LLM이란?
- 대규모 언어 모델 (Large Language Model)
- 심층 신경망 모델 (Deep Neural Network)
- 여러개의 층으로 복잡한 관계까지 학습 가능한 모델
- 얕은 모델은 단순 규칙만 학습 가능
- 입력 -> 특징 추출 -> 출력으로 변환하는 구조
- 여러개의 층으로 복잡한 관계까지 학습 가능한 모델
- 대용량의 텍스트 데이터로 훈련
- 인터넷에 공개된 전체 텍스트의 상당 부분
- 사람의 텍스트를
- 이해
- 생성
- 응답
대규모란 어떤 뜻인가?
- 모델 파라미터의 크기와 대량의 훈련 데이터셋을 의미
- 수백 또는 수천억 개의 파라미터
- 모델 파라미터는 시퀀스의 다음 단어를 예측하도록 훈련하는 과정에서 조정되는 신경망의 가중치 (weight)
학습에서 머신러닝과 딥러닝의 차이
- 머신러닝: 사람이 직접 특성을 추출
- 딥러닝: 모델이 자동으로 학습
머신러닝에서는 사람이 직접 특성을 설계(feature engineering) 해야 하고, 딥러닝에서는 신경망이 데이터로부터 유용한 특성을 자동으로 학습(representation learning) 한다.
오해하면 안되는 부분
- 모델이 특성을 자동으로 학습하긴 하지만, 사람이 여전히 모델 구조, 데이터 전처리, 하이퍼파라미터를 설계해야 함
- 즉, "수동 특성(feature engineering)"은 줄었지만 "모델 설계(model engineering)"는 여전히 인간의 몫
LLM 애플리케이션의 쓸모
- 텍스트 분석과 생성에 관련된 거의 모든 작업을 자동화하는데 매우 유용함
LLM 구축 단계
- 사전 훈련과 미세 튜닝으로 구성됨
- 사전 훈련: LLM 모델을 대규모 데이터셋에서 훈련시켜 언어에 대한 폭넓은 이해를 쌓는 초기 단계
- 미세 튜닝: 사전 훈련된 파운데이션 모델을 개선
1단계: 사전 훈련
- 원시 텍스트인 대규모 텍스트 말뭉치(corpus)에서 훈련
- '원시'란 데이터에 레이블 정보가 없는 일반적인 텍스트
- ML의 지도 학습에선 정답(레이블)이 필요하지만, LLM은 입력 데이터로부터 레이블을 생성하는 자기 지도 학습(self-supervised learning)을 사용
- 첫번째 훈련 단계를 사전 훈련(pretraining) 이라 부름
- 이렇게 훈련된 모델을 베이스 모델(base model) 혹은 파운데이션 모델(foundation model) 이라 부름
사전 훈련만 끝나도, 입력 데이터를 기반으로 다양한 작업을 해결 가능.
ex. 텍스트 훈련, 제로-샷, 퓨-샷
2단계: 미세 튜닝
- 이번엔 원시 텍스트가 아닌 레이블이 있는 데이터를 이용해 LLM을 추가적으로 훈련 가능
- 이것을 미세 튜닝이라고 함
- 인기 있는 미세 튜닝의 종류
- 지시 미세 튜닝 (instruction fine-tuning)
- 지시와 정답 쌍 (ex. 번역하기 위한 쿼리와 번역된 텍스트)
- 분류 미세 튜닝 (classification fine-tuning)
- ex. 스팸인 메일 / 스팸이 아닌 메일
- 지시 미세 튜닝 (instruction fine-tuning)
트랜스포머 구조
- 대부분의 최신 LLM은 Attention is All You Need 에서 소개된 심층 신경망 구조인 트랜스포머(transformer)를 기반으로 함
- 트랜스포머는 크게 인코더(encoder)와 디코더(decoder)로 구성됨
- 인코더(encoder): 입력 문장의 각 토큰을 임베딩(숫자 벡터)로 바꾼 뒤, 위치 정보를 더해서 여러 층(layer)을 통과시키며 문장 전체의 표현을 만듦
- 디코더(decoder): 이전에 생성한 단어들을 입력으로 받아 다음 단어를 하나씩 예측. 단, 미래 단어는 못보게 막아둠
셀프 어텐션이란?
- 인코더와 디코더는 셀프 어텐션(Self-Attention) 매커니즘으로 연결된 많은 층으로 구성되어 있음
- 모델이 시퀀스에 있는 서로 다른 단어 또는 토큰(token)에 상대적인 가중치를 부여할 수 있음
- 모델이 입력데이터에서 긴 범위에 걸친 의존성과 맥락관계를 포착하여 일관성 있고 맥락에 맞는 출력을 생성할 수 있음
셀프 어텐션의 동작 방식
- 각 단어가 모든 단어를 훑어보고, 지금은 이 단어에 얼마나 주목해야 하는지 가중치(중요도)를 계산
- 가중치로 다른 단어들의 정보를 모아서(가중 합) 그 단어의 새로운 표현을 만듦
- 장점
- 모든 단어가 서로 직접 소통하므로, 멀리 떨어진 관계(장거리 의존성)을 바로 포착 가능
- 계산을 병렬화 할 수 있어서 GPU 에서 훨씬 빠르게 학습 가능
- Multi-Head Attention 이란?
- 여러명의 팀원이 다양한 관점으로 동시에 문장을 검토하는 것
- 문법, 의미, 관계 같은 다양한 관점으로 바라보고 그 결과를 모아서 더 풍부한 표현을 만듦
BERT와 GPT
- BERT: 인코더 모듈을 기반으로 함
- 주어진 문장에서 마스킹 되거나 가려진 단어를 예측하는 마스킹 단어 예측에 특화
- 감성 분석과 문서 분류를 포함해 텍스트 분류 작업에 강점을 가짐
- GPT: 디코더 모듈을 기반으로 함
- 텍스트 생성 특화
트랜스포머가 나온 맥락
- 기존 RNN의 한계 극복
- 병럴 처리: 한 문장을 순차적으로 훑지 않고, 한번에 모든 단어의 관계를 계산하므로 학습 속도가 빠름
- 장거리 의존성 처리: 멀리 있는 단어끼리도 직접 연결되므로 복잡한 문장 구조를 더 잘 포착
- 확장성 문제: 문장이 매우 길어지면 모든 단어 쌍을 계산하므로 비용이 커지는 단점(그러나 이후 연구들이 이를 개선)
GPT 구조
- Improving Language Understanding by Generative Pre-Training 에서 소개
- Training language models to follow instructiosn with human feedback
자기지도 학습
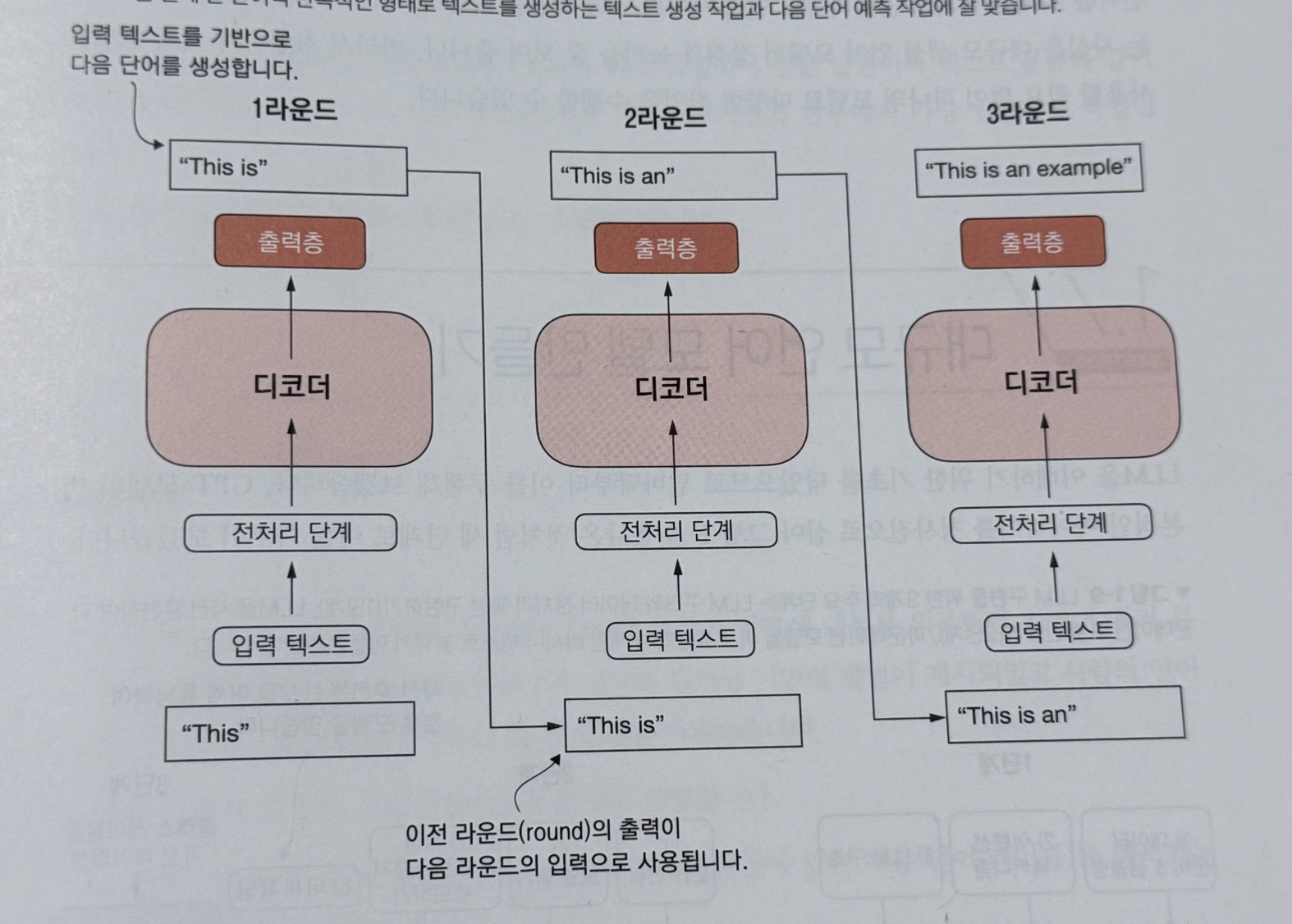
- 방대한 텍스트 데이터에서 다음 단어를 모델이 예측해야 할 레이블로 사용 가능 (Autoregressive model)
- 이전 출력을 입력으로 사용해 미래를 예측함
- 이전 시퀀스를 기반으로 다음 단어를 선택하는 식으로 출력 텍스트의 일관성을 향상
GPT 구현 단계


풀스택 웹개발자로 일하고 있는 Jake Seo입니다. 주로 Jake Seo라는 닉네임을 많이 씁니다. 프론트엔드: Javascript, React 백엔드: Spring Framework에 관심이 있습니다.