2장. 데이터 모델과 성능
5. 데이터베이스 구조와 성능
-
슈퍼/서브타입 데이터 모델의 성능 고려 방법
- 모델의 개요
- Extended ER 모델이라고도 불림
- 데이터의 공통점과 차이점을 효과적으로 표현할 수 있기 때문에 자주 쓰임
- 공통 부분 - 슈퍼타입 모델링, 차이점 - 다른 엔티티와 차이가 있는 속성에 대해서는 별도의 서브엔티티로 구분
- 논리적인 데이터 모델이서 이용/분석 단계에서 많이 쓰이는 모델
- 슈퍼/서브타입 데이터 모델의 변환
- 변환 오류로 성능이 저하되는 경우
- 트랜잭션은 항상 일괄로 처리하는데, 테이블은 개별로 유지되어 Union 연산에 의해 성능 저하 발생
- 트랜잭션은 항상 서브타입 개별로 처리하는데, 테이블한 하나로 통합되어 있어 불필요하게 많은 양의 데이터가 집약된 경우
- 트랜잭션은 항상 슈퍼+서브타입을 공통으로 처리하는데, 개별로 유지되어 있거나 하나의 테이블로 집약된 경우
- 데이터가 소량일 경우
- 성능에 영향을 미치지 않으므로 데이터 처리의 유연성을 고려하거나, 1:1 관계 유지
- 용량이 커지면 다음 3가지 방법 고려
- 변환 오류로 성능이 저하되는 경우
- 슈퍼/서브타입 모델의 변환 기술
- 개별로 발생되는 트랜잭션: 개별 테이블로 구성(1:1 관계)
- 슈퍼타입+서브타입에 대해 발생되는 트랜잭션: 슈퍼타입+서브타입 테이블로 구성(Plus Type)
- 전체를 하나로 묶어 트랜잭션이 발생할 때: 하나의 테이블로 구성(Single, All in One)
- 슈퍼/서브타입 데이터 모델의 변환타입 비교
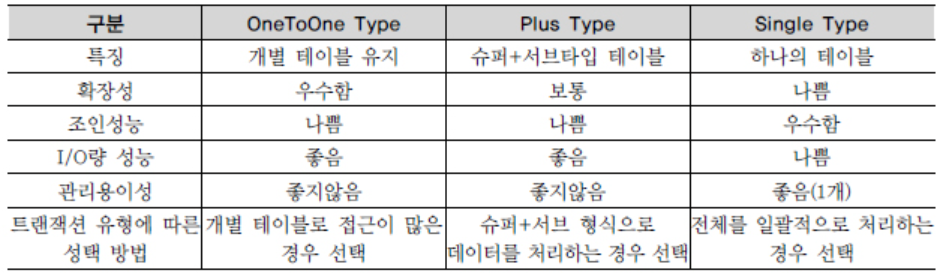
- 모델의 개요
-
인덱스 특성을 고려한 PK/FK 데이터베이스 성능 향상
- PK/FK 컬럼 순서와 성능 개요
- 데이터베이스 테이블에서는 균형 잡힌 트리 구조의 B-Tree 구조를 보편적으로 사용
- 성능 저하: PK가 여러 개의 속성으로 구성된 복합 식별자일 때, PK 순서에 대해 별로 고려하지 않고 데이터 모델링을 한 경우 발생
- PK는 해당 테이블의 데이터를 접근할 때 가장 빈번하게 사용되는 유일한 인덱스를 모두 자동 생성
- 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때, 앞쪽에 위치한 속성값이 비교자로 있어야 인덱스가 좋은 효율을 보임
- 앞 쪽에 있는 속성 값이 가급적 '=' 혹은 범위 'BETWEEN', '<', '>'가 들어와야 인덱스를 이용할 수 있음
- PK 컬럼의 순서 미조정에 따른 성능 저하
- 인덱스 특징에 맞게 고려하지 않고 PK 컬럼 생성 시, 테이블에 접근하는 트랜잭션의 특징에 효율적이지 않은 인덱스가 생성됨
- 이로 인해, 인덱스의 범위를 넓게 이용하거나, 테이블 Full Scan을 유발하여 성능 저하 발생
- PK/FK 컬럼 순서와 성능 개요
-
물리적인 테이블에 FK 제약이 걸려있지 않을 시, 인덱스 미생성으로 성능 저하
- 물리적인 테이블에 FK를 사용하지 않아도, 데이터 모델 관계에 따라 상속받은 FK 속성들은 SQL WHERE 절에서 JOIN으로 이용되는 경우가 많음
- 따라서, FK 인덱스를 생성해야 성능이 좋은 경우가 많음
- FK 인덱스를 적절하게 설계하여 구축하지 않았을 경우
- 개발 초기에는 데이터 양이 적기 때문에 성능 저하가 발생하지 않음
- 하지만, 시스템을 오픈하고 데이터가 누적될수록 SQL 성능이 나빠져 데이터베이스 서버에 심각한 장애 현상을 초래하게 됨
- 물리적인 테이블에 FK를 사용하지 않아도, 데이터 모델 관계에 따라 상속받은 FK 속성들은 SQL WHERE 절에서 JOIN으로 이용되는 경우가 많음
6. 분산 데이터베이스와 성능
- 분산 데이터베이스의 개요
- 분산 데이터베이스 정의
- 분산된 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스
- 논리적으로 동일한 시스템에 속하나, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임. 물리적 Site 분산, 논리적으로 사용자 통합, 공유
- 데이터베이스를 연결하는 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역 여러 노드로 위치시켜 사용성/성능을 극대화시킨 데이터베이스
- 분산 데이터베이스의 투명성
- 분할 투명성(단편화): 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단편의 사본이 여러 Site에 저장
- 위치 투명성: 사용하려는 데이터의 저장 장소 명시 불필요. 위치 정보가 System Catalog에 유지되어야 함
- 지역 사상 투명성: 지역DBMS와 물리적 DB 사이의 Mapping 보장. 각 지역 시스템 이름과 무관한 이름 사용 가능
- 중복 투명성: DB 객체가 여러 Site에 중복되어 있는지 알 필요가 없는 특성
- 장애 투명성: 구성요소(DBMS, 컴퓨터)의 장애에 무관한 트랜잭션의 원자성 유지
- 병행 투명성: 다수 트랜잭션 동시 수행 시, 결과의 일관성 유지, Time Stamp, 분산 2단계 Locking을 이용 구현
- 분산 데이터베이스의 적용 방법 및 장단점
- 분산 데이터베이스 적용 방법: 업무의 흐름에 따라 업무 구성별 아키텍쳐 특징에 기반하여 데이터베이스를 구성
- 분산 데이터베이스의 장단점
- 데이터베이스 분산 구성의 가치
- 가장 핵심적인 가치는 통합된 데이터베이스에서 제공할 수 없는 빠른 성능을 제공한다는 것
- 분산 데이터베이스의 적용 기법
- 테이블 위치 분산
- 설계된 테이블의 위치를 각각 다르게 하는 것. 도식화된 위치별 데이터베이스 문서가 요구됨
- 테이블 분할 분산(Fragmentation)
- 위치만 다른 곳에 두는 것이 아니라, 각각의 테이블을 쪼개어 분산
- 수평 분할: 노드(Node)에 따라 테이블을 특정 컬럼의 값을 기준으로 로우(Row)를 분리
- 수직 분할: 노드(Node)에 따라 테이블 컬럼을 기준으로 컬럼을 분리
- 테이블 복제 분산(Replication)
- 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형
- 부분 복제(Segment Replication): 통합된 테이블을 한 군데(본사)에 가지고 있으면서, 각 지사별로는 지사에 해당된 로우를 가지고 있는 형태. 여러 테이블에 조인이 발생하지 않는 빠른 작업 수행이 가능
- 광역 복제(Broadcast Replication): 통합된 테이블을 한 군데(본사)에 가지고 있으면서, 각 지사에도 본사와 동일한 데이터를 모두 가지고 있는 형태
- 테이블 요약 분산(Summarization)
- 지역 간, 서버 간에 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우
- 분석 요약(Rollup Replication): 각 지사별로 존재하는 동일 정보를 본사에서 통합하여, 다시 전체에 대해서 요약 정보를 산출하는 분산 방법
- 통합 요약(Consolidation Replication): 각 지사별로 존재하는 다른 내용의 정보를 본사에 통합하여, 다시 전체에 대해서 요약 정보를 산출하는 분산 방법
- 분석 요약은 지사에 있는 데이터를 이용하여 본사에서 통합하여 요약 데이터를 산정 vs 통합 요약은 지사에서 요약한 정보를 본사에서 취합하여 각 지사별로 데이터를 비교하기 위해 이용
- 테이블 위치 분산
- 분산 데이터베이스 적용
- 성능이 중요한 사이트에 적용
- 공통 코드, 기준 정보, 마스터 데이터 등에 대해 분산 환경을 구성하면 성능이 좋아짐
- 실시간 동기화가 요구되지 않을 경우, 거의 실시간(Near Real Time)의 업무적인 특징을 가지고 있을 때도 분산 환경을 구성 가능
- 특정 서버에 부하가 집중이 될 때, 부하를 분산할 경우
- 백업 사이트(Disaster Recovery Site)를 구성할 때, 간단하게 분산 기능을 적용 가능
- 분산 데이터베이스 정의

백엔드 개발자 지망생