이것이 자바다 정리 #16 스트림
이것이 자바다 책을 참고하였습니다.
스트림 소개
자바 8버전부터 추가된 컬렉션 요소를 하나씩 참조해서 람다식(함수적 인터페이스)으로 처리할 수 있도록 해주는 반복자이다.
자바 8 이전에는 컬렉션 처리에는 무조건
Iterator가 이용되었으나, 선택의 폭이 넓어졌다.
함수적 인터페이스 복습
스트림에서는 함수적 인터페이스를 적극 활용하기 때문에 함수적 인터페이스를 제대로 알고 가면 도움이 된다.
참조링크: 이것이 자바다 정리 #14 람다식
Consumer
매개 값: O(타입:T)리턴 값: X- 값을 소비하고 리턴하지 않음
- 내부 메소드:
.accept()
Supplier
매개 값: X리턴 값: O(타입:T)Consumer와 반대로 값을 만들기만하고 소비하지 않음- 내부 메소드:
.get()
Function
매개 값: O(타입:T)리턴 값: O(타입:A)- 주로 매개 값을 리턴 값으로 매핑하는데 사용됨
- 보통 매개 값과 리턴 값의 타입이 다름
- 내부 메소드:
.apply()
Operator
매개 값: O(타입:T)리턴 값: O(타입:T)- 주로 매개 값을 이용한 연산 후 결과를 리턴함
- 보통 매개 값과 리턴 값의 타입이 같음
- 내부 메소드:
.apply()
Predicate
매개 값: O(타입:T)리턴 값: O(타입:boolean)- 매개 값을 이용한 조건식을 통해
true혹은false를 반환 - 내부 메소드:
.test()
스트림 특징
- 람다식을 이용한다.
- 병렬 처리가 용이하다.
- 내부 반복자를 사용한다.
외부 반복자와 내부 반복자 비교
외부 반복자(external iterator): 개발자가 코드로 직접 컬렉션 요소를 반복해서 가져오는 코드 패턴이다.for,iterator,while등
내부 반복자(internal iterator): 컬렉션 내부에서 요소들을 반복시키고, 개발자는 요소당 처리해야 할 코드만 제공하는 코드 패턴이다.
스트림은 내부 반복자를 사용한다.
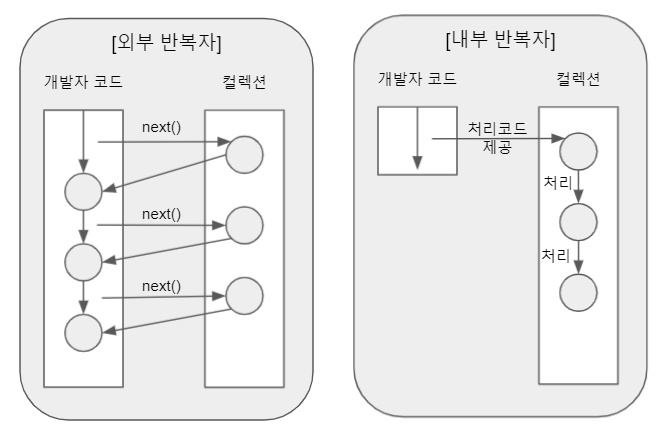
내부 반복자는 처리코드만 제공하고 처리를 위임하여 병렬 처리가 컬렉션 내부에서 일어나게 만들 수 있다.
외부 반복자는 요소를 가져오는 것부터 처리하는 것까지 모두 개발자가 작성해야 한다.
내부 반복자의 이점
- 개발자는 요소 처리 코드에만 집중할 수 있다.
- 내부 반복자는 반복 순서 변경이나 멀티코어 CPU 활용을 위해 요소들을 분배시켜 병렬작업이 가능하다.
- 처리할 것들을 부분으로 나누어 병렬작업을 한 뒤 다시 합치는 방식이다.
병렬처리 예제 코드 및 결과
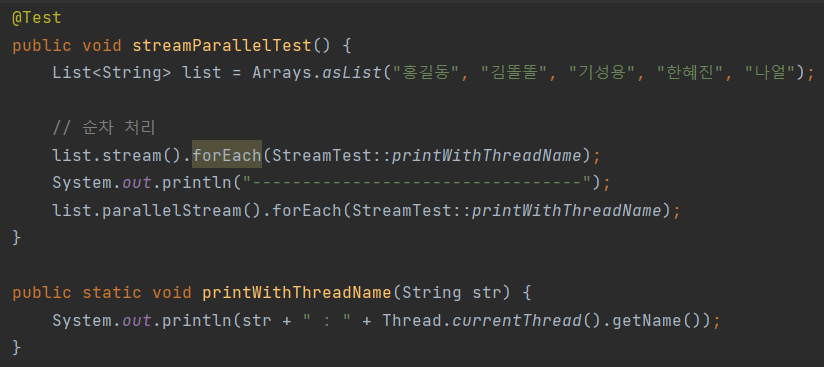
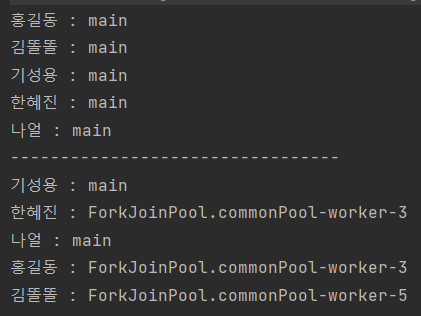
병렬처리 예제 코드를 작성해보고 실행해보았다. 병렬처리를 하고 싶으면 간단하게 .parallelStream()을 이용하여 메소드 체인을 작성하면 된다.
또, .stream()으로 메소드 체인을 시작했더라도 .parallel() 메소드를 통해서 체인을 이어나가면 이어지는 부분을 병렬처리 할 수 있다.
스트림의 중간처리와 최종처리 개념
스트림은 중간처리(Intermediate Operation)와 최종처리(Terminal Operation) 개념이 있는데, 두 페이즈를 명확히 나누는 편인 것 같다.
중간처리:매핑(mapXxx),필터링(filter, distinct),정렬(sorted),반복(peek)최종처리:반복(forEach),카운팅(count),평균(average),리듀스(reduce)
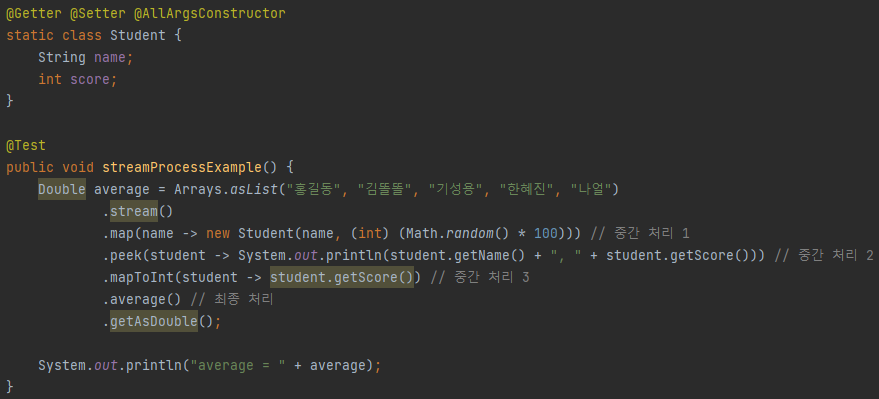
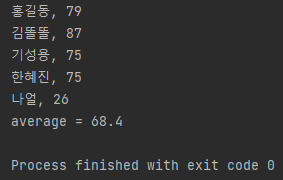
위는 간단히 작성해본 코드인데 map(), peek(), mapToInt()와 같이 필터링, 매핑, 정렬 (+ 반환값이 없는 peek()) 등은 중간처리로 데이터를 가공하는 역할을 한다.
마지막 average()와 같은 집계 혹은 반환 값이 있는 반복인 forEach()와 같은 것들은 최종처리로 결과물을 내는 역할을 한다.
스트림의 중간처리 지연 개념
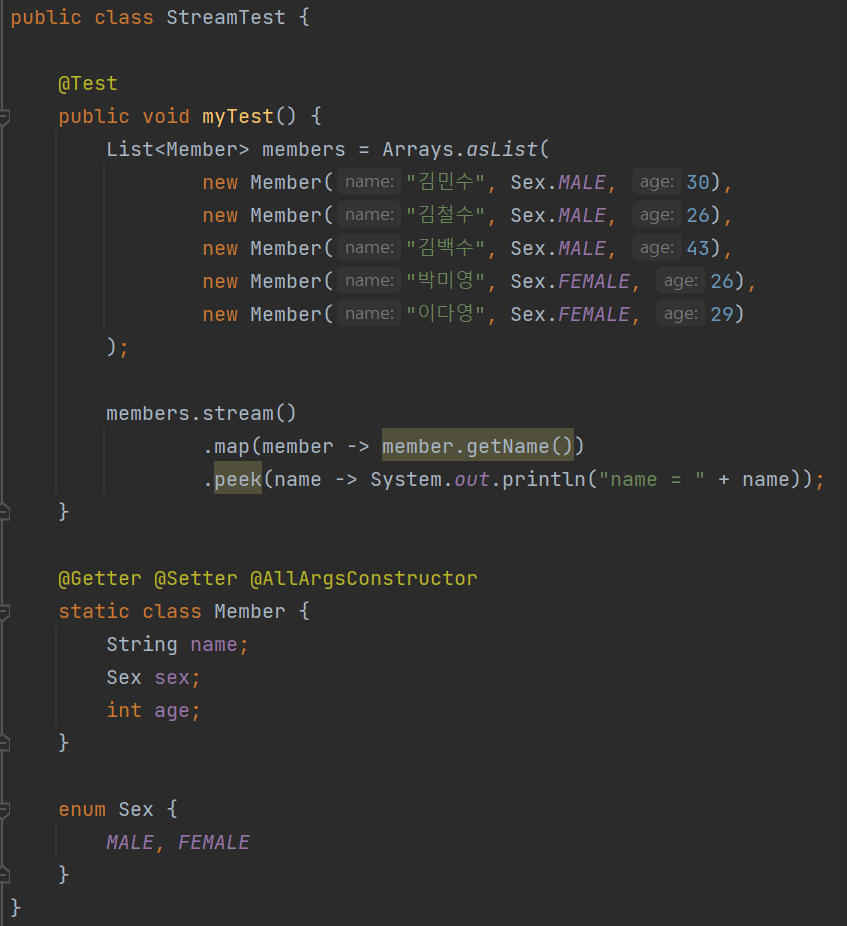
위 코드의 실행 결과는 무엇일까?

바로 아무것도 나오지 않는다는 것이다. 왜일까? 분명 프린트를 했는데, 정답은 지연(lazy) 처리에 있다.
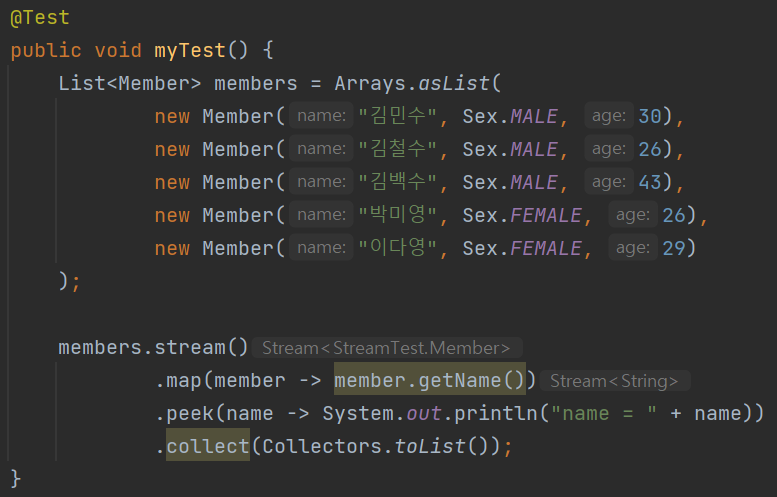
myTest 메소드의 내용은 이전과 동일한데 마지막에 .collect() 메소드만 추가되었다. 그렇게 하니까 .peek() 내부에 위치해있던 처리 내용인 print()가 올바르게 동작한다.
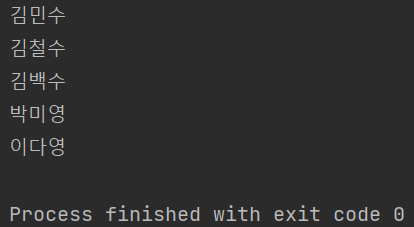
Stream은 해당 데이터로 최종 처리를 해야만 중간처리 과정을 수행한다.
최종 처리 전까지는 스트림은 연산을 미룬다. (lazy)
하위 스트림
스트림의 하위 스트림에는 여러가지 종류가 있다. IntStream, DoubleStream과 같이 단순 숫자 타입에 관한 스트림도 있고 특이한 하위 스트림도 있다.
숫자 스트림
IntStream과 같은 스트림을 말한다. 이러한 스트림에는 다른 스트림에 없는 특이한 메소드가 존재하는데, 이를테면 IntStream.range(int, int)와 같은 메소드로 특정한 숫자의 범위를 스트림으로 만들 수 있다.

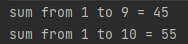
위와 같이 range() 혹은 rangeClosed()를 활용해 숫자 범위에 대한 연산 등을 쉽게 할 수 있다.
디렉토리 스트림
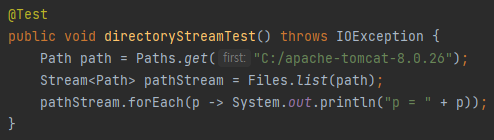
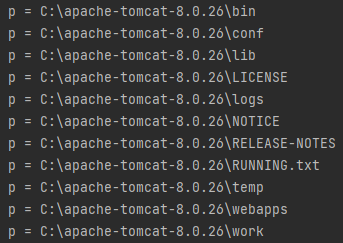
위와 같이 경로를 입력하여 특정 경로의 디렉토리 스트림을 얻을 수 있다.
파일 스트림
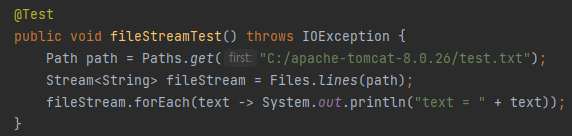
파일의 경로를 입력하면 해당 파일이 가진 내용을 스트림으로 얻을 수 있다. 위는 라이센스 내용이 적혀있는 텍스트 파일을 읽어보았다.
랜덤 스트림
위와 같이 특정한 범위를 랜덤으로 얻을 수 있는 랜덤 스트림도 있다. .ints()외에 .longs(), .doubles()등도 존재한다.
필터링
.distinct():Object.equals()가true인 객체를 중복으로 판단하고 제거한다..filter():Predicate수행 결과false인 객체를 제거한다.
distinct 예제
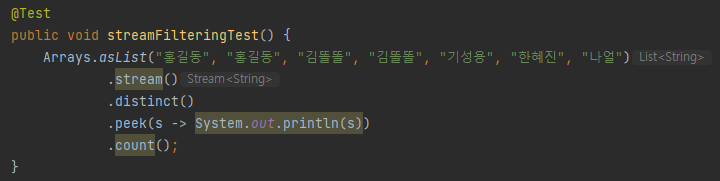
위의 문자열 목록에 홍길동과 김똘똘이 두번 나오는데, 출력 해보면..
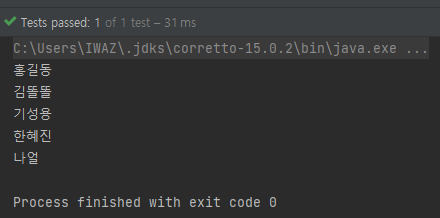
위와 같이 중복된 요소가 제거된 것을 볼 수 있다.
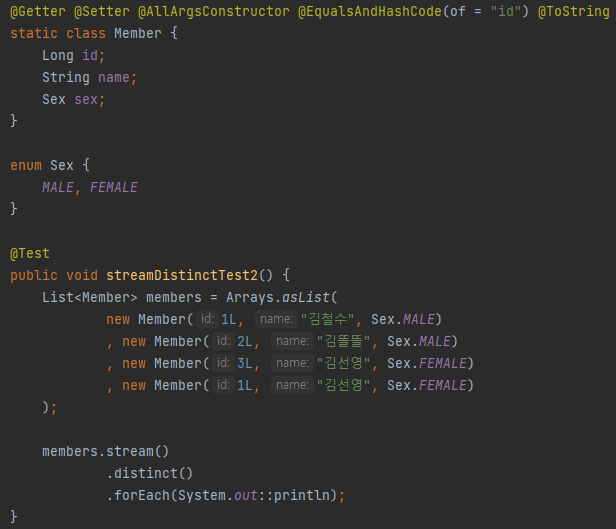
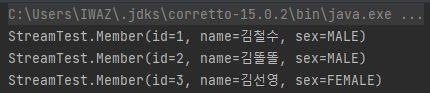
위는 @EqualsAndHashCode()를 이용하여 Objects.equals()를 id 필드에 의해 판별되게 하고 그것을 이용해 중복을 지워본 것이다.
filter 예제
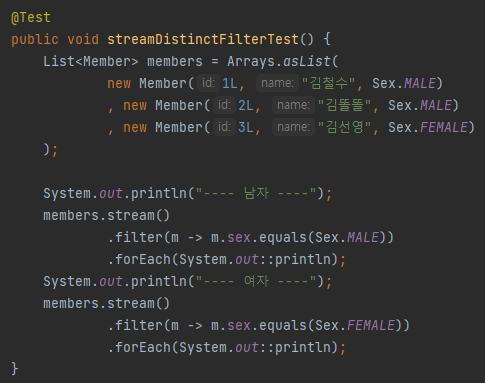
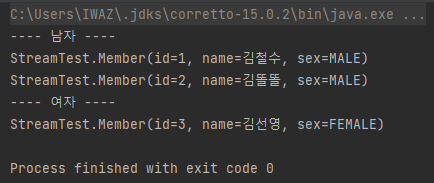
간단하게 남자 여자를 필터로 나눠보았다.
매핑
.flatXxx(): 각 요소의 값을 이용하여 원래 스트림의 길이보다.mapXxx(): 각 요소의 값을 이용하여 변환된 타입의 데이터를 매핑.asXxxStream():.boxed():
flatMap 예제
.flatMap() 메소드를 설명하자면

해당 스트림의 각 엘리먼트에 제공된 매핑 함수가 적용되어 그 결과를 가진 스트림을 반환한다. 해당 스트림으로 결과가 위치한 후에 각 매핑된 스트림은
closed된다. (만일 그 결과가null이라면, 빈 스트림이 사용된다.)
동작에 비해 설명 문장이 너무 어려운데 그냥 각 엘리먼트로 각 스트림을 만들고 그걸 다시 커다란 하나의 스트림으로 합친다고 생각하면 될 것 같다.
flatMapToInt 예제

사실상 잘 안쓰게 될 것 같긴 하지만, .flatMapToInt()와 같이 마지막 형태를 정해놓는 메소드도 있다.
boxed 예제
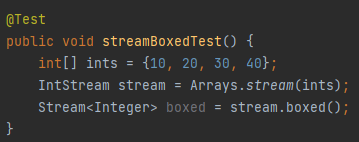
특정한 이유에서 IntStream과 같은 형태에서 Stream<Integer>로 바꾸려면 .boxed() 메소드를 이용하면 편리하다. 말 그대로 primitive 타입을 박싱해주는 역할이다.
sorted 예제
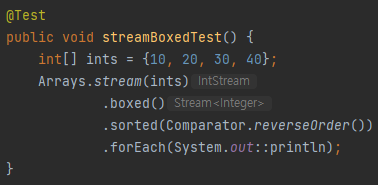
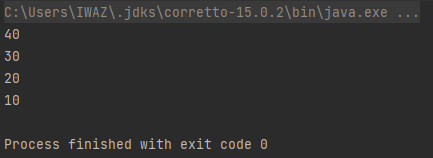
위 코드에서는
Integer의compareTo()를 이용하기 위해서boxed()도 같이 써주었다.
Comparator.reverseOrder()는 구현된compareTo()메소드를 반대로 적용한다.
.sorted() 메소드는 Comparable 인터페이스를 상속하여 .compareTo() 메소드를 구현한 클래스에 대해서는 자동으로 정렬을 해준다. 구현되지 않은 클래스는 바로 익명 구현 객체를 만들면 된다. 혹은 구현된 방식으로 정렬하기 싫을 때도 익명 구현 객체를 작성해주면 된다.
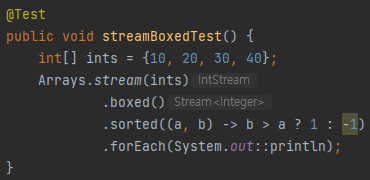
위와 같이 구현해도 결과는 같다.
루핑
루핑은 peek()과 forEach()가 있다. 두 루핑의 차이는 peek()은 중간 처리 메소드이며, forEach()는 최종 처리 메소드이다.
forEach()는 최종 처리 메소드이기 때문에 이후에sum()과 같은 또 다른 최종 처리 메소드를 또 호출할 수 없다.
집계
sum()count()average():Optional을 반환한다.max():Optional을 반환한다.min():Optional을 반환한다.
이름 그대로의 의미를 가지고 있다. 당연히 최종 처리 메소드이다.
Optional 클래스
Optional 클래스는 아래와 같은 기능들을 제공한다.
- 집계 값이 존재하지 않는 경우 디폴트값 설정 가능
- 집계 값을 처리하는
Consumer도 등록 가능
메소드들
isPresent(): 값이 저장됐는지 여부를boolean으로 반환한다.orElse(T): 값이 저정되지 않은 경우, 디폴트 값을 지정할 수 있다.ifPresent(Consumer): 값이 저장된 경우Consumer를 이용해 값을 처리할 수 있다.
커스텀 집계 .reduce()
기본 집계 메소드 이외에 원하는 집계 방식이 있다면 .reduce()를 통해 구현할 수 있다.
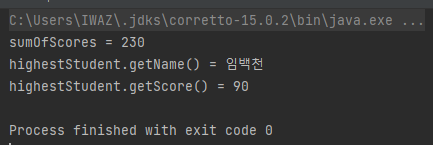
reduce 예제
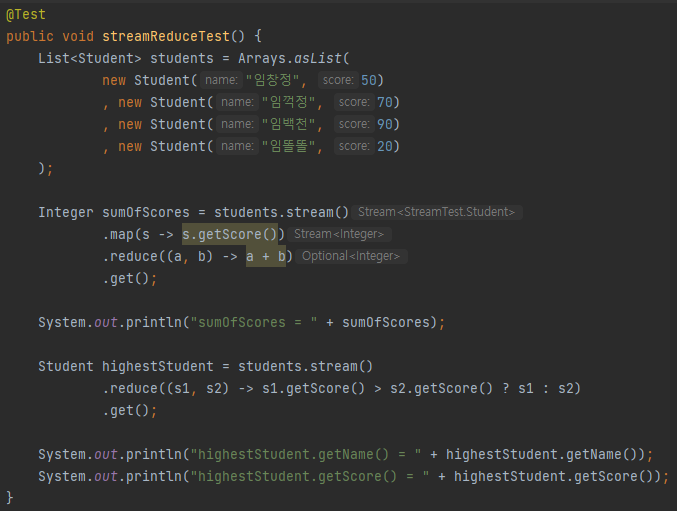
학생들 점수의 총합을 구하는 것과 가장 높은 점수를 가진 학생을 뽑는 예제를 작성해보았다.
수집 .collect()
스트림의 결과를 새로운 컬렉션으로 만들 때 사용되며, 당연히 최종 처리 메소드이다.
R collect(Collector<T, A, R> collector)
위의 형태가 .collect() 메소드의 기본형이다. T는 타입이며, A는 Accumulator이고 R은 결과의 타입을 말한다.
Collectors 지원 메소드
Collectors 클래스에선 .collect()를 편리하게 쓸 수 있도록 정적 메소드를 지원한다. 이를테면 .collect(Collectors.toList)와 같은 방식으로 사용하여 스트림을 List 형태의 데이터로 반환받을 수 있다.
Collector<T, ?, List<T>> Collectors.toList():T를List에 저장Collector<T, ?, Set<T>> Collectors.toSet():T를Set에 저장Collector<T, ?, Collection<T>> Collectors.toCollection(Supplier<Collection<T>>):T를Supplier가 제공한Collection에 저장Collector<T, ?, Map<K, U>> toMap(Function<T, K> keyMapper, Function<T, U> valueMapper):T를K와U로 매핑해서K를 키로U를 값으로 맵에 저장Collector<T, ?, ConcurrentMap<K, U>> toConcurrentMap(Function<T, K> keyMapper, Function<T, U> valueMapper):T를K와U로 매핑해서K를 키로U를 값으로ConcurrentMap에 저장
누적기 부분이
?로 되어있는 이유는 누적기가 필요 없기 때문이다.
toMap 예제 코드
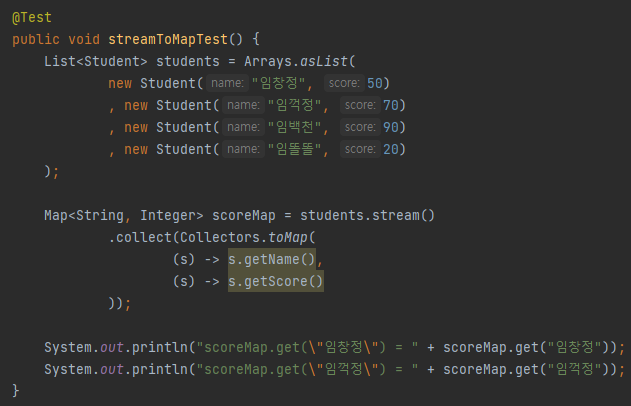
손쉽게 List를 Map으로 바꾸었다.
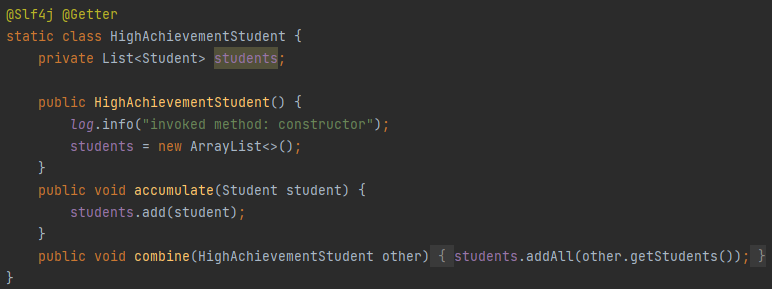
커스텀 컨테이너 Collectors 예제 코드
@Slf4j @Getter
static class HighAchievementStudent {
private List<Student> students;
public HighAchievementStudent() {
log.info("invoked method: constructor");
students = new ArrayList<>();
}
public void accumulate(Student student) {
students.add(student);
}
public void combine(HighAchievementStudent other) {
students.addAll(other.getStudents());
}
}
@Slf4j
static class LogMethodInterceptor implements MethodInterceptor {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
log.info("invoked method: {}", method.getName());
return methodProxy.invokeSuper(o, objects);
}
}
@Test
public void streamCollectCustomContainerTest() {
List<Student> students = Arrays.asList(
new Student("임창정", 50)
, new Student("임꺽정", 70)
, new Student("임백천", 90)
, new Student("임똘똘", 20)
);
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(HighAchievementStudent.class);
enhancer.setCallback(new LogMethodInterceptor());
HighAchievementStudent proxy = (HighAchievementStudent) enhancer.create();
Supplier<HighAchievementStudent> supplier = () -> proxy;
BiConsumer<HighAchievementStudent, Student> accumulator = HighAchievementStudent::accumulate;
BiConsumer<HighAchievementStudent, HighAchievementStudent> combiner = HighAchievementStudent::combine;
students.stream()
.filter(s -> s.score >= 70)
.collect(supplier, accumulator, combiner);
}
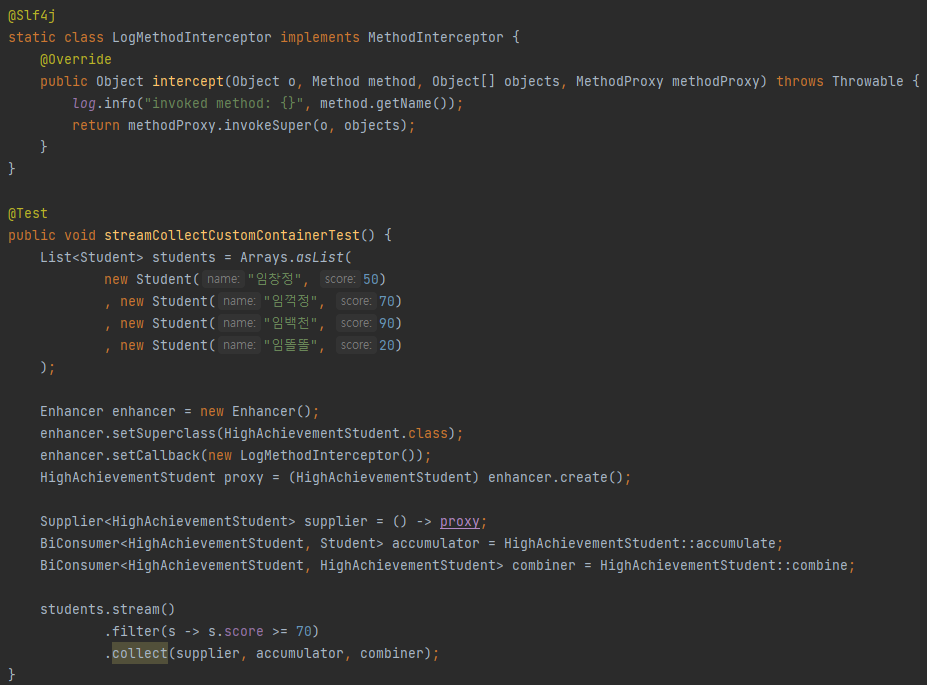
점수가 70점 이상인 학생만 들어갈 수 있게 .filter()를 걸고 .collect() 메소드를 통해 HighAchievementStudent 컨테이너에 담았다.
supplier에 쓰인 HighAchievementStudent는 cgLib을 이용한 프록시로 생성되어 메소드 호출 시마다 자신이 호출한 메소드를 출력한다.

위와 같은 결과가 출력된다.
오직 accumulator만을 이용해 리스트를 쌓아간다. 그렇다면, combiner은 언제 쓰일까? combiner는 병렬 처리를 할 때만 사용된다.
.groupingBy() 예제 코드 1
Collectors.groupingBy()는 Map 형태의 결과를 반환한다.
함수적 인터페이스 중 Function<T, R>을 이용하여 classifer라는 것을 작성해주고, classifier에서 반환하는 값(<R>)이 key가 된다.
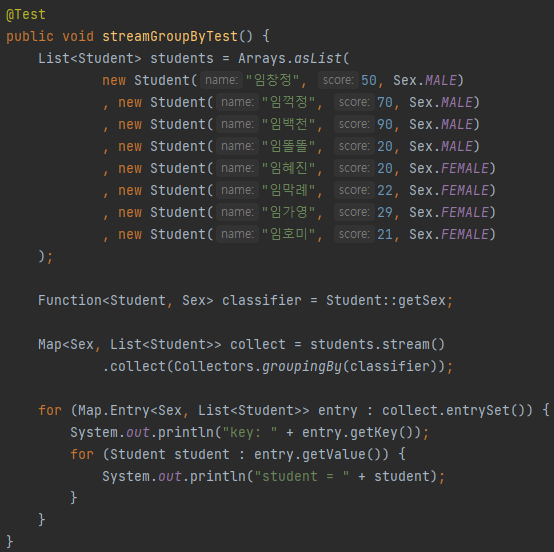
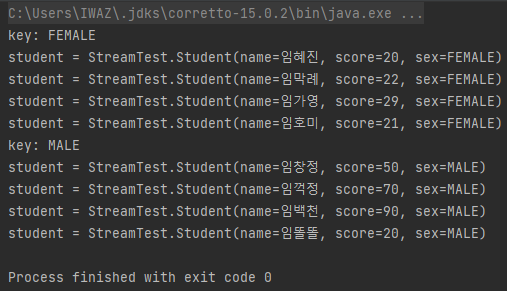
위의 경우에는 key의 타입이 Sex.MALE 혹은 Sex.FEMALE 중 하나가 되며, value의 타입이 List<Student>가 된다.
.groupBy() 예제 코드 2
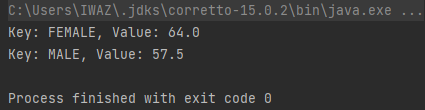
위와 같이, .groupBy() 메소드 내부에 그룹 기준과 집계 함수를 함께 주면, 그룹 기준에 대한 집계가 가능하다.
위는 성별이 그룹 기준이었으며, 평균이 집계 함수인 경우이다.
스트림의 병렬 처리
스트림은 데이터 병렬성을 이용한 병렬 처리를 한다.
병렬처리의 종류
멀티스레드에는 동시성(Concurrency)과 병렬성(Parallelism) 이 있다. 싱글코어에서는 멀티스레드를 이용해도 동시성을 이용한 처리를 이용하여 번갈아가며 처리할 뿐이고, 멀티코어에서 비로소 병럴성을 이용하여 동시에 작업을 처리한다.
병렬 처리라는 카테고리에도 두가지 종류의 병렬 처리가 존재한다. 데이터 병렬성(Data parallelism)과 작업 병렬성(Task Parallelism) 이 존재한다.
데이터 병렬성
데이터 병렬성은 전체 데이터를 쪼개서 서브 데이터로 만들고, 서브 데이터들을 병렬처리해서 작업을 빨리 끝내는 것을 말한다. 자바8에서 지원하는 병렬 스트림은 데이터 병렬성을 구현한 것이다.
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬처리 하는 것을 말한다. 대표적인 예로는 웹서버가 있다. 웹서버는 각각의 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리한다.
포크 조인(ForkJoin) 프레임워크
병렬 스트림은 요소들을 병렬처리 하기 위해서 포크 조인(ForkJoin) 프레임워크를 사용한다.
포크 단계에서 전체 데이터를 서브 데이터로 분리한 뒤에 서브 데이터를 멀티 코어에서 병렬로 처리 후 조인 단계에서 서브 결과를 종합하는 방식이다.
병렬 처리 코드 예제
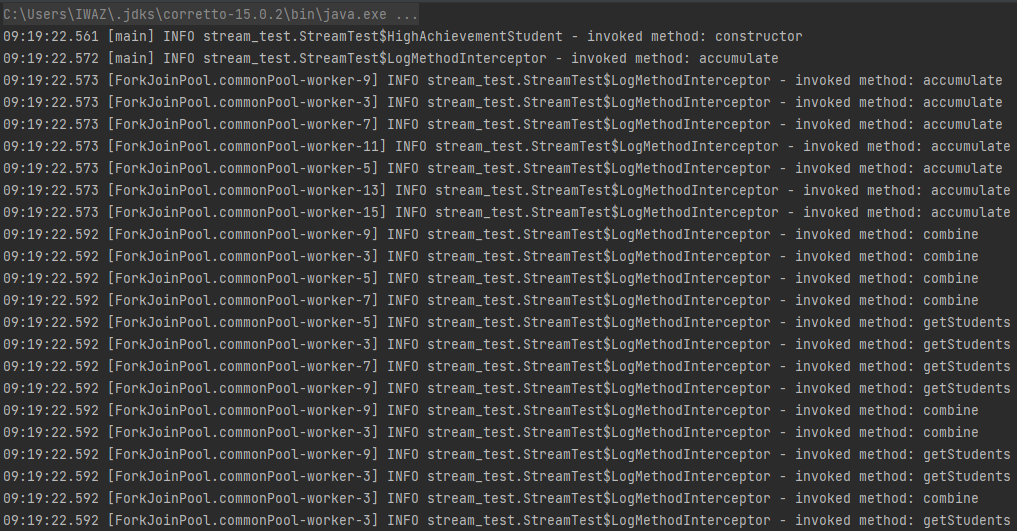
코드에 단순히 .stream() 부분을 .parallelStream()으로 바꾸어주었다. 기존에는 main 스레드에서만 진행되던 작업이 ForkJoinPool을 이용해 처리되는 것을 볼 수 있다. combiner도 잘 호출되고 있다.
스트림 병렬 처리 성능 주의사항
병렬처리가 항상 순차처리보다 빠르진 않다.
요소의 수와 요소당 처리시간
요소의 수가 적고 요소당 처리 시간이 짧으면 순차처리가 오히려 병렬처리보다 빠를 수 있다. 병렬 처리에는 스레드풀 생성과 스레드 생성이라는 오버헤드가 발생한다.
스트림 소스의 종류
ArrayList는 인덱스로 요소를 관리하여 데이터를 쪼개기 쉽지만, HashSet, TreeSet은 요소 분리가 쉽지 않고, LinkedList도 링크를 따라가야 하므로 분리가 쉽지 않다. 요소 분리가 쉽지 않은 자료구조는 상대적으로 병렬처리가 늦다.
코어의 수
싱글 코어 CPU인 경우에는 당연히 순차 처리가 빠르다. 병렬 스트림을 사용할 경우 스레드의 수만 증가하고, 동시성 작업으로 처리되기 때문에 좋지 못한 결과를 낼 수 있다. 코어가 많을수록 병렬 작업 처리 속도는 빨라진다.
