
리스트 안에 각기 다른 차원의 리스트나 리스트가 아닌 값들이 섞여있을 때, 전부 1차원 배열로 만드는 코드를 작성하기.
본 포스트에서는 재귀함수를 통한 해법을 제시하므로, 재귀함수에 대한 설명이 필요하면 아래 링크를 통해 참고하시기 바랍니다.
재귀함수에 대한 설명
https://velog.io/@jakkelab/Algorithm-재귀함수
#재귀문을 통한 다차원 배열을 1차원으로 바꾸기
def Flatten_List(input):
#처음 들어온 값이 리스트인지 아닌지 확인. 리스트가 아니면 메시지 반환하여 함수 종료
if(isinstance(input, list) == False):
return "Input is not a list. Please insert list as input data."
#받은 리스트 안에 리스트가 있는 지 없는 지를 검사하기 위한 값
input_hasList = False
#리스트 내 항목 검사 시작
for item in input:
#아이템의 원래 인덱스 저장
index_original = input.index(item)
item_original = item
#리스트면 꺼내서 원래 자리에 하나씩 넣고, 원래값(기존 리스트)은 제거
index_temp = index_original
#이 항목이 리스트인지 검사
if(isinstance(item, list)):
#리스트가 있었으니 True로 바꿈
input_hasList = True
for value in item:
input.insert(index_temp, value)
index_temp += 1
input.remove(item)
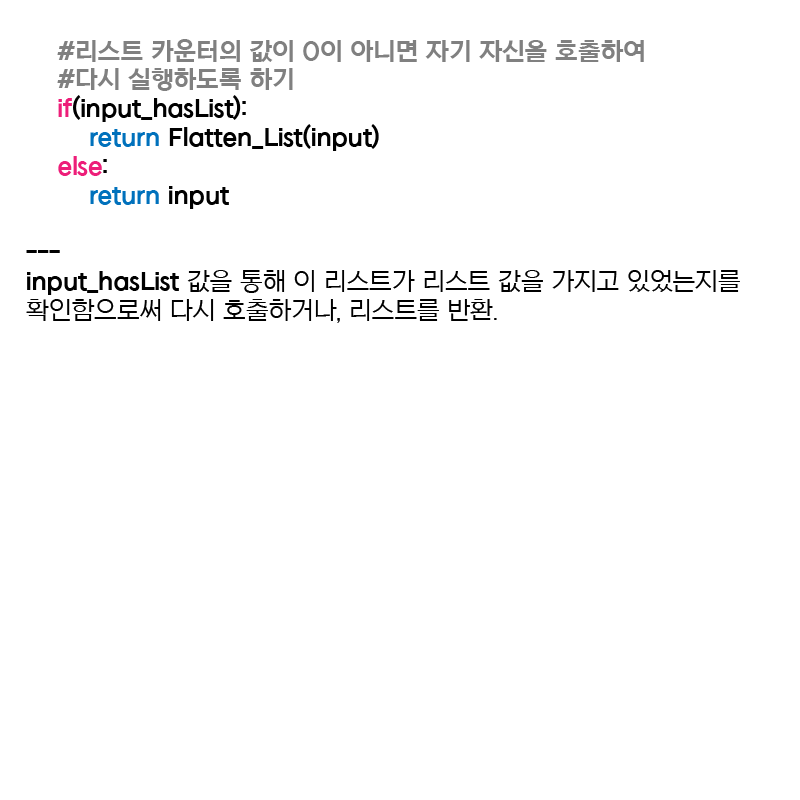
#리스트 카운터의 값이 0이 아니면 자기 자신을 호출하여 다시 실행하도록 하기
if(input_hasList):
return Flatten_List(input)
else:
return input
#테스트용 데이터 및 출력
inputData = [1, [2, [3, 4], 5], [[6, [7,8]],["a", "b", [["c"], "d"]]], 9, [[[[[10]]]]]]
print(Flatten_List(inputData))
#실행결과
[1, 2, 3, 4, 5, 6, 7, 8, "a", "b", "c", "d", 9, 10]
사실 리스트 안에 리스트가 포함되어있는 부분을 매 리스트 항목 검사마다 새로운 값을 할당하고 있으니 메모리 적인 면에서 비효율이 발생하긴 하지만, 그 정도가 크지 않아서 위 예제코드에서는 그대로 뒀습니다.
각 항목의 설명은 아래와 같습니다.




시간을 설계하는 건축가