Prologue
나는 회사에서 웹 개발자로 일하고 있고 웹개발을 주력으로 하고 싶지만, 인원수가 15명 밖에 안되는 작은 회사에서 근무하기 때문에 가끔은 하기 싫은 일도 해야 한다. 우리 회사는 인공지능과 빅데이터를 전문으로 하는 회사이기 때문에, 당연히 인공지능과 빅데이터 일이 많다. 이번에 문서 유사도 측정기를 구현해보라는 주문을 받아서 간단한 문서 유사도 측정기를 만드는 시행착오를 기록해보려 한다.
구현 설계하기
이전 #1에서는 어떤 방식으로 유사도를 구할 수 있는지 알아봤습니다. 유클리드 거리, 자카드 거리, 코사인 유사도 등의 방식이 있었으며 가장 대중적으로 쓰이는 방식은 코사인 유사도 방식이라고 합니다.
제가 생각한 유사도 구현 방식은 다음과 같습니다.
구현할 것들...
-
단어에 의미 벡터를 부여하기 위한 fast-text 임베딩 모델을 구현한다.
-
코사인 유사도 함수를 구현한다. (이 부분은 사실 gensim 라이브러리에서 지원하기 때문에 따로 구현할 필요가 없습니다.)
-
문장에서 중요한 단어를 추출해낼 TF-IDF 함수를 구현한다. (이것도 사실 sklearn에 구현되어 있지만, 저는 직접 구현해보았습니다.)
설계
- 사용자가 문서를 삽입하면 TF-IDF를 이용하여 중요한 단어들을 추출해냅니다.
- 추출된 주요 단어들을 이용하여 코사인 유사도를 계산합니다.
- 계산된 유사도는 가공 과정을 '잘'거쳐 사용자에게 쉽게 표기됩니다.
결과
특허 사이트에서 무작위로 '효모' 관련 특허 2개와 '배터리' 관련 특허 2개를 가져왔습니다. 총 4개의 문서로 유사도를 구해본 결과에 대해 설명드리겠습니다.
주요 단어 추출
먼저, 위의 설계와 같이 TF-IDF로 주요한 단어들을 추출해냅니다. 예제 결과는 다음과 같습니다.
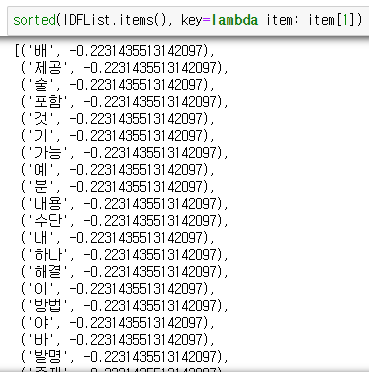
위의 결과를 보면, TF-IDF 알고리즘으로 판단하기에, 특허 문서에서 대표적으로 중요하지 않다고 생각되는 단어들이 나옵니다.
눈에 띄는 단어 몇개는 '발명', '방법', '포함', '제공' 이러한 단어를 고려하는 것은 문서 유사도를 측정하는데에 아무런 도움이 되지 않을 것입니다.
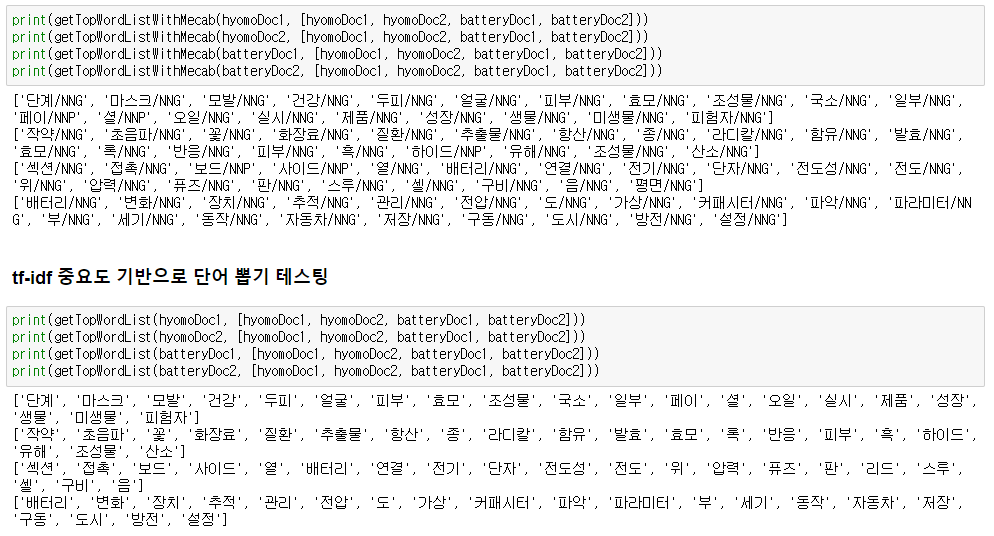
예제 문서에서 주요한 단어를 뽑아냈더니 결과는 위와 같았습니다. 배터리와 효모에 관한 문서였는데 '배터리', '효모'는 TF-IDF 알고리즘에 의해 중요한 단어로 뽑힌 것이 신기하네요.
문서 유사도 결과
저는 2가지 fast-text model을 이용하여 테스트해봤습니다.
하나는 형태소적 의미까지 학습한 fast-text model이고, 하나는 형태소까지는 고려하지 않은 모델입니다.
- 형태소는 고려하지 않은 모델의 결과는 다음과 같습니다.
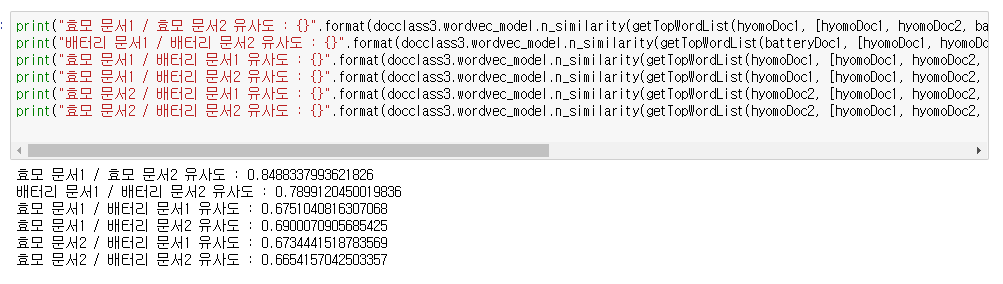
효모 문서 1과 효모 문서 2의 유사도는 둘 다 효모에 대한 문서기 때문에 약 85%정도가 나왔습니다.
그리고 배터리 문서1과 배터리 문서2의 경우에도 똑같이 배터리에 대한 문서기 때문에 문서 유사도가 79%정도 나왔습니다.
반면, 효모 문서와 배터리 문서를 비교했을 때는 최대 69%의 유사도를 보이며, 같은 분야 문서의 유사도를 비교한 결과와는 확연히 차이가 납니다.
참고로 위의 예제는 단지 테스트용으로 매우 짧은 문서만 학습시키고 매우 짧은 문서 테스트용으로 넣었기 때문에, 조금 더 비정확할 수 있습니다. 아직 개선의 여지가 많은 모델입니다.
- 형태소까지 고려한 모델의 결과는 다음과 같습니다.
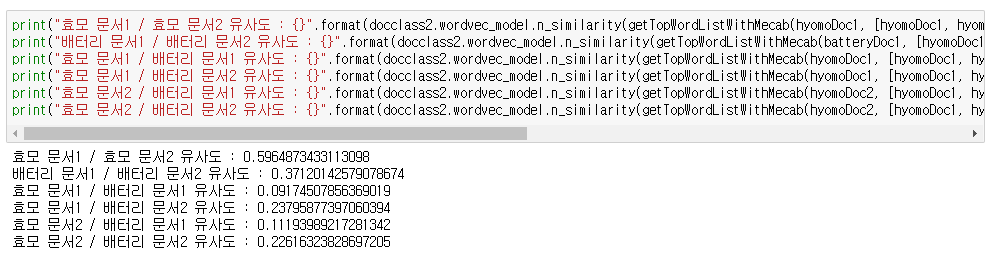
형태소까지 고려한 모델이 문서의 유사도를 더욱 까탈스럽게 판별합니다.
위의 두 문서는 같은 분야의 문서임에도 유사도가 약 60%, 37%정도 나왔습니다.
그리고 다른 분야의 문서의 경우에는 9%, 23%, 11%, 23% 정도가 나왔습니다.
개선 가능한 고려사항들
-
특허 문서들의 유사도를 구할 것이므로, 특허 문서를 많이 학습하여 TF-IDF 계산에 이용되는 IDF 값을 크게 개선할 수 있습니다. 특허 문서에서 나오는 단어의 vocab을 만듭니다. 이 vocab은 나중에 TF-IDF를 이용하여 주요 단어를 산출할 때 이용됩니다. vocab에는 각 단어가 몇 개의 문서들에서 등장했는지를 기록합니다. 모든 문서에서 등장한 단어는 중요하지 않을 확률이 높다는 것을 항상 염두해둡니다.
-
fast-text 임베딩 모델을 학습시키는데도 역시 특허 문서들을 학습시킵니다. 그래서 특허 문서에서 각 단어의 의미벡터들을 잘 설정시켜줍니다. 문서마다 단어가 의미하는 바가 다를 수 있으므로 특정 분야의 문서를 잘 학습하는 것은 매우 중요합니다.
-
형태소 분석기는 mecab을 사용합니다. okt는 상대적으로 성능이 떨어지는 결과를 보였습니다. 그리고 형태소 분석기에 사용되는 사전은 nia에서 공개한 사전을 이용합니다. (사실 저는 귀찮아서 사전 삽입은 하지 않았습니다.)
-
경계점 설정은 구현된 문서 유사도 측정 모델을 최대한 많이 돌려보고 결정합니다. 이를테면 배터리 관련 특허 문서들을 전부 모아놓고 문서 유사도를 측정해봤을 때 평균적으로 80%의 유사도가 나오고 배터리와 관련 없는 특허 문서들을 전부 모아놓고 문서 유사도를 측정했을 때 50%의 유사도가 나온다면, 최소한 50과 80의 사이 약 65%정도의 유사도가 경계점이 될 수 있습니다. 그 정도의 유사도는 보여야 비슷한 문서라고 판단할 수 있을 것입니다. 이 수치는 계속 테스트하며 개선시켜야 될 것 같습니다.
문서 유사도를 구하는 포스팅은 여기까지 하겠습니다.
