칼럼형 DB와 로우형 DB
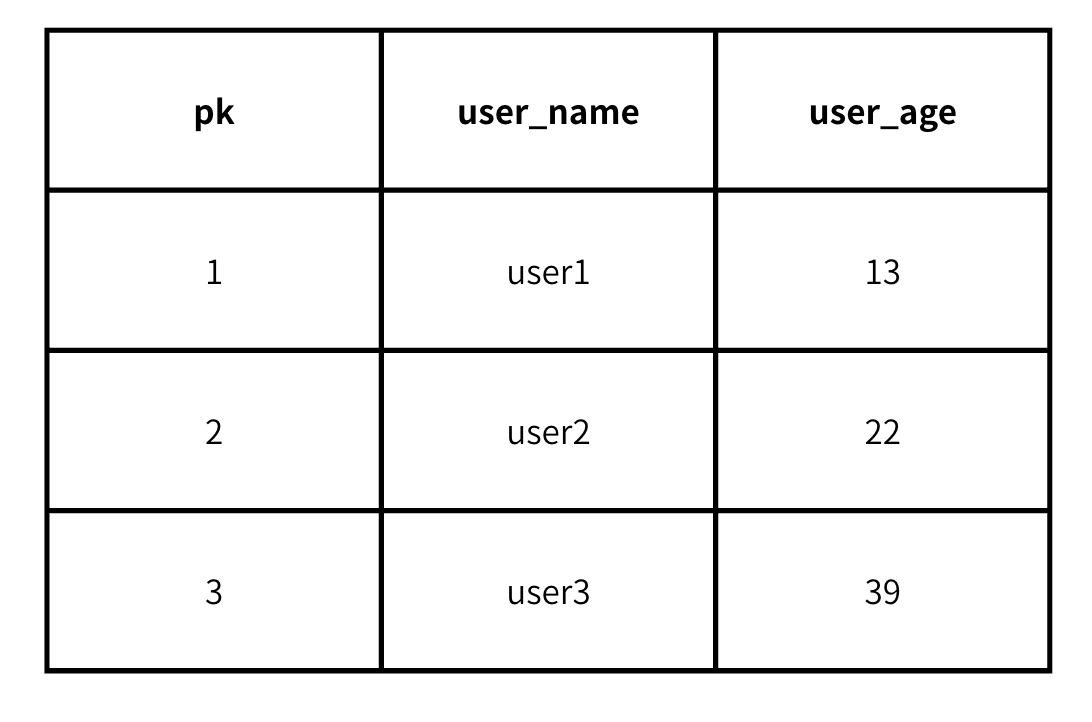
데이터베이스는 기본적으로 인덱스 방식을 사용하며 인덱스를 통해 데이터를 조회하는 방식으로 데이터를 탐색합니다.
위와 같은 테이블을 저장할 때 저장 방식에 따라 칼럼형 DB와 로우형 DB가 나뉘어집니다.
로우형 DB란
로우형 DB의 경우 위 테이블을 저장할 때 로우를 기준으로 저장하게 됩니다.
하나의 인덱스에 하나의 로우 전체를 한번에 저장하는 방식입니다.
{1 : user1, 13; 2 : user2, 22; 3 : user3, 39}위와 같이 하나의 인덱스를 통해 전체 데이터가 한번에 조회가 됩니다.
칼럼형 DB란
칼럼형 DB의 경우 위 테이블을 저장할 때 칼럼을 기준으로 저장하게 됩니다.
하나의 인덱스에 하나의 데이터만 저장되는 방식입니다.
{1 : user1; 2 : user2; 3 : user3}, {1 : 13; 2 : 22; 3 : 39}위와 같이 한번의 탐색을 통해 하나의 칼럼만을 가져올 수 있습니다.
비교
단순 조회(열 전체 조회)
SELECT * FROM USER;로우형 DB
한번의 탐색을 통해 모든 유저의 정보를 가져오는 문법이며 로우형 DB의 경우 각 조회시 전체 데이터를 조회하기 때문에 빠른 조회 속도를 보입니다.
칼럼형 DB
각각의 칼럼을 조회해야하기 때문에 효율적이지는 않습니다.
단순 조회(열 일부 조회)
SELECT name FROM USER;로우형 DB
한번에 모든 값을 가져오는 로우형 DB의 경우 불필요한 데이터를 같이 조회하기 때문에 느린 속도를 보입니다.
칼럼형 DB
필요한 값만 가져올 수 있기 때문에 빠르고 효율적으로 탐색할 수 있습니다.
기본적으로 하나의 데이터블록 크기가 작은 칼럼형 DB의 조회 속도가 더 빠릅니다.
삽입, 수정, 삭제
로우형 DB
하나의 데이터를 삽입, 수정, 삭제하는 경우, 해당 동작을 로우 단위로 진행하기 때문에 한번의 조회와 삽입, 수정, 삭제가 이루어져 빠른 속도를 보입니다.
칼럼형 DB
하나의 로우를 삽입, 수정, 삭제하는 경우, 해당 동작을 위해 각 칼럼의 데이터 블록에 접근해야하기에 칼럼의 개수만큼의 탐색을 필요로하여 느린 속도를 보입니다.
데이터 저장 효율
로그 데이터와 같이 정말 많은 데이터를 저장해야하는 경우 같은 저장장치이더라도 데이터를 효율적으로 저장하는 것이 정말 중요할 것입니다.
로우형 DB
하나의 데이터를 한번에 저장하기 때문에 서로 다른 타입이 모여 패딩이 생기며 조금은 비효율적이라고 볼 수 있습니다.
칼럼형 DB
각 칼럼은 특정 타입으로 지정되기 때문에 같은 타입을 저장시켜 저장 효율이 높습니다.
또한 남/여를 구분하는 칼럼과 같이 중복된 값이 많은 경우 남, 남, 남, 남, 여, 여를 남:4, 여:2와 같이 중복 값을 줄이는 방법을 사용할 수 있어 저장 효율이 매우 높은 편에 속합니다.
통계/분석 쿼리
SELECT SUM(age) FROM user;로우형 DB
하나의 컬럼을 통계를 내기위해 전체 데이터를 모두 조회해야하여 느린 속도를 가지고 있습니다.
칼럼형 DB
필요한 칼럼만을 조회하여 더 빠른 통계/분석 성능을 보입니다.
정리
| 항목 | 로우형 DB | 칼럼형 DB |
|---|---|---|
| 삽입/수정/삭제 성능 | 빠름 | 느림 |
| 조회 성능 (전체 열) | 빠름 | 비효율적 |
| 조회 성능 (일부 열) | 비효율적 | 빠름 |
| 저장 효율 | 일반적 | 효율적 |
| 통계/분석 쿼리 | 느림 | 빠름 |
로우형 DB의 경우 삽입/수정/삭제가 활발한 경우 사용하기 좋으며 칼럼형 DB의 경우 조회가 활발하거나 많은 데이터를 저장하거나 인덱스 조회가 아닌 특정 칼럼 조건 조회 및 통계, 분석하는 조회시 더 유리한 면을 보입니다.
따라서 단순 CRUD를 이용하는 경우 로우형 DB, 복잡한 쿼리를 사용하거나 많은 데이터를 저장하는 경우 칼럼형 DB라고 생각하는 것이 좋을 것 같습니다.
