DB Server 인덱싱에 대한 간략한 설명
장점
- 데이터 검색을 빠르게 만들기 위함.
- 데이터의 중복 방지. (Primary key, Unique)
- LOCK을 최소화. (동시성 증대)
단점
- 물리적인 공간 차지. (테이블처럼 데이터를 가짐)
- 인덱스에 대한 유지/관리 부담
- 데이터가 적다면 유지/관리 부담이 더 클 수 있음
인덱싱에 따른 테이블 구조의 3가지 형태 (힙, 클러스터형 인덱스, 논클러스터형 인덱스)
1. 힙(HEAP): 인덱싱되지 않은 테이블
특성
- 인덱싱되지 않은 상태
- 정렬의 기준이 없음
- 데이터 페이지 내의 행들 간에 순서가 없음
- 클러스터형 인덱스가 없는 테이블
장단점
- INSERT에 유리. 순서없이 그냥 페이지 빈 곳에 새 데이터를 추가하기만 하면 됨.
- SELECT에 불리. 원하는 데이터를 찾기 위해서는 모든 데이터를 스캔해보아야 함. (Table Scan)
2. 클러스터형 인덱스
특성
- 인덱스된 컬럼을 기준으로 데이터가 물리적으로 정렬된다.
- 물리적으로 테이블의 row를 정렬하는 것이 필수적이라서 결과적으로는 클러스터된 인덱스는 로우의 모든 컬럼을 포함한다.
- 테이블에서 단 하나의 클러스터드 인덱스만 존재할 수 있고, 모든 로우는 클러스터 인덱스에 명시된 순서대로 정렬된다.
- 이 말은 즉, 데이터를 삽입하거나 업데이트할 때도 클러스터드 인덱스는 순서를 보장한다는 뜻이다. 이러한 프로세스는 애플리케이션 퍼포먼스에 좋은 영향을 미칠 수 있다.
- 클러스터드 인덱스가 없는 테이블에서는 데이터가 위에 설명한대로 정렬되지 않은 힙으로 저장된다. 힙은 정렬된 구조를 갖지 않는다. 테이블의 사이즈가 증가할수록 이러한 구조는 많은 문제를 발생시킬 수 있다.
모든 컬럼을 읽을 필요가 있는 읽기 전용 프로그램을 구성한다면, 클러스터형 인덱스는 좋은 선택이 될 수 있다.
- 클러스터드 인덱스는 트리로 저장된다. 클러스터 인덱스를 설정하면, 실제 데이터는 Leaf Node에 저장된다. 이러한 구성은 인덱스에 대한 look-up이 수행됐을 때 속도를 빠르게 해준다. 결과적으로, 낮은 숫자의 IO 연산이 요구된다.
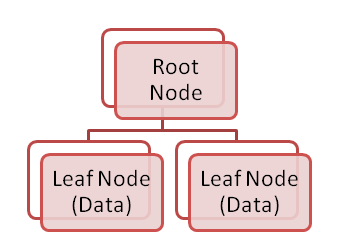
간소화를 위해 위 구조에서 non-leaf intermediate nodes를 뺐다.
- 추가적으로 인덱스는 데이터를 새로운 테이블에 옮기지 않고도 재구성이 가능하다.
- SQL Server는 자동으로 Primary key 제약사항을 클러스터된 인덱스에 생성한다. 이 Primary key 제약사항은 해당 Row를 고유하게 만들기 위함이다.
3. 논클러스터형 인덱스
- B-tree 인덱스라고도 불린다.
- 논클러스터드 인덱스 내부에서 논리적인 방법으로 데이터가 정렬된다. 로우는 논클러스터드 인덱스의 열과 다른 순서로 물리적으로 저장될 수 있다. 따라서 인덱스가 생성되고, 인덱스의 데이터가 인덱스 컬럼에 따라 논리적으로 정렬된다.
- 논클러스터드 인덱스는 실제 데이터의 상단에 생성된다.
- 클러스터드 인덱스와 다르게, 논클러스터드 인덱스의 리프 페이지들이 실제 데이터를 포함하지 않는다. 논클러스터드 인덱스의 리프 페이지는 포인터를 가지고 있다.
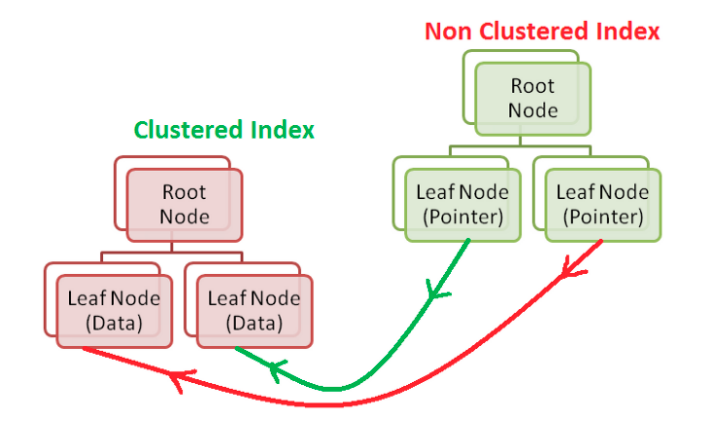
이번에도 마찬가지로 간소화를 위해 non-leaf intermediate nodes를 뺐다.
- 위 포인터들은 클러스터드 인덱스의 리프 노드를 가리킨다. 필요한 열에 대한 주소를 가지고 있다.
포인터들은 책 목차 부분에 있는 페이지 숫자들과 같은 역할을 한다.
- 클러스터드 인덱스의 경우에는 리프 노드가 실제 데이터를 저장하고 있다는 것을 다시 상기해보자.
- 만일, 클러스터드 인덱스가 테이블에 존재하지 않는다면, 논클러스터드 인덱스는 데이터가 저장된 힙 페이지를 포인팅한다. 그리고 힙은 이전에 말했듯 정렬되지 않은 형태로 데이터를 보관한다.
- 우리가 쿼리를 날릴 때, 처음 데이터의 주소를 얻기 위해 논클러스터드 인덱스가 검색이 되고, 이후에 클러스터드 인덱스에서 데이터를 얻기 위해 룩업이 수행된다. 이런 이유로 논클러스터드 인덱스가 일반적으로는 클러스터드 인덱스보다 느리다.
- 테이블에는 여러 개의 논클러스터드 인덱스가 있을 수 있다.
테이블의 로우가 물리적으로 클러스터드 인덱스의 순서에 의해 정렬되지만, 논클러스터드 인덱스는 인덱스에 명시된 순서대로 컬럼의 고유한 값을 포함한다. 그리고 실제 데이터를 가리키는 포인터를 갖는다. 논 클러스터드 인덱스는 테이블의 딕셔너리로 생각해볼 수 있다.
인덱스의 사용법
클러스터드 인덱스를 사용해야 할 때는 언제인가?
먼저, 성능 보틀넥이 어디서 발생하는지 이해하기 위해 쿼리를 실행하고 실행 계획을 분석하는 것이 항상 기본이 되어야 한다. 하지만, 다음과 같은 경우에는 클러스터드 인덱스를 만들어보는 것도 현명한 선택이다.
- 특정한 컬럼을 기준으로 JOIN 이나 WHERE 문을 많이 이용할 때 해당 컬럼에 클러스터드 인덱스를 사용하면 좋다.
- 단, 업데이트가 자주 일어나는 컬럼이 아니어야 한다.
- 특정한 컬럼에 대해 언제나 정렬된 데이터가 필요로 될 때, 해당 컬럼에 대해 매번 ORDER BY 구문을 이용하게 될 때 해당 컬럼에 클러스터드 인덱스를 사용하면 좋다.
- 이 인덱싱을 통해 테이블이 매번 스캔될 필요가 없게 만들 수 있다.
- 애플리케이션이 테이블에서 다량의 데이터를 읽어온다면 클러스터드 인덱스를 통해 많은 성능향상이 가능하다.
- SELECT 쿼리에서 대부분, 혹은 모든 컬럼의 내용을 읽어오는 경우에도 클러스터드 인덱스를 사용하는 것을 고려할 수 있다.
- 단, 최소한의 컬럼을 클러스터형 인덱스 키 컬럼으로 지정하는 것이 중요하다.
논 클러스터드 인덱스를 사용해야 할 때는 언제인가?
먼저, 성능 보틀넥이 어디서 발생하는지 이해하기 위해 쿼리를 실행하고 실행 계획을 분석하는 것이 항상 기본이 되어야 한다. 하지만, 다음과 같은 경우에는 논클러스터드 인덱스를 만들어보는 것도 현명한 선택이다.
- 테이블의 로우를 필터링하기 위해 다수의 쿼리가 요구되고, WHERE 문이나 JOIN 문에서 다른 그룹의 컬럼들이 있을 때, 논클러스터드 인덱스를 사용하면 좋다.
- 지속적으로 특정한 정렬 순서로 데이터를 출력한다면, 논클러스터드 인덱스로 속도 향상 효과를 볼 수 있다.
- 추가적인 정렬이 필요 없어서 메모리상의 이득을 볼 수 있다.
- 실제 데이터의 물리적인 정렬은 발생하지 않는다. 다만, 각 로우에 RID라는 것이 붙어 RID가 데이터를 찾는 것을 도와준다.
- RID 구조: 파일 식별자 + 페이지 번호 + 페이지 내의 로우 번호
- 추가적인 정렬이 필요 없어서 메모리상의 이득을 볼 수 있다.
- 힙과 클러스터드 인덱스에서의 비클러스터드 인덱스의 동작 비교
- HEAP클러스터드구조정렬 없이 단순 적재클러스터드 인덱스 컬럼에 따라 정렬된 상태모든 페이지를 다 읽을 때Table ScanClustered Index Scan논 클러스터드 인덱스 구조RID + 인덱스 Key 컬럼Clustered Index Key + 인덱스 Key 컬럼논 클러스터드 인덱스에서 해결이 되지 않을 때RID LookupKey Lookup
인덱스를 사용하여 데이터 조회가 이루어지면, Index Seek 동작이 발생한다.
- HEAP클러스터드구조정렬 없이 단순 적재클러스터드 인덱스 컬럼에 따라 정렬된 상태모든 페이지를 다 읽을 때Table ScanClustered Index Scan논 클러스터드 인덱스 구조RID + 인덱스 Key 컬럼Clustered Index Key + 인덱스 Key 컬럼논 클러스터드 인덱스에서 해결이 되지 않을 때RID LookupKey Lookup
- 만일, 쿼리에서 특정한 컬럼들이 더 자주 사용된다면, 논 클러스터드 인덱스를 테이블에 걸어둬서 효과를 볼 수 있다.
- 이 방식은 Cover Non Clustered Index 라고 불린다. (참고링크)
- 특정한 기준(criteria)에 맞춘 열들만 인덱스를 걸고 싶다면, 논 클러스터드 인덱스 내부에 WHERE 조건을 추가할 수 있다.
- 이 방식은 Filter Non Clustered Index 라고 불린다.
- SELECT 할 때, 논 클러스터드 인덱스 내부에서 리프 노드로 필요로 되는 컬럼을 INCLUDE 할 수 있다. 이러한 작업은 검색속도를 빠르게 만들어 준다.
- 논클러스터드 인덱스 또한 선별된 컬럼에만 걸어야 효과를 볼 수 있다.
- 조회하려는 모든 컬럼이 인덱스에 포함되어 있을 때는 데이터 페이지까지 내려가지 않고도 모든 데이터 조회가 가능하기 때문에 Included column을 사용하는 것도 고려할만 하다.
- 동일한 데이터가 많은 컬럼에 인덱스를 걸면, 인덱스를 걸지 않는 것보다 느려질 수도 있다.
인덱스 생성법
클러스터드 인덱스 생성 방법
2가지 방법이 있다.
- Primary Key를 만든다.
- 혹은 create index statement를 이용한다.
-- Via primary key constraint
ALTER TABLE FinTechExplained.Trade ADD CONSTRAINT PK_Trade_TradeId
PRIMARY KEY CLUSTERED (TradeId ASC, TradeType ASC);
-- using create index statement
CREATE CLUSTERED INDEX IX_Trade_TradeId ON FinTechExplained.Trade(TradeId ASC, TradeType ASC);논 클러스터드 인덱스 생성 방법
2가지 방법이 있다.
- NonClustered 키워드를 사용하는 방식
- 혹은 NonClustered 키워드를 사용하지 않는 방식
-- By using the non-clustered index
CREATE NONCLUSTERED INDEX IX_Trade_CreatedAtCreatedBy ON FinTechExplained.Trade(CreatedAt ASC,CreatedBy ASC);
CREATE INDEX IX_Trade_CreatedAtCreatedBy ON FinTechExplained.Trade (CreatedAt ASC,CreatedBy ASC);인덱스 생성 이슈들
가끔은 인덱스를 만들어서 성능에 나쁜 영향이 미치기도 한다.
- 인덱스는 어찌됐건, 디스크 공간을 차지하고 SQL 프로세스 중 memory footprint에 영향을 줄 수 있다. 클러스터드 인덱스는 논클러스터드 인덱스만큼 많은 공간을 차지하지는 않는다. 왜냐하면 논 클러스터드 인덱스는 디스크의 분리된 공간에 저장되기 때문이다.
- 클러스터드 인덱스는 많은 양의 READ 를 수행한다면, 유용하다. 하지만 인서트 시에는 데이터가 섞이고 다시 정렬되는 작업이 필요해진다. 그래서 빠른 INSERT가 필요한 테이블에는 적합하지 않다. 빠른 INSERT만을 원한다면 사실 인덱스를 다 지워버리는 것이 맞다.
- 클러스터드 인덱스의 컬럼들이 아닌 다른 컬럼 집합에 대해 ORDER BY 를 수행한다면, 클러스터드 인덱스는 아무런 도움이 되지 않는다.
- 논클러스터드 인덱스는 주의깊게 설계되어야 한다. 만일 컬럼의 하위집합만 추가한다면, 인덱스는 모든 컬럼을 추가했을 때보다 유용하지 않을 수 있다. 컬럼을 많이 추가할수록, 인덱스가 커지고, 인덱스가 커지면 디스크에서 차지하는 크기도 늘어난다. 한 컬럼을 포함하는 논클러스터드 인덱스를 2개 추가했다면, 해당 컬럼의 고유한 값을 복사하게 될 것이다. 이러한 작업이 이루어지기 때문에 디스크에서 더 많은 공간을 소비하게 된다.
- 많은 인덱스는 성능을 해칠 수 있다. 이를테면 2개의 논클러스터드 인덱스를 생성했다고 가정해보자. 첫번째 논클러스터드 인덱스가 컬럼 A와 B에 붙어있고, 두번째 논클러스터드 인덱스가 B와 C와 D에 붙어있다. 이 상태에서 만일 컬럼 A, C, D를 조회하면, SQL은 필요한 포인터를 찾기 위해 두개의 인덱스를 사용하고 테이블에서 그 데이터를 찾게 된다. 이러한 일은 쿼리 성능에 매우 안 좋은 영향을 준다.
- 만일, bulk import를 할 필요가 있다면, 인덱스가 성능에 영향을 줄 수 있으므로 인덱스를 만들지 않는 것이 좋다.

풀스택 웹개발자로 일하고 있는 Jake Seo입니다. 주로 Jake Seo라는 닉네임을 많이 씁니다. 프론트엔드: Javascript, React 백엔드: Spring Framework에 관심이 있습니다.