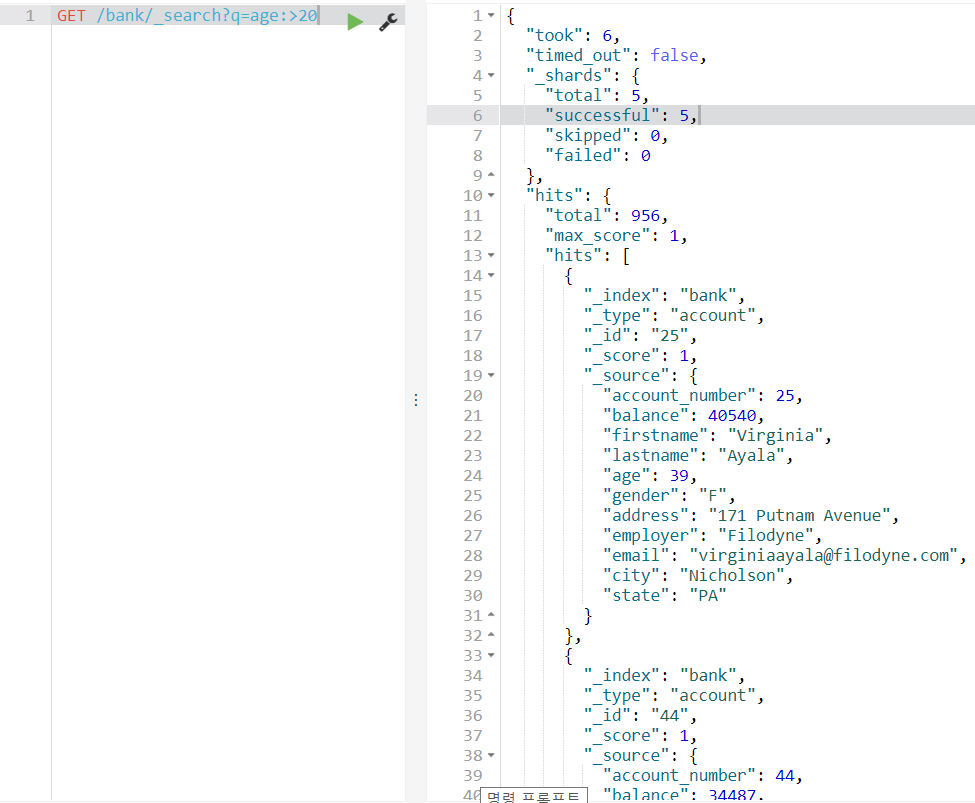
20살보다 많은 나이를 가진 사람들 가져오기
GET /bank/_search?q=age:>20
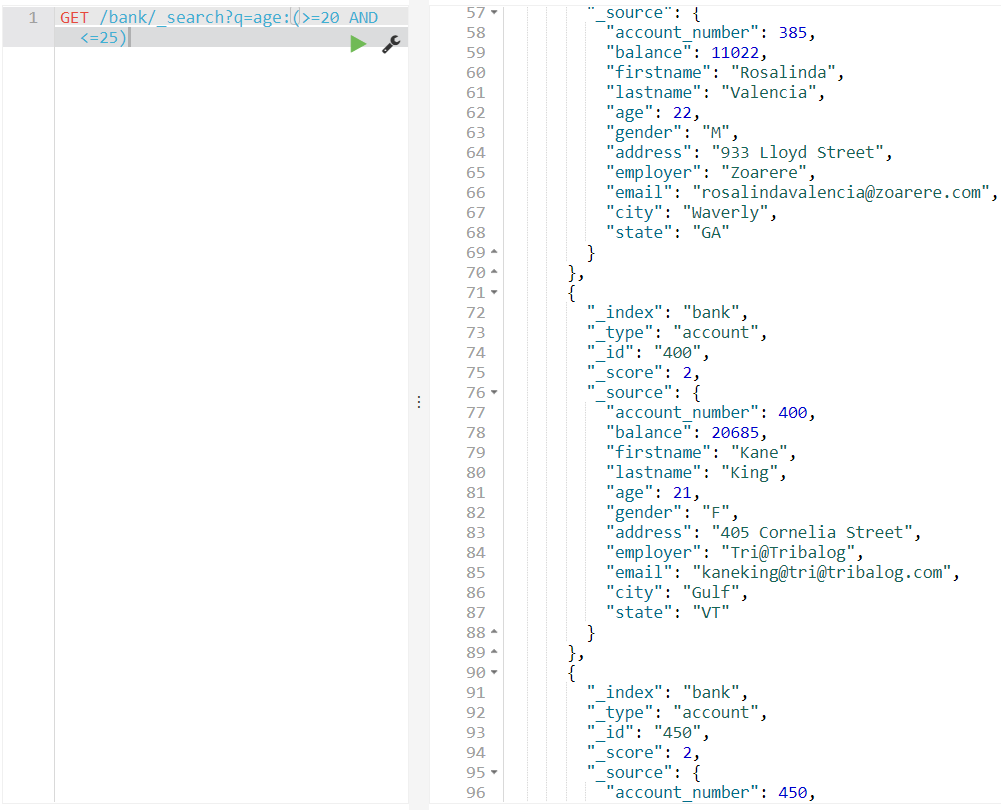
20살과 25살 사이의 데이터 가져오기
GET /bank/_search?q=age:(>=20 AND <=25)
쿼리 DSL을 이용한 간단한 예제들
URI방식으로 날리는 쿼리는 엘라스틱서치 쿼리를 이용하기에 가장 최적화된 방법은 아닐 수 있습니다. URI방식보다는 QueryDSL을 사용하는 것이 조금 더 선호되는 방법이라고 볼 수 있습니다. 아래의 내용은 QueryDSL에 대한 짧은 설명과 예제입니다. 더 많은 내용을 원한다면, 여기에서 QueryDSL에 대한 내용을 더 찾아볼 수 있습니다.
QueryDSL을 쿼리의 AST(Abstract Syntax Tree) 로 생각하세요. 단, 다음 2가지 종류의 구문을 갖고 있는 AST 입니다.
여기서 잠깐! AST란?
본문엔 없는 내용이지만 AST를 잘 모르시는 분들도 있을 것 같아 추가적 설명을 첨부합니다.
AST란
while b ≠ 0
if a > b
a := a − b
else
b := b − a
return a위와 같은 의사 코드를 아래와 같은 그림으로 바꾼 것을 말합니다.
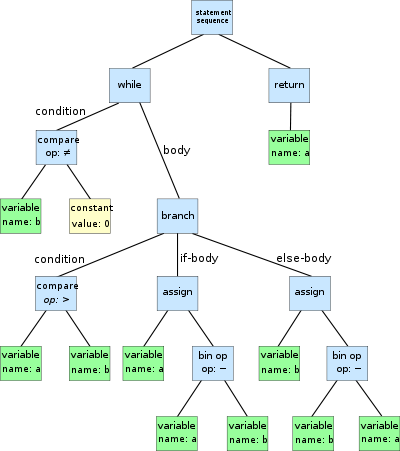
추상구문트리(AST, abstract syntax tree)란 프로그래밍 언어로 작성된 소스코드의 추상적인 문법 구조의 표현을 트리의 방식으로 한 것이다. 트리의 각 노드는 소스코드 내부에서 존재하는 구조물들을 표현한다. 문법은 "추상적"이다
-
Leaf 쿼리문 : 특정 필드 내부의 특정한 값을 찾습니다. 이를테면 match(정확히 일치), term(조건부), range(범위) 쿼리와 같은 것들이 해당됩니다.
-
Compound 쿼리문 : 다른 leaf 또는 compound 쿼리를 감쌉니다 그리고 다수의 쿼리를 논리적인 방법으로 묶을 때 사용합니다. (이를테면 bool이나 dis_max 쿼리와 같은 것들입니다.) 또한 쿼리의 행위를 수정하기 위해서도 사용합니다. (이를테면 constant_score 쿼리와 같은 것이 있습니다.)
쿼리문은 쿼리문이 쿼리 컨텍스트(query context) 또는 필터 컨텍스트(filter context) 에서 쓰였는지에 따라서 다르게 동작합니다.
-
쿼리 컨텍스트 : 쿼리 컨텍스트에서 쓰인 쿼리문은 다음 질문에 대답합니다. "이 Document가 이 쿼리문에 얼마나 잘 매칭이 되는가?". 그에 대한 정답은 _score 라는 것이 나타내고 있습니다. 다른 문서랑 비교했을 때 이 문서는 얼마나 쿼리문에 잘 맞는지를 보여줍니다.
-
필터 컨텍스트 : 필터 컨텍스트에서 쓰인 쿼리문은 다음 질문에 대답합니다. 이 문서가 쿼리문에 매치가 되는가?. 정답은 간단하게 예 또는 아니오 입니다.
아래는 search API에서 사용되는 쿼리와 필터 컨텍스트 내부 쿼리의 예제입니다. 이 쿼리는 document를 매칭할 것입니다. 단, 다음 조건들이 만족하는 것들로요.
- address 필드에서 Street이라는 단어가 포함되어야 합니다.
- gender 필드에서 f가 정확히 일치하여야 합니다.
- age 필드에서 숫자는 25보다 크거나 같아야 합니다.
GET /_search
{
"query": { //1
"bool": { //2
"must": [
{ "match":{"address":"Street"}} //3
],
"filter": [ //4
{ "term":{"gender":"f"}}, //5
{ "range": { "age": { "gte": 25 }}} //6
]
}
}
}위의 코드를 이해해보자면,
//1 : query 파라미터가 쿼리 컨텍스트임을 나타냅니다.
//2, //3 : bool과 match 문이 쿼리 컨텍스트에서 사용되었습니다. 두 개는 각 문서가 얼마나 잘 매치되는지 점수를 내기 위해서 사용됩니다.
//4 : filter 파라미터는 필터 컨텍스트임을 나타냅니다.
//5, //6 : term과 range 절이 필터 컨텍스트에서 사용되었습니다. 두 개의 절은 매치되지 않는 document를 필터링할 것입니다. 하지만 매치되는 document들의 점수에 영향을 주진 않습니다.
Tip : 매치되는 document들에 대한 점수에 영향을 주고 싶다면 쿼리 컨텍스트 내에서 쿼리 절을 사용하세요. 그리고 다른 쿼리들은 필터 컨텍스트에서 사용하세요.
이제 여러분은 엘라스틱서치가 무엇인지 그리고 어떻게 insert, update, delete를 하는지 어떻게 검색을 하는지에 대해 알게 됐습니다. 키바나는 엄청나게 많은 기능을 지니고 있습니다. 데이터를 볼 수 있고, 다른 그래픽으로 나타낼 수도 있습니다. 키바나의 모든 기능들을 살펴보는 것을 권장합니다.
엘라스틱서치에 대해 더 많은 거슫ㄹ이 있습니다. 여기서 제가 아렬드린 것은 단지 엘라스틱서치를 이해하기 위한 첫걸음에 지나지 않습니다. 이 글을 읽은 뒤에, 키바나 인터페이스와 엘라스틱서치 문서들을 꼭 살펴보세요. 어떻게 복잡한 쿼리를 만드는지 등등에 대해서 알아보는 것도 좋습니다.
이 글이 여러분께 도움이 되었으면 좋겠습니다. 그리고 이제는 더 적은 노력으로 다른 문서에 대해서 또 볼 수 있을 것입니다.
레퍼런스



좋은 글 번역해주셔서 정말 감사합니다. 꾸벅