4주차, 이번에는 무엇을 했는가?
클린 아키텍처라는 것을 처음 배웠다.
클린 코드, 클린 xxx 등 많은 클린 시리즈를 배워봤는데, 이번엔 클린 아키텍처라는 것을 처음 봤다. 스프링을 배우면서 자연스레 단순히 @Controller 는 웹 연결, @Service 에는 비즈니스 로직, @Repository 는 디비 연결 관련 로직을 넣는다고만 막연히 알고 있었는데, 이번 기회에 조금 더 정리된 아키텍처 개념을 알게 됐다.
아키텍처를 통해 계층을 나누게 되면 결국에 테스트하기 쉬운 형태가 되며, 외부 모듈이 바뀌었을 때 유연하게 대응할 수 있는 애플리케이션이 된다.
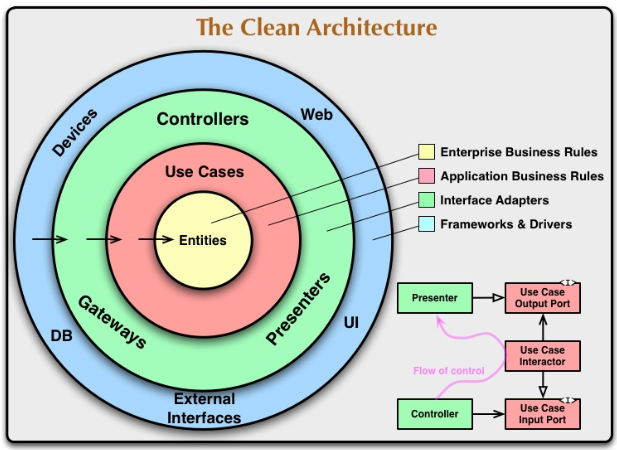
핵심 규칙
- 핵심은 관심사의 분리라는 목적을 달성하는 것이다.
- 관심사를 분리하며, 테스트가 용이한 구조를 만들어낸다.
- UI에 독립적이어야 한다.
- 외부 환경에 독립적이어야 한다.
- DB 등이 바뀌어도 상관없어야 한다.
- 바깥쪽 써클은 안쪽 써클에 대해 알 수 있지만, 안쪽 써클은 바깥쪽 써클에 대해 몰라야 한다.
각 계층에 대한 간략한 설명
엔티티: 비즈니스 규칙을 캡슐화한 것이다. 다른 계층에 어떤 변화가 일어나더라도 웬만해선 영향을 받지 않는다.유즈 케이스: 스프링에서Service에 대치되는 것이다. 비즈니스 규칙을 지닌다.인터페이스 어댑터: 스프링에서Controller,Repository등에 해당하는 것이다. 유즈 케이스와 Web, UI, DB, Device 등의 영역을 연결해준다.프레임워크와 드라이버: DB 구현체와 같은 가장 구체적인 것들이 있다. 안쪽 써클들과 통신할 수 있는 glue code 를 많이 작성한다.
계층간의 경계를 넘을 때는?
- 의존성 역전 원칙을 이용한다.
- 인터페이스인
Use Case Input Port와Use Case Output Port를 이용해 서로의 구체적인 타입을 몰라도 커뮤니케이션이 가능하다.
최종 목적은?
- 독립적으로 동작하는 테스트 가능한 시스템을 만들자.
- 프레임워크와 드라이버가 바뀌어도 정상동작할 수 있는 유연한 시스템을 만들자.

참고자료
직접 번역한 것
클린 아키텍처란? - (직접 번역한 Robert C. Martin 의 게시글)
스프링 데이터 JPA 를 사용해서 API 를 구성해봤다.
스프링 데이터 JPA 는 JPA 를 기반으로 한 데이터 엑세스 계층을 쉽게 구현할 수 있도록 도와주는 도구이다. 기본적인 CRUD 는 interface 를 통해 실제 구현 코드작성 없이도 자동 구현이 되게 만들어준다. 또한 Pagination, Auditing 등 DB 부가기능도 DB 에 구애받지 않고 쉽게 구현할 수 있도록 도와준다.
JPA 를 이용한 서비스계층 클래스에
@Transactional애노테이션을 거는 것만으로, 메서드 호출이 종료된 후 엔티티 수정 시 자동 반영이 되는 등의 기능도 있었다.
자바 진영의 대표적인 ORM 인 JPA 를 사용해보았다.
Object–relational mapping (ORM, O/RM, and O/R mapping tool) in computer science is a programming technique for converting data between type systems using object-oriented programming languages. This creates, in effect, a "virtual object database" that can be used from within the programming language. There are both free and commercial packages available that perform object–relational mapping, although some programmers opt to construct their own ORM tools.
ORM 이란, Object Relational Mapping 으로 관계형 DB 등에 저장된 데이터를 객체지향 프로그래밍 언어로 매핑할 수 있도록 도와준다.
관계형 DB 와 자바 객체와의 괴리에 대해 공부해보았다.
불일치가 발생하는 이유 1: 식별 기준
- 자바 객체는 식별을 '메모리 주소'를 기준으로 한다.
- 데이터베이스의 데이터는 식벽을 '식별자'를 기준으로 한다.
- 자바 객체의 데이터를 데이터베이스에 저장하는 순간 객체가 사용하던 식별자는 사라진다.
불일치가 발생하는 이유 2: 다수의 데이터를 저장할 때
- 데이터베이스는 최적의 효율을 위해 외래키를 이용한 참조를 이용해 각각 다른 테이블에 저장한다.
- 자바에서는 객체 타입의 컬렉션을 이용해 다수의 데이터를 저장한다.
JPA 는 데이터를 다루는 행위를 컬렉션을 다루는 것처럼 해준다.
Mock 을 이용한 테스트를 이용해 TDD 를 수련했다.
Mock 을 이용한 테스트를 만든다고 해서 사실 내가 작성한 프로그램이 100% 정상적으로 동작하는지에 대해 테스트할 수는 없다. 그러나, 다음과 같은 이점이 있다.
그냥 개발을 엄청 빨리할 수 있게 된다. 설계와 관련된 사항들을 인지하며 진행할 수 있게 된다.
과제 코드리뷰에서 배운 것
서비스 분리
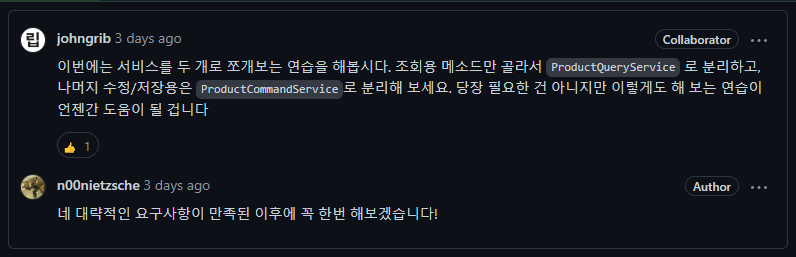
단순히 Service 하나를 보는 것이 아닌 조회용 - QueryService 수정/저장용 - CommandService로 분리해보자는 요청을 받았다.
자세히는 모르지만 마틴 파울러의 CQRS 에서 나오는 내용인 것 같았다. 나중에 더 알아봐야겠다.
DTO 와 관련된 내용을 더 자세히 알아보게 됨
마틴 파울러의 DTO 관련 글을 읽고서 DTO 가 나온 배경과 현재 내가 사용하는 방식에 대해서 인지하게 됐다. 현재 내가 사용하는 방식은 Domain Model 과 Presentation Layer 와의 괴리를 극복하기 위해 연결고리정도로 사용하고 있었다.
원래 DTO는 굳이 도메인 모델을 지키며 데이터를 주고받을 때 네트워크 오버헤드가 많이 발생하여 한 번에 모든 데이터를 주고 모든 데이터를 받기 위해 나왔다고 한다.
어떤 기분을 느꼈는가?
TDD 를 하며 느꼈던 기분
일단 테스트를 만들고 개발한다는 자체가 추후 리팩토링에도 대비가 되며, 간단한 클래스의 의존성 설계도 짚어가며 하나씩 진행할 수 있고, 내가 어떤 기능을 만들지에 대한 목적성도 확실히 가져갈 수 있었다. 그래서 상당한 안정감을 느꼈다.
그런데 한편으로는 불안감을 느꼈다. 과연 이렇게 모든걸 일일이 테스트로 작성하는 것이 옳은가 하는 물음이 들었다. 아직 테스트를 만드는 속도가 느려서 그런지 상당히 시간을 잡아먹고 있다. 아직 많은 수련이 필요할 것 같다.
클린 아키텍처를 살짝 맛보고 느낀 기분
이미 선대의 개발자들은 많은 엔터프라이즈 앱을 구성해보며, 많은 구현 부분이 반복된다는 느낌을 받았을 것이다. 거기서 각자의 책임을 나누어 최대한 깔끔한 그림으로 만든 것이 클린 아키텍처라고 생각한다.
앞으로 책임이 마구잡이로 흩어지고 테스트가 어렵고 모듈화되지 않은 소프트웨어를 생산하는 것은 지양하고 할 수 있는 만큼 상황에 맞게 적절히 책임이 분리된 아키텍처를 가진 소프트웨어를 만들도록 지향해야겠다.
