예외 전환의 의미와 DataAcessException
예외 전환은 말 그대로 예외를 다른 예외로 바꿔서 던져주는 것이다. 이렇게 다른 예외로 바꾸는 목적은 두가지가 있다.
- 체크 예외를 런타임 예외로 포장하여 불필요한
catch/throws를 줄여주는 것 - 로우레벨의 예외를 좀 더 의미있고 추상화된 예외로 바꿔서 던져주는 것
스프링의 JdbcTemplate이 던지는 DataAccessException은 일단은 런타임 예외로 SQLException을 포장해주는 역할을 한다.
- 이로 인해 어차피 대부분 복구가 불가능한
SQLException에 대해 개발자는catch/throws를 할 필요가 없어진다. - 스프링의 JdbcTemplate의
DataAcessException은SQLException에 담긴 다루기 힘든 상세한 예외 정보를 의미있고 일관성 있는 예외로 전환해서 추상화해주려는 용도로 쓰이기도 한다.
JDBC의 한계
JDBC는 자바를 이용해 DB에 접근하는 방법을 추상화된 API 형태로 정의해놓고 각 DB 업체가 JDBC 표준을 따라 만들어진 드라이버를 제공하게 해준다. 내부 구현은 DB마다 다르지만 Connection, Statement, ResultSet 등의 표준 인터페이스를 통해 그 기능을 제공해주기 때문에 자바 개발자들은 표준화된 JDBC의 API로 DB 종류와 상관없이 일관된 방법으로 프로그램을 개발할 수 있다. 인터페이스를 사용하는 객체지향 프로그래밍 방법의 장점을 잘 경험할 수 있는 것이 바로 JDBC이다.
하지만 DB 종류에 상관없이 사용할 수 있는 데이터 엑세스 코드를 작성하는 일은 마냥 쉽지 않다. 현실적으로 두가지 걸림돌이 있다.
비표준 SQL
JDBC 코드에서는 SQL을 문자열 형태로 사용하게 된다. SQL은 어느정도 표준화된 언어이고 몇가지 표준 규약이 있긴 하지만, 대부분의 DB는 편의나 최적화를 위해 표준을 따르지 않는 비표준 문법과 기능도 제공한다. 간단한 예로는 웹화면의 페이징 처리를 위해 가져오는 로우의 시작 위치와 개수를 지정하거나, 쿼리에 조건을 포함시키거나 하는 내용이 있다.
작성된 비표준 SQL은 DAO 코드에 들어가고 해당 DAO는 특정 DB에 대해 종속적인 코드가 된다. 대부분 사용하는 DB를 변경할 일은 없기 때문에, 비표준 SQL을 거리낌없이 사용하는 편이다. 그런데 일단 DB의 변경 가능성을 고려하기 시작하면 SQL은 큰 걸림돌이 된다.
이 문제의 해결책을 생각해보면,
- 호환 가능한 표준 SQL만 사용하는 방법
- DB별로 별도의
DAO를 만들기 - SQL을 외부에 독립시켜서 DB에 따라 변경 가능하게 만들기
먼저 표준 SQL만 사용하는 방법을 살펴보면, 먼저 이전에 언급했던 페이징 쿼리부터도 사용할 수 없게 된다. 결국 나머지 2개 방법밖에 남지 않게 된다.
사실 JPA에서는 위와 같은 문제를
Dialect라는 것을 이용해 밴더별로 비표준 문법을 어느정도 매핑하는 방식으로 해결해놓은 것 같다. 관련 링크
호환성 없는 SQLException의 DB 에러정보
DB마다 SQL만 다른 것이 아니라 에러의 종류와 원인도 제각각인데, JDBC는 다양한 예외를 SQLException이라는 하나의 예외에 담아버린다. 예외가 발생한 원인은 SQLException에 담긴 에러 코드와 SQL 상태정보를 참조해야 알 수 있다. 그런데 이마저도 SQLException.getErrorCode()로 에러 코드를 가져왔을 때, DB 벤더마다 에러코드가 달라서 각각 처리해주어야 한다.
// MySQL에서 중복된 키를 가진 데이터를 입력하려고 시도했을 때
if (e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY) { ...그래서 SQLException은 getErrorCode()이외에 getSQLState()와 같은 메소드로 예외 상황에 대한 상태 정보를 가져올 수 있도록 만들었다. 이 상태 정보는 DB별로 달라지는 에러코드를 대신할 수 있도록, Open Group의 XOPEN SQL 스펙에 정의된 SQL 상태 코드를 따르도록 되어 있다.
DB 통신 장애:
08S01과 같은 식이다. 여기서 앞의 두자리는 클래스 코드 뒤의 세 자리는 서브 클래스 코드로 분류되어 있다. JDBC 4.0에서는 SQL 2003의 관례를 따로도록 정의되어 있다.
그런데 문제는 이 값 자체도 신뢰할 수 없다는 점이다. 어쩔 때는 아예 표준 코드와 상관없는 엉뚱한 값이 들어있기도 하고, 어떤 DB는 클래스 코드까지는 바로 오지만 서비스 클래스 코드는 일체 무시하고 값을 다 0으로 넣는다거나 하는 식이다.
결과적으로 SQL 상태 코드를 믿고 결과를 파악하도록 코드를 작성하는 것은 위험하다. 결국 호환성 없는 에러 코드와 표준을 잘 따르지 않는 상태 코드를 가진 SQLException만으로 DB에 독립적인 유연한 코드를 작성하는 것은 불가능에 가깝다.
DB 에러 코드 매핑을 통한 전환
그렇다면 SQLException이 제공하는 에러코드나 상태코드를 사용하지 않는 다른 해결책은 없을까? 해결 방법은 DB별 에러코드를 참고하여 발생한 예외의 원인이 무엇인지 해석해주는 기능을 만드는 것이다. 키 값이 중복돼서 중복 오류가 발생하는 경우에 MySQL이라면 1062, 오라클이라면 1, DB2라면 -803이라는 에러 코드를 받게 된다.
이런 에러 코드 값을 확인할 수 있다면, 키 중복 때문에 발생하는 SQLException을 DuplicateKeyException이라는 의미가 분명히 드러나는 예외로 전환할 수 있다. DB 종류에 상관없이 동일한 상황에서 일관된 예외를 전달받을 수 있다면 효과적인 대응이 가능하다.
스프링은 DataAcessException이라는 SQLException을 대체할 수 있는 런타임 예외를 정의할 뿐만 아니라, DataAccessException의 서브 클래스로 세분화된 예외 클래스들을 정의하고 있다.
- SQL 문법 때문이라면,
BadSqlGrammerException - DB 커넥션을 가져오지 못했을 때는
DataAcessResourceFailureException - 데이터의 제약조건을 위배했거나 일관성을 지키지 않는 작업을 수행했을 때는
DataIntegrityViolationException- 그 중에서도 중복 키 때문에 발생한 경우는
DuplicatedKeyException을 사용할 수 있다.
- 그 중에서도 중복 키 때문에 발생한 경우는
문제는 DB마다 에러 코드가 제각각이라는 점인데, 스프링은 DB별 에러 코드를 분류해서 스프링이 정의한 예외 클래스와 매핑해놓은 에러 코드 매핑 정보 테이블을 만들어두고 이를 이용한다.
<bean id="Oracle" class="org.springframework.jdbc.support.SQLErrorCodes">
<property name="badSqlGrammarCodes">
<value>900,903,904,917,936,942,17006,6550</value>
</property>
<property name="invalidResultSetAccessCodes">
<value>17003</value>
</property>
<property name="duplicateKeyCodes">
<value>1</value>
</property>
<property name="dataIntegrityViolationCodes">
<value>1400,1722,2291,2292</value>
</property>
<property name="dataAccessResourceFailureCodes">
<value>17002,17447</value>
</property>
<property name="cannotAcquireLockCodes">
<value>54,30006</value>
</property>
<property name="cannotSerializeTransactionCodes">
<value>8177</value>
</property>
<property name="deadlockLoserCodes">
<value>60</value>
</property>
</bean>
sql-error-codes.xml을 파일명으로 검색해보면,spring-jdbc패키지에 들어있는 것을 볼 수 있다.

JdbcTemplate은 SQLException을 단지 런타임 예외인 DataAcessException으로 포장하는 것이 아니라 DB의 에러 코드를 DataAccessException 계층구조의 클래스 중 하나로 매핑해준다. 전환되는 JdbcTemplate에서 던지는 예외는 모두 DataAccessException의 서브 클래스 타입이다. 미리 준비된 매핑 정보를 참고하여 적절한 예외 클래스를 선택하기 때문에, DB가 달라져도 같은 종류의 에러라면 동일한 예외를 받을 수 있는 것이다.
public void add(User user) throws DuplicateKeyException {
this.jdbcTemplate.update("insert into users(id, name, password) values (?, ?, ?)"
, user.getId()
, user.getName()
, user.getPassword()
);
}위와 같이 add() 메소드를 작성하게 되면, JdbcTemplate은 SQLException 대신에 DataAcessException 계층구조의 예외로 포장해주기 때문에, add() 메소드에 예외 포장을 위한 코드가 따로 필요 없다.
또, DB 종류와 상관없이 중복키로 발생되는 예외는 DataAcessException의 서브 클래스인 DuplicateKeyException으로 매핑돼서 던져진다. add() 메소드를 사용하는 쪽에서 중복 키 상황에 대한 대응이 필요한 경우 참고할 수 있도록 위와 같이 DuplicateKeyException을 메소드 선언에 넣어주면 편리하다.
public void add(User user) throws DuplicateUserIdException {
try {
this.jdbcTemplate.update("insert into users(id, name, password) values (?, ?, ?)"
, user.getId()
, user.getName()
, user.getPassword()
);
} catch (DuplicateKeyException e) {
throw new DuplicateUserIdException(e);
}
}JdbcTemplate을 이용하는 이점으로 위와 같이 깔끔하게 더 의미가 명확한 예외로 예외전환도 가능하다. 위는 DB 벤더와 무관하게 동작할 것이다.
DAO 인터페이스와 DataAccessException 계층구조
DataAcessException은 JDBC의 SQLException을 전환하기 위한 용도만은 아니다. JDBC 외에 자바 데이터 액세스 기술에서 발생하는 예외에도 적용된다. JDO나 JPA는 JDBC와 마찬가지로 자바의 표준 퍼시스턴스 기술이지만, JDBC와는 성격과 사용 방법이 크게 다르다. 또 오라클의 TopLink 같은 상용 제품이나 오픈소스인 하이버네이트 같은 표준을 따르긴 하지만 독자적인 프로그래밍 모델을 지원하는 ORM 기술도 있다. JDBC를 기반으로 하고, 성격도 비슷하지만 사용 방법과 API, 발생하는 예외가 다른 iBatis도 있다.
DataAcessException은 의미가 같은 예외라면 데이터 액세스 기술의 종류와 상관없이 일관된 예외가 발생하도록 만들어준다. 데이터 액세스 기술에 독립적인 추상화된 예외를 제공하는 것이다.
스프링은 왜 이렇게
DataAccessException계층 구조를 이용해 기술에 독립적인 예외를 정의하고 사용하게 할까?
DAO 인터페이스와 구현의 분리
DAO를 분리하는 이유부터 생각해보자.
- 가장 중요한 이유는 데이터 엑세스 로직을 담은 코드를 성격이 다른 코드에서 분리해놓기 위해서다. (레이어 분리)
- 분리된 DAO는 전략 패턴을 적용해서 구현 방법을 변경해서 사용할 수 있게 만들기 위해서이기도 하다. (객체지향 원칙)
그래서 DAO를 사용하는 가장 큰 이점도 생각해보자.
DAO가 내부에서 어떤 데이터 액세스 기술을 사용하는지 신경쓰지 않아도 된다는 점이 있다.User와 같이 자바 빈으로 만들어진, 특정 기술에 독립적인 단순한 오브젝트를 주고받으며 데이터 엑세스 기능을 사용하기만 하면 된다는 점도 있다.
위와 같은 이점을 누리려면 DAO가 인터페이스를 사용하며, 구체적 구현 방법을 감추고 DI를 통해 제공되도록 만드는 것이 바람직하다.
public interface UserDao {
public void add(User user); // JdbcTemplate에서 런타임 예외로 감싸준 덕에 throws가 없다.
}위는 UserDao를 인터페이스로 구현해준 것이다. JdbcTemplate에서 SQLException 예외를 런타임 예외로 감싸준 덕에 throws가 없다. 그런데 만일, JdbcTemplate이 런타임 예외로 예외를 감싸주지 않았다면 어떤 일이 발생했을까?
public interface UserDao {
public void add(User user) throws SQLException;
}위와 같이 코드를 작성해야 했을 것이고, 자바에서 사용하는 데이터 접근 API가 바뀌면 인터페이스마저 바꿔주어야 하는 일이 생길 수 있다.
public interface UserDao {
public void add(User user) throws PersistentException; // JPA
public void add(User user) throws HibernateException; // Hibernate
public void add(User user) throws JdoException; // JDO
}위와 같은 불상사가 일어날 수 있다. 가장 단순한 해결 방법은 물론
public interface UserDao {
public void add(User user) throws Exception;
}위와 같은 방법이 있겠지만, 이래서야 이전에 살펴봤듯 무책임한 선언임을 인정하지 않을 수 없다.
JdbcTemplate이 런타임 예외로 예외를 포장해준 덕에 DAO에서 사용하는 기술에 완전히 독립적인 인터페이스 선언이 가능해졌다. 하지만, 이것만으로 충분할까?
남은 문제는 데이터 엑세스 예외 중 의미있게 처리할 수 있는 문제는 잘 처리하고 싶은데, 예외가 DB마다 달라서 일괄적으로 처리할 수가 없다는 것이다. 중복 키 예외만 해도 다음과 같이 나뉜다.
JDBC:SQLExceptionJPA:PersistenceExceptionHibernate:HibernateException
이렇게 예외가 나눠지면, DAO의 클라이언트 입장에서는 기술에 의존적인 예외처리 방법을 쓸 수밖에 없다. 그래서 단지 인터페이스로 추상화하고 일부 기술에서 발생하는 체크 예외를 런타임 예외로 전환해도 기술에 종속적인 코드를 작성하는 것을 피할 수 없다.
데이터 엑세스 예외 추상화와 DataAcessException 계층구조
스프링은 자바의 다양한 데이터 액세스 기술을 사용할 때 발생하는 예외들을 추상화해서 DataAcessException 계층구조 안에 정리해놓았다.
DataAcessException은 자바의 주요 데이터 액세스 기술에서 발생할 수 있는 대부분의 예외를 추상화하고 있다. 데이터 액세스 기술이 갖는 공통적인 예외도 있지만, 일부 기술에서만 발생하는 예외도 있다. ORM에서는 발생하지만, JDBC에는 없는 예외도 있다. 스프링의 DataAccessException은 이런 일부 기술에서만 공통적으로 나타나는 예외를 포함해서 데이터 액세스 기술에서 발생 가능한 대부분의 예외를 계층구조로 분류해놓았다.
이를테면 데이터 액세스 기술을 부정확하게 사용하면 InvalidDataAcessResourceUsageException 예외가 던져지며, 이를 다시 구체적으로 세분화하면, BadGrammerException(JDBC), HibernateQueryException(Hibernate)로 나뉘고, 잘못된 타입을 사용하면 나오는 TypeMismatchDataAccessException 예외로 구분된다.
InvalidDataAcessResourceUsageException 예외는 대부분 프로그램을 잘못 작성해서 발생하는 예외이다. 스프링이 기술의 종류에 상관없이 이런 예외를 던져주므로, 시스템 레벨의 예외처리 작업을 통해 개발자에게 빠르게 통보해주도록 만들 수 있다.
또, ORM에서는 같은 정보를 두 명 이상의 사용자가 동시에 조회하고 순차적으로 업데이트할 때, 뒤늦게 업데이트한 것이 먼저 업데이트한 것을 덮어쓰지 않도록 막아주기 위한 기능인 낙관적인 락킹(Optimistic Locking)이 발생할 수 있다. 이런 예외들은 사용자에게 적절한 안내 메세지를 보여주고, 다시 시도할 수 있또록 해줘야 한다. 스프링은 이러한 예외를 기술에 상관없이 DataAccessException의 서브 클래스인 ObjectOptimisticLockingFailureException으로 통일시킬 수 있다.
ORM이 아니지만 JDBC를 이용해 낙관적인 락킹 기능을 구현했다면, JdbcOptimisticLockingFailureException을 정의해서 사용할 수도 있다.
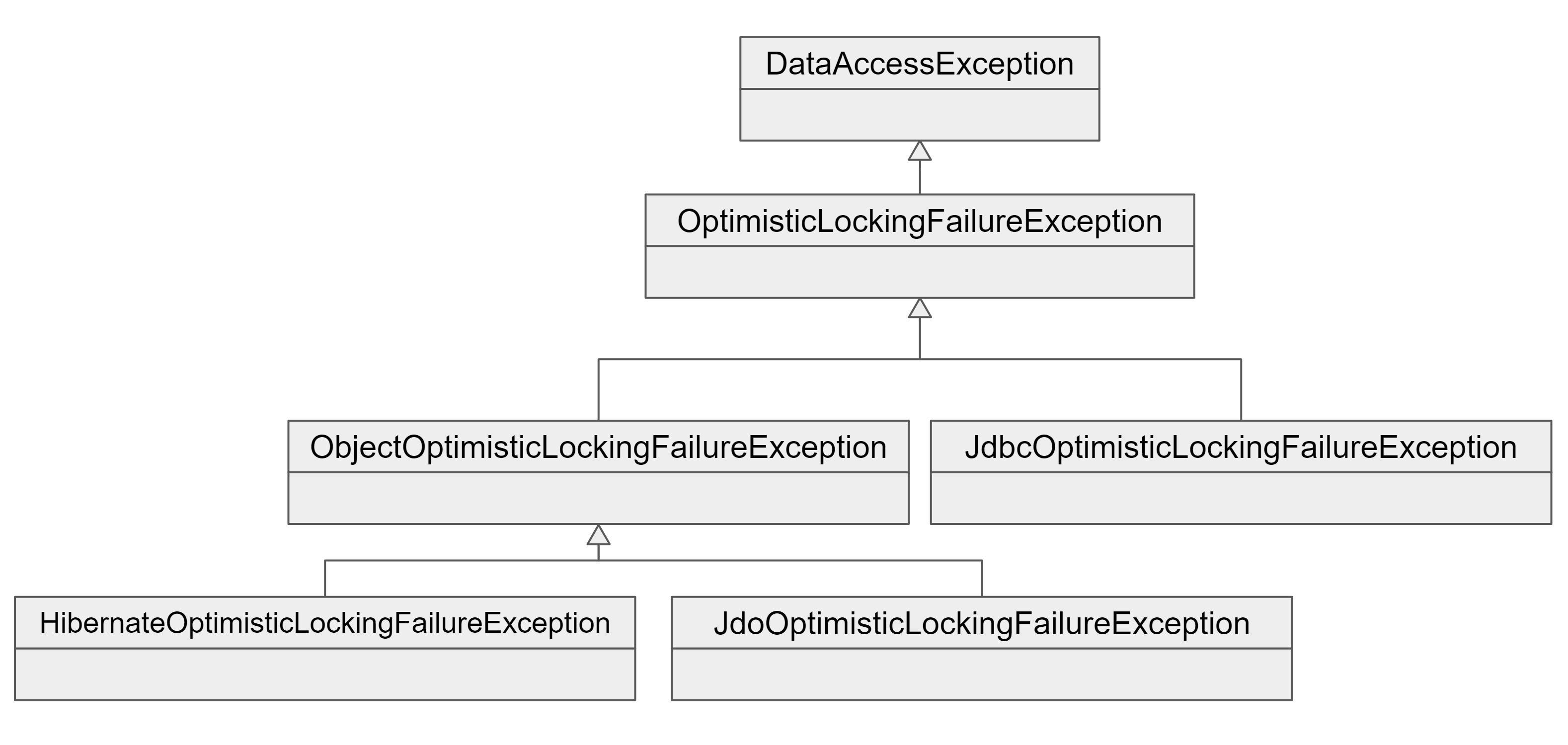
위와 같은 구조를 만들어낼 수 있다. JdbcOptimisticLockingFailureException만 커스터마이징하여 추가된 것이다.
이 외에도 DataAcessException 계층 구조에는 템플릿 메소드나 DAO에서 직접 활용할 수 있는 예외도 정의되어 있다. JdbcTemplate의 queryForObject() 메소드는 한 개의 Row로 돌려주는 쿼리에만 사용하게 되어있는데, 쿼리 실행 결과가 더 많은 Row를 가져오면, SQL을 잘못 작성한 것이다. 이 경우에 JDBC에서는 예외가 발생하지 않지만, JdbcTemplate에서는 DataAcessException 계층구조에 있는 IncorrectResultSizeDataAccessException이 정의되어 있다. 만일 아무런 결과가 나오지 않는다면 EmptyResultDataAcessException을 던질 것이다.
@Test
@DisplayName("존재하지 않는 회원을 조회할 때")
public void getUserFailure() {
// 스프링이 제공하는 EmptyResultDataAccessException 예외가 나타나게 만들자.
assertThrows(EmptyResultDataAccessException.class, () -> {
userDao.get("not_existing_user_id");
});
}
@Test
@DisplayName("QueryForObject를 이용해 2개 이상의 Row 결과가 나왔을 때")
public void getUserFailure2() {
userDao.add(new User("user1", "김똘일", "1234"));
userDao.add(new User("user2", "김똘일", "1234"));
assertThrows(IncorrectResultSizeDataAccessException.class, () -> {
userDao.getByName("김똘일");
});
}위와 같은 테스트를 작성해보면 알 수 있고, 당연히 성공한다.
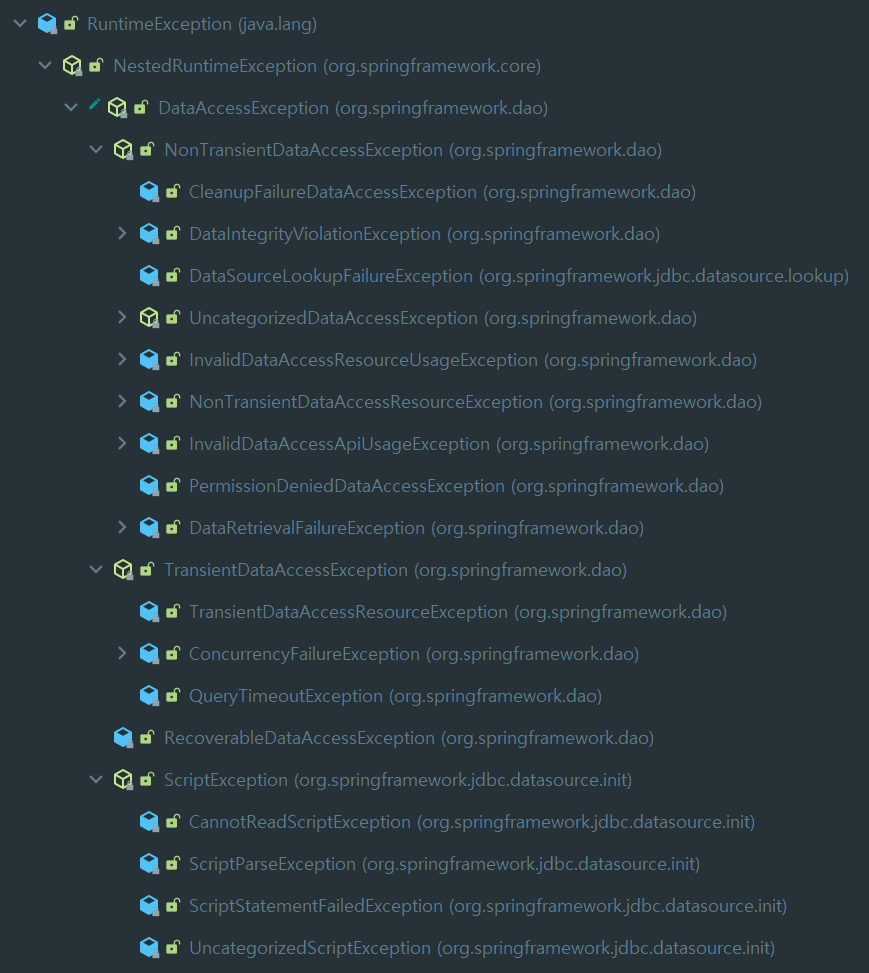
DataAccessException 밑으로 아주 많은 Exception들이 존재한다.
JdbcTemplate과 같이 스프링의 데이터 액세스 지원 기술을 이용해 DAO를 만들면, 사용 기술에 독립적인 일관성 있는 예외를 던질 수 있다. 결국 인터페이스 사용, 런타임 예외 전환과 함께 DataAccessException 예외 추상화를 적용하면 데이터 액세스 기술과 구현 방법에 독립적인 이상적인 DAO를 만들 수 있다.
기술에 독립적인 UserDao 만들기
인터페이스 적용
인터페이스 이름 앞에는 I라는 접두어를 붙이는 방법도 있고, 인터페이스 이름을 기본형으로 가장 단순하게 하고 구현 클래스는 각각의 특징을 따르는 이름을 붙이는 경우도 있다. 여기서는 후자의 방법을 사용한다. 우리가 만드는 인터페이스 이름은 UserDao로 하고, 현재 만들어놨던 구현체는 UserDaoJdbc라고 해보자.
public interface UserDao {
void add(User user);
User get(String id);
User getByName(String name);
List<User> getAll();
void deleteAll();
int getCount();
}위와 같이 인터페이스를 추가했다. getByName()은 queryForObject()의 결과가 2건 이상일 때를 테스트하기 위해서 이름으로 검색하는 부분을 만들어보았다.
또, setDataSource() 메소드는 인터페이스에 추가하면 안된다는 사실에 주의하자. setDataSource()메소드는 UserDao의 구현 방법에 따라 변경될 수 있는 메소드이고, UserDao를 사용하는 클라이언트가 알고 있을 필요도 없다.
public class UserDaoJdbc implements UserDao {UserDaoJdbc가 UserDao를 상속하도록 했다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="username" value="postgres" />
<property name="password" value="iwaz123!@#" />
<property name="driverClass" value="org.postgresql.Driver" />
<property name="url" value="jdbc:postgresql://localhost/toby_spring" />
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userDao" class="toby_spring.user.dao.UserDaoJdbc">
<property name="jdbcTemplate" ref="jdbcTemplate" />
</bean>
</beans>구현체는 UserDaoJdbc라는 클래스를 그대로 사용해주고, 빈의 id는 관례상 인터페이스의 이름으로 해주었다. 그래야 나중에 인터페이스를 마음껏 바꾸어도 혼란이 없다.
테스트 보완
public class UserDaoTest {
@Autowired UserDao userDao;
...UserDao 인터페이스를 구현하고, UserDaoJdbc를 UserDao의 구현체로 구조를 바꾸었다고 해도 테스트에서는 굳이 수정할 코드는 없다. @Autowired는 스프링 컨텍스트 내에 정의된 빈 중에서 인스턴스 변수에 주입 가능한 타입의 빈을 자동으로 찾아준다. 당연히 UserDaoJdbc는 UserDao 타입이기 때문에 자동으로 주입된다.
만일 UserDaoJdbc라는 구현체 자체를 테스트하고 싶다면, 명확하게 UserDaoJdbc 타입을 받아오는 편이 좋지만, UserDao를 테스트하고자 한다면, UserDao 타입을 이용해서 UserDaoJdbc 타입의 빈을 주입받는 것이 더 옳다.
UserDaoTest는 실제 애플리케이션의 코드를 포함하진 않지만, 하나의 클라이언트라고 봐도 무방하다.

중복된 유저를 등록하는 테스트 추가
@Test
@DisplayName("중복된 유저를 등록했을 때")
public void addDuplicateUsers() {
Assertions.assertThrows(DataAccessException.class, () -> {
userDao.add(user1);
userDao.add(user1);
});
}위는 중복된 유저를 등록하는 테스트이다. 스프링의 JdbcTemplate을 사용해서 등록하기 때문에, 스프링이 내주는 예외 중 최상위 예외인 DataAccessException의 하위 클래스 예외 중 하나가 나올 것이다.
만일 정확히 어떤 예외가 나는지 궁금하다면, 실제로 예외를 내보면 된다.
org.springframework.dao.DuplicateKeyException: PreparedStatementCallback; SQL [insert into users(id, name, password) values (?, ?, ?)]; 오류: 중복된 키 값이 "users_pkey" 고유 제약 조건을 위반함
Detail: (id)=(user1) 키가 이미 있습니다.; nested exception is org.postgresql.util.PSQLException: 오류: 중복된 키 값이 "users_pkey" 고유 제약 조건을 위반함
Detail: (id)=(user1) 키가 이미 있습니다.위와 같이 친절하게 DuplicateKeyException이라고 알려준다.
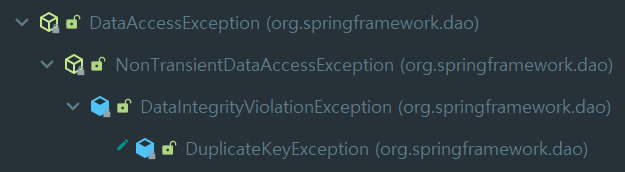
DuplicateKeyException은 DataAccessException 하위 NonTransientDataAccessException 하위 DataIntegrityViolcationException 하위 DuplicateKeyException에 위치한다.
책에는 없는 내용이지만, 예외 전환 연습겸 더 정확한 의미를 가지는 예외로 감싸고 테스트를 새로 구성해보았다.
public class DuplicateUserIdException extends RuntimeException{
public DuplicateUserIdException(Throwable cause) {
super(cause);
}
} public void add(User user) throws DuplicateUserIdException {
try {
this.jdbcTemplate.update("insert into users(id, name, password) values (?, ?, ?)"
, user.getId()
, user.getName()
, user.getPassword()
);
} catch (DuplicateKeyException e) {
throw new DuplicateUserIdException(e);
}
} @Test
@DisplayName("중복된 유저를 등록했을 때")
public void addDuplicateUsers() {
Assertions.assertThrows(DuplicateUserIdException.class, () -> {
User user1 = new User("userDuplicate", "김중복", "1234");
User user2 = new User("userDuplicate", "김중복", "1234");
userDao.add(user1);
userDao.add(user2);
});
}더욱 정확하게 해당 예외의 의미를 나타낼 수 있도록 DuplicateUserIdException이라는 예외를 만들고, DuplicateKeyException이 들어오면 해당 예외로 감싸서 던지도록 만들었다. 런타임 예외라서 해당 메소드를 사용하는 다른 메소드에서 불필요한 throws를 할 필요도 없다.
DataAccessException 활용 시 주의사항
스프링을 활용하면 DB 종류나 데이터 액세스 기술에 상관없이 키 값이 중복되는 상황에서 동일한 예외가 발생할 것이라고 기대할텐데, 안타깝게도 DuplicateKeyException은 아직까지는 JDBC를 이용하는 경우에만 발생한다.
SQLException에 담긴 에러 코드를 바로 해석하는 JDBC의 경우와 달리 JPA나 하이버네이트, JDO 등에서는 각 기술이 재정의한 예외를 가져와 스프링이 최종적으로 DataAccessException으로 변환하는데, DB의 에러 코드와 달리 이런 예외들은 세분화 되어 있지 않기 때문이다.
하이버네이트는 중복 키가 발생하면, ConstraintViolationException을 발생시킨다. 스프링은 이를 해석해서 좀 더 포괄적인 예외인 DataIntegrityViolationException으로 변환할 수 밖에 없다. 물론 DuplicateKeyException도 DataIntegritiyViolationException의 한 종류다. 따라서 DataIntegrityViolationException으로 해준다면 하이버네이트로 만든 DAO로 바꾼다고 해도 동일한 예외를 기대할 수는 있다. 하지만 제약 조건을 위반하는 다른 상황에서도 동일한 예외가 발생하기 때문에 DuplicateKeyException을 이용하는 경우에 비해서는 이용가치가 떨어진다.
스프링의 DataAccessException이 어느정도 추상화된 공통 예외로 변환해주긴 하지만 근본적 한계 때문에 완벽하다고 기대할 수는 없다. DataAccessException을 잡아서 처리하는 코드를 만들려고 한다면 미리 학습 테스트를 만들어서 실제로 전환되는 예외의 종류를 확인할 필요가 있다.
기술의 종류와 상관없이 동일한 예외를 얻고 싶다면, DuplicatedUserIdException처럼 직접 예외를 정의해두고, 각 DAO의 add() 메소드에서 좀 더 상세한 예외 전환을 해줄 필요가 있다. 하이버네이트 예외의 경우라도 중첩된 예외로 SQLException이 전달되기 때문에 이를 다시 스프링의 JDBC 예외 전환 클래스의 도움을 받아서 처리할 수 있다.
스프링은 SQLException을 DataAccessException으로 전환하는 다양한 방법을 제공한다. 가장 보편적이고 효과적인 방법은 DB 에러 코드를 이용하는 것이다. SQLException을 코드에서 직접 전환하고 싶다면 SQLExceptionTranslator 인터페이스를 구현한 클래스 중 SQLErrorCodeSQLExceptionTranslator를 사용하면 된다.
JDBC에서 SQLException 해석해보기
@Test
@DisplayName("SQLException DB 에러코드 해석기로 DataAccessException 해석해보기")
public void sqlExceptionTranslate() {
try {
userDao.add(user1);
userDao.add(user1);
}catch(DataAccessException ex) {
SQLException sqlEx = (SQLException) ex.getRootCause();
SQLExceptionTranslator set =
new SQLErrorCodeSQLExceptionTranslator(this.dataSource);
DataAccessException translate = set.translate(null, null, sqlEx);
Assertions.assertEquals(DuplicateKeyException.class, translate.getClass());
}
}스프링 DAO 예외의 최상위에 있는 DataAccessException 클래스로 예외를 잡아서 .getRootCause()를 하면 SQLException를 얻을 수 있다. 위와 같이 SQLErrorCodeSQLExceptionTranslator()를 이용해 해석했을 때 DuplicateKeyException 클래스가 나오는지 확인해보는 클래스를 실행해보면 잘 성공한다.
Spring Data JPA에서 SQLException 해석해보기
@Test
public void save() {
try {
Item item = new Item("A");
Item item2 = new Item("A");
itemRepository.save(item);
itemRepository.save(item2);
} catch(DataAccessException e) {
SQLException sqlException = (SQLException) e.getRootCause();
SQLExceptionTranslator set = new SQLErrorCodeSQLExceptionTranslator(dataSource);
DataAccessException translate = set.translate(null, null, sqlException);
assertThat(translate.getClass()).isEqualTo(DuplicateKeyException.class);
}
}스프링 데이터 JPA에서도 SQLErrorCodeSQLExceptionTranslator()를 이용해 해석해보면 동일하게 DuplicateKeyException이 나온다. 스프링 덕에 다른 DB를 사용하더라도 같은 예외 클래스를 예외로 잡아서 처리해줄 수 있다.
단, 주의할 점은
dataSource를 인자로 안 줘도SQLErrorCodeSQLExceptionTranslator클래스는 오류없이 잘 생성되는데 그 경우에는 더욱 포괄적인DataIntegrityViolationException이 결과로 나온다. 조심하자. 오류가 없기 때문에 실수하기 쉬운 부분이다.
생각해볼 점
현재는 JdbcTemplate을 이용하기 때문에 스프링이 자동으로 DataAccessException이라는 예외 구조 안에 있는 예외 중 하나로 SQLException을 변경해주지만, 사실 스프링 프레임워크가 없더라도 얼마든지 스스로 구현할 수 있는 부분이다. 스프링의 기능을 사용할 수 없는 경우라도 SQLException을 굳이 그대로 두어 의미없는 throws만을 작성하지 말고, 우리가 배웠던 예외 전환과 예외 감싸기를 활용하여 의미 있는 RuntimeException으로 바꿔주면 소프트웨어의 품질이 한층 높아질 수 있다. 또한 우리가 직접 스프링의 DataAccessException 계층의 예외로 전환해줄 수도 있음을 기억하자.
