밑바닥부터 시작하는 딥러닝 #3-1 신경망 학습
Prologue
나는 여전히 웹개발자이지만, 회사에 부쩍 딥러닝 과제가 많아져서 딥러닝 공부가 많이 필요하게 됐다. 밑바닥부터 시작하는 딥러닝 책이 좋다고 해서 천천히 하나하나 공부해보려 한다.
학습이란?
딥러닝에서 학습이란 가중치 매개변수 의 최적값을 찾아내는 것을 말합니다. 가중치 매개변수 의 최적값을 찾기 위해서는 손실함수가 최소가 되는 값 을 찾아내야 합니다.
우리는 MNIST 손글씨 분류에 필요한 가중치 매개변수 학습 과정을 직접 구현해볼 것입니다.
데이터가 주도하는 학습
딥러닝의 특징은 수 많은 데이터에서 특징(feature) 을 추출하고 특징의 패턴 을 학습합니다.
기존 프로그래밍 방식은 이 패턴을 인간이 파악해서 알고리즘을 만들었습니다. 반면 딥러닝은 사람이 정의한 특징 을 기준으로 패턴을 학습하고 규칙을 찾아냅니다.
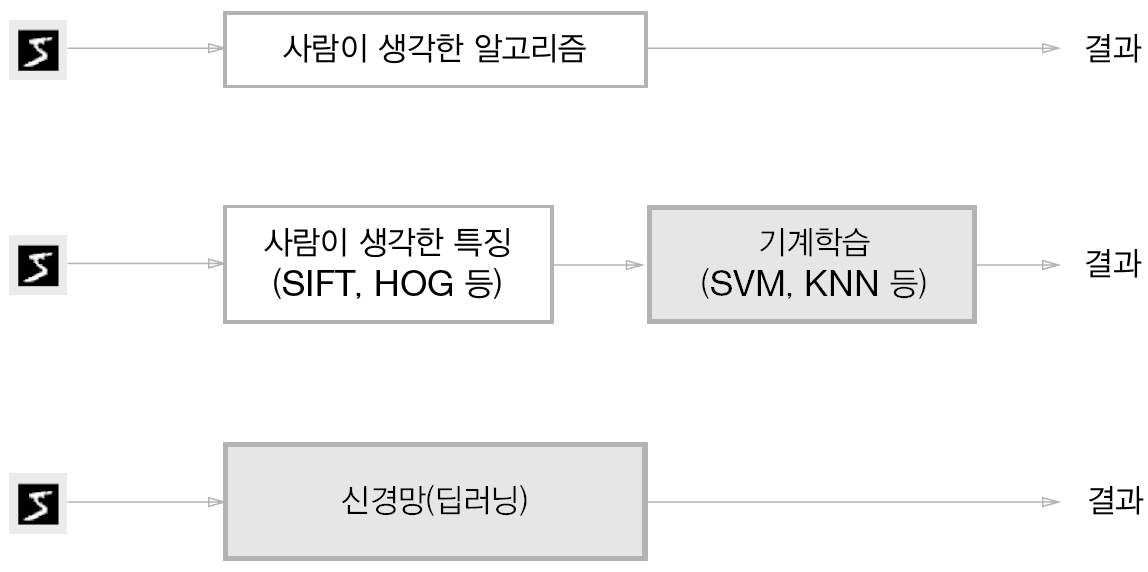
딥러닝을 종단간(end-to-end) 기계학습이라고도 하는데, 이는 '입력과 출력을 사람의 개입 없이 얻는다' 는 뜻을 담고 있습니다.
손실함수
손실함수는 일반적으로 두가지를 사용합니다.
- 평균 제곱 오차(mean squared error, MSE)
- 교차 엔트로피 오차(cross entropy error, CEE)
평균 제곱 오차 (mean squared error, MSE)
수식
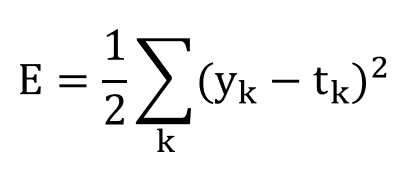
y는 각각의 숫자가 될 확률이며, t는 원-핫 인코딩된 정답 레이블입니다.
- y-t에 제곱을 해주는 이유는 y-t의 결과값이 음수가 되는 것을 방지하기 위해서입니다.
- 1/2을 곱해주는 것은 y-t의 최대 결과값이 2이기 때문에 1로 정규화하기 위함입니다.
코드
MNIST 손글씨 분류 작업을 위한 학습을 할 때 마지막 활성화 함수로 소프트맥스 함수 를 사용했다고 가정해봅시다.
이를테면
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]위와 같은 데이터가 들어갈 수 있습니다.
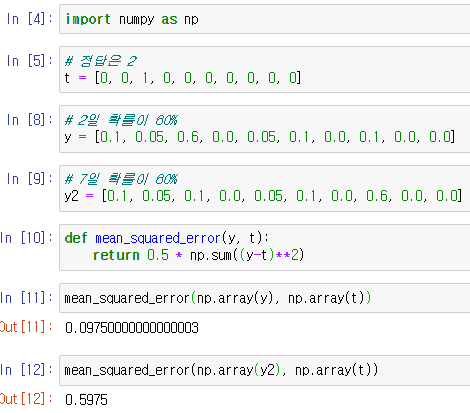
위는 평균 제곱 오차를 코드로 구현한 것입니다.
첫번째 결과가 0.0975이고 두번째 결과가 0.5975이므로, 첫번째 결과가 오차가 더 적습니다. 오차가 적은 것은 첫번째 결과가 더 정확하다는 것을 의미합니다.
교차 엔트로피 오차 (cross entropy error, CEE)
수식
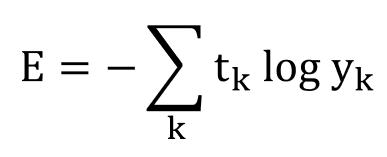
로그의 밑은 자연상수 e 입니다.수식에서 t는 역시 원핫 인코딩된 레이블이고, y는 각 정답 확률입니다. 원핫 인코딩 특성상 t는 정답에만 1을 표기하기 때문에, 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정합니다. 밑이 e인 로그에 1 이하의 값을 넣으면 결과 값이 마이너스가 나오기 때문에 맨 앞에 마이너스를 붙여 양수로 변환시켜줍니다.
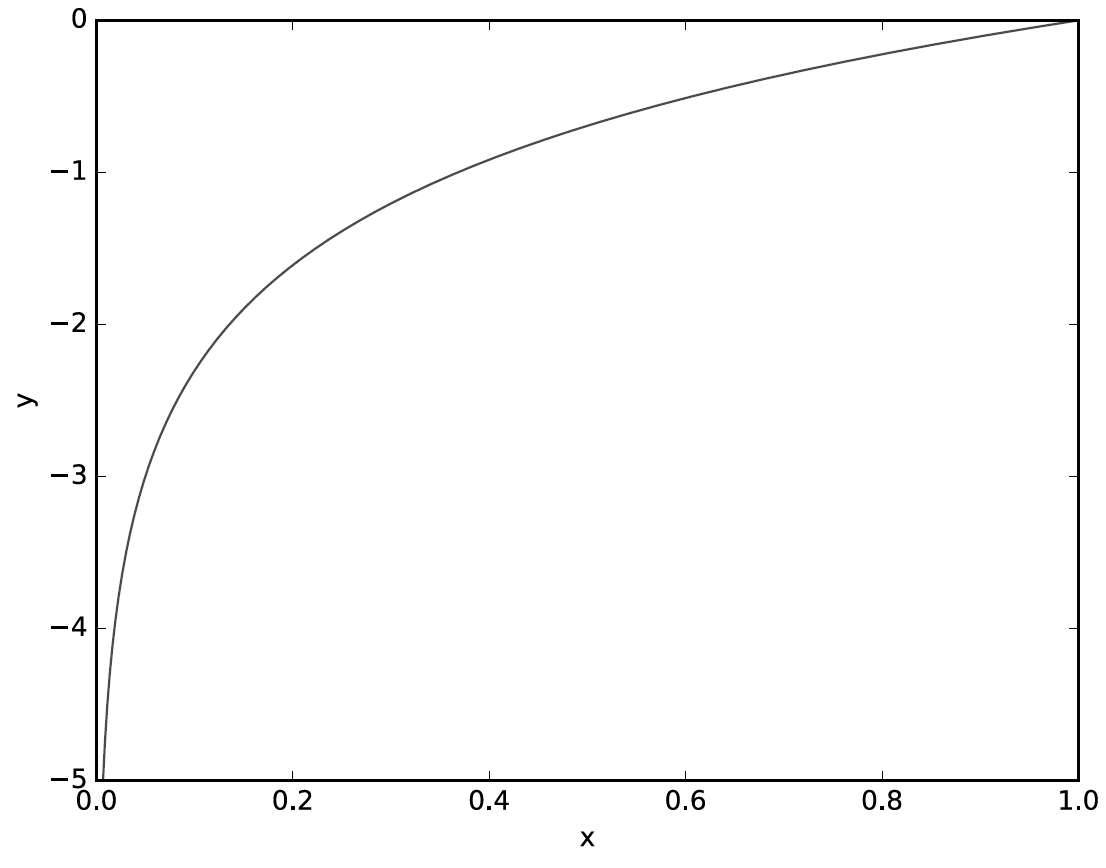
위는 자연상수 e의 그래프입니다.
1(정답)에 가까울수록 오차가 0이되며, 오답에 가까울수록 -5쪽으로 수렴하게 됩니다.
코드
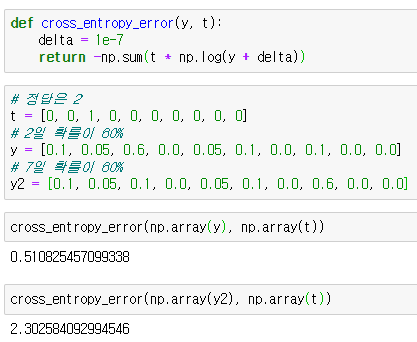
위의 수식을 그대로 함수로 구현했는데, y에 delta를 더한다는 점이 조금 다릅니다. delta를 더하는 이유는 log에 0이 들어갈 경우 -inf가 나오기 때문에, -inf가 나오지 않도록, 아주 작은 숫자를 더해줍니다.
밑의 결과를 보면 역시 첫번째 값보다 두번째 값이 더 크기 때문에 오차가 더욱 크다고 볼 수 있습니다. MSE의 결과와 동일합니다.
정리
- 딥러닝에서는 학습 이란 과정이 필요합니다.
- 학습 은 신경망에 들어가는 각 가중치의 최적의 값을 구하는 행위입니다.
- 최적의 가중치를 찾기 위해서는 손실 함수 값이 최저가 되는 지점 을 찾아야 합니다.
- 대표적 손실함수로는 평균 제곱 오차(MSE) 와 크로스 엔트로피 오차(CEE) 가 있습니다.
- 평균제곱오차 함수는 정답과 오답의 모든 확률을 고려하고 크로스 엔트로피 오차 방식은 정답의 확률만을 고려합니다.


안녕하세요. 글을 보다가 궁금한 점이 있어 댓글 달았습니다!
혹시 MSE 수식이 제가 알기로 2로 나누는게 아닌 N으로 나누는걸로 알고 있는데(오차제곱들의 평균이므로)
현재 '밑바닥부터 시작하는 딥러닝' 책을 보고 있는데 112pg에 N이 아닌 2로 나누어서
잘못된 것 같아 인터넷을 찾아보는데도 2로 적힌 곳이 있어서 여쭈어봅니다.
혹시 실례가 안된다면 설명좀 해주실 수 있으실까요?
그리고 y - t의 값의 최대가 2라서 정규화하기 위해 2로 나누셨다고 하셨는데
최대 차이가 (1-0)^2 = 1이기 때문에 최대도 1로 알고 있습니다.