이 글을 작성한 이유
필자는 Hash보다 Tree를 선호하는데 Hash는 데이터나 해시함수에 따라 성능 격차가 생기며 이는 코드를 작성하는 사람이 대부분 제어할 수 없는 영역이 많기 때문이다. 하지만 TreeMap과 TreeSet을 사용하면서 알 수 없는 오류가 발생하였고 이를 알아보며 이 내용을 작성하게 되었습니다.
TreeMap, TreeSet이란
TreeMap과 TreeSet의 차이
Map - Entry를 사용하여 중복이 없는 키와 값을 가진 자료구조
Set - 중복없이 데이터를 저장하는 자료구조
Tree(Map||Set)이란
기본적으로 R-B Tree를 사용하여 데이터를 정렬시켜 저장하는 자료구조입니다. R-B Tree는 Red노드와 Black노드를 나누어 해당 노드의 색깔을 이용하여 스스로 밸런스를 유지시키는 자가 균형 이진 탐색 트리입니다. 이러한 방식으로 데이터를 정렬하여 저장하며 탐색, 추가, 수정, 삭제를 이라는 시간복잡도를 가집니다.
간단한 사용법
기본적으로 해시와 사용법이 비슷하지만 선언할 때 Comparable을 상속받지 않은 클래스는 Comparator가 필요하다는 점이 차이가 있습니다.
선언
- Comparable를 상속받는 클래스
TreeSet<Integer> intSet = new TreeSet<>();- Comparable를 상속받지 않는 클래스
TreeSet<Node> set = new TreeSet<>(Comparator.comparingInt(Node::getValue));추가 및 삭제
// 추가
intSet.add(10);
set.add(new Node(1, 1));
// 삭제
intSet.remove(10);
set.remove(new Node(1, 1));Map도 put, remove등으로 HashMap과 같은 방식으로 사용하면 됩니다.
문제 상황
그렇다면 TreeMap에는 어떤 문제가 있을까요?
다음과 같은 코드에서 출력은 어떻게 나올까요?
package treeMap;
import java.util.*;
public class TreeMapTest {
public static void main(String[] args) {
testSet();
testMap();
}
static void testSet() {
Set<Node> set = new HashSet<>();
set.add(new Node(1, 3));
System.out.println(set.size());
set.add(new Node(2, 4));
System.out.println(set.size());
set.add(new Node(3, 4));
System.out.println(set.size());
}
static void testMap() {
Map<Node, Integer> map = new HashMap<>();
map.put(new Node(1, 3), 1);
System.out.println(map.size());
map.put(new Node(2, 4), 2);
System.out.println(map.size());
map.put(new Node(3, 4), 3);
System.out.println(map.size());
}
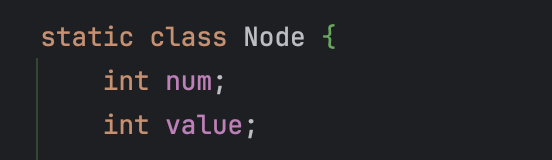
static class Node {
int num;
int value;
public Node(int num, int value) {
this.num = num;
this.value = value;
}
public int getValue() {
return value;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Node)) return false;
Node n = (Node) obj;
return this.num == n.num && this.value == n.value;
}
}
}먼저 코드를 작성한 목적을 보여드리기 위해 Hash를 사용한 코드를 먼저 보여드렸습니다.
각각의 Set과 Map에 들어간 값은 각각 다른 노드로 기본적인 해시함수에 의해 해당 인스턴스의 좌표로 해시값이 들어가 각각 다르게 인식할 것입니다. 따라서 아래와 같은 결과가 나옵니다.
1
2
3
1
2
3
하지만 Tree로 바꾸는데 위에 선언한 것처럼 value를 기준으로 만들면 어떻게 될까요?
import java.util.*;
public class TreeMapTest {
public static void main(String[] args) {
testSet();
testMap();
}
static void testSet() {
Set<Node> set = new TreeSet<>(Comparator.comparingInt(Node::getValue));
set.add(new Node(1, 3));
System.out.println(set.size());
set.add(new Node(2, 4));
System.out.println(set.size());
set.add(new Node(3, 4));
System.out.println(set.size());
}
static void testMap() {
Map<Node, Integer> map = new TreeMap<>(Comparator.comparingInt(Node::getValue));
map.put(new Node(1, 3), 1);
System.out.println(map.size());
map.put(new Node(2, 4), 2);
System.out.println(map.size());
map.put(new Node(3, 4), 3);
System.out.println(map.size());
}
static class Node {
int num;
int value;
public Node(int num, int value) {
this.num = num;
this.value = value;
}
public int getValue() {
return value;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Node)) return false;
Node n = (Node) obj;
return this.num == n.num && this.value == n.value;
}
}
}이렇게 코드를 바꾸어 작성한 코드의 결과는 아래와 같이 나오게 됩니다.
1
2
2
1
2
2
equals로 다르다는 것을 인지시켜줬음에도 불구하고 getValue를 통해 얻은 값이 같다는 것을 토대로 연산이 되기 때문입니다.
또한 이러한 과정에서 Map과 Set의 동작은 약간이지만 다른 결과를 만들어냅니다.
Map은 Node(2, 4)와 Node(3, 4)가 같다고 판단하여 Node(2, 4)의 키 값은 그대로 둔 상태로 이전의 값인 2를 3으로 변경하게 됩니다.
Set은 Node(2, 4)가 이미 존재하기 때문에 변경되지 않은 상태로 진행이 될 것입니다.
코드를 추가적으로 살짝 바꾸어 적용시켜본다면 다음과 같은 코드와 결과를 얻게될 것입니다.
import java.util.*;
public class TreeMapTest {
public static void main(String[] args) {
testSet();
testMap();
}
static void testSet() {
Set<Node> set = new TreeSet<>(Comparator.comparingInt(Node::getValue));
set.add(new Node(1, 3));
System.out.println(set.size());
set.add(new Node(2, 4));
System.out.println(set.size());
set.add(new Node(3, 4));
System.out.println(set.size());
for (Node node : set) {
System.out.println(node.num + " " + node.value);
}
}
static void testMap() {
Map<Node, Integer> map = new TreeMap<>(Comparator.comparingInt(Node::getValue));
map.put(new Node(1, 3), 1);
System.out.println(map.size());
map.put(new Node(2, 4), 2);
System.out.println(map.size());
map.put(new Node(3, 4), 3);
System.out.println(map.size());
for (Map.Entry<Node, Integer> en : map.entrySet()) {
System.out.println(en.getKey().num + " " + en.getValue());
}
}
static class Node {
int num;
int value;
public Node(int num, int value) {
this.num = num;
this.value = value;
}
public int getValue() {
return value;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Node)) return false;
Node n = (Node) obj;
return this.num == n.num && this.value == n.value;
}
}
}1
2
2
1 3
2 4
1
2
2
1 1
2 3
해결 방법
1. getValue 고치기
public int getValue() {
return value * 1000 + num;
}만약 num이 1000보다 작은 숫자만 들어갈 수 있다면 다음과 같은 방식으로 value를 통해 정렬하며 num이 다를 경우 다른 값으로 받아들일 수 있게 됩니다.
2. 정렬 조건 추가시키기
Map<Node, Integer> map = new TreeMap<>(Comparator.comparingInt(Node::getValue)
.thenComparingInt(Node::getNum));다음과 같은 방법으로 정렬 조건을 추가시켜 정렬을 시킬 때 완전히 같지 않도록 설정한다면 해결할 수 있습니다.
정리
TreeMap과 TreeSet은 정렬 과정에서 같은 값이라고 생각한다면 해당 인스턴스가 같지 않더라도 같은 값으로 인식하여 문제가 생길 수 있습니다. 따라서 조건을 추가시키거나 정렬할 값의 정의를 바꾸어 다른 값이 같은 값으로 인식하는 일이 없도록 하는 것이 정말 중요합니다.
느낀점
Hash함수에서는 충돌이 일어날 경우를 생각하였지만 Tree의 경우 equals를 통해 같은 값이 아님을 증명한다고 하더라도 내부적으로 같다고 처리되는 것을 생각하지 못했습니다. 이전에 RB트리를 만들면서 내부를 이해했으나 실제 적용에서 이러한 문제를 인지하지 못한 안일함이 컸던 것 같습니다. 한 코드를 더 작성하는 것보다 해당 코드의 내부 동작을 꼼꼼히 파악하고 작성하는 것이 더 좋은 개발자로 성장하는 길이 될 것이라고 생각합니다.
