앞서 제시한 아이디어들을 하나씩 시도해보도록 하자.
성능의 기준점으로 사용한 모델의 정보는 아래와 같다.
:: Learnable latent keyframes ::
:: Sparse positional features ::
:: Modulated implicit function ::
n_neurons
+ Dataset: 640x360(x300frames) Jockey video, n_epochs=10,000
| Metric | mini-NVP |
|---|---|
| Encoding duration (1,000 epoch) | 1:46:01 |
| Decoding duration | 01:19 |
| psnr | 30.63 |
| bpp | 0.735 |
| psnr(w/ codec compression) | 27.84 |
| bpp(w/ codec compression) | 0.259 |
1. 무조건 정사각형, 정육면체 형태의 latent grid를 선언하지 말고 video의 resolution, frame 수에 맞도록 조절하면 더 compact하게 정보를 저장할 수 있지 않을까?
기존의 2D, 3D latent grid는 height와 width의 size가 모두 동일한 형태였다. 이를 video frame의 비율에 맞게 설정해준다면?의 아이디어.
우선 2D latent grid를 기존 에서 등으로 바꾸어 16:9의 video 화면 비율에 맞춰준 뒤 학습을 시도해보고 싶었지만 모델에서 latent grid를 선언하고 latent vector로 encoding하는 코드를 cuda_nn을 그대로 가져다 사용하는 바람에 손을 쓰기가 어려웠다.
아쉬운 대로 3D latent grid를 기존 에서 으로 바꾸어 학습시켰더니 결과는 아래와 같았다.
| Data Type | Resized | mini-NVP (Default) |
|---|---|---|
| Encoding duration (1,000 epoch) | 1:49:17 | 1:46:01 |
| Decoding duration | 01:50 | 01:19 |
| psnr | 30.32 | 30.63 |
| bpp | 0.680 | 0.735 |
| psnr(w/ codec compression) | 27.24 | 27.84 |
| bpp(w/ codec compression) | 0.231 | 0.259 |
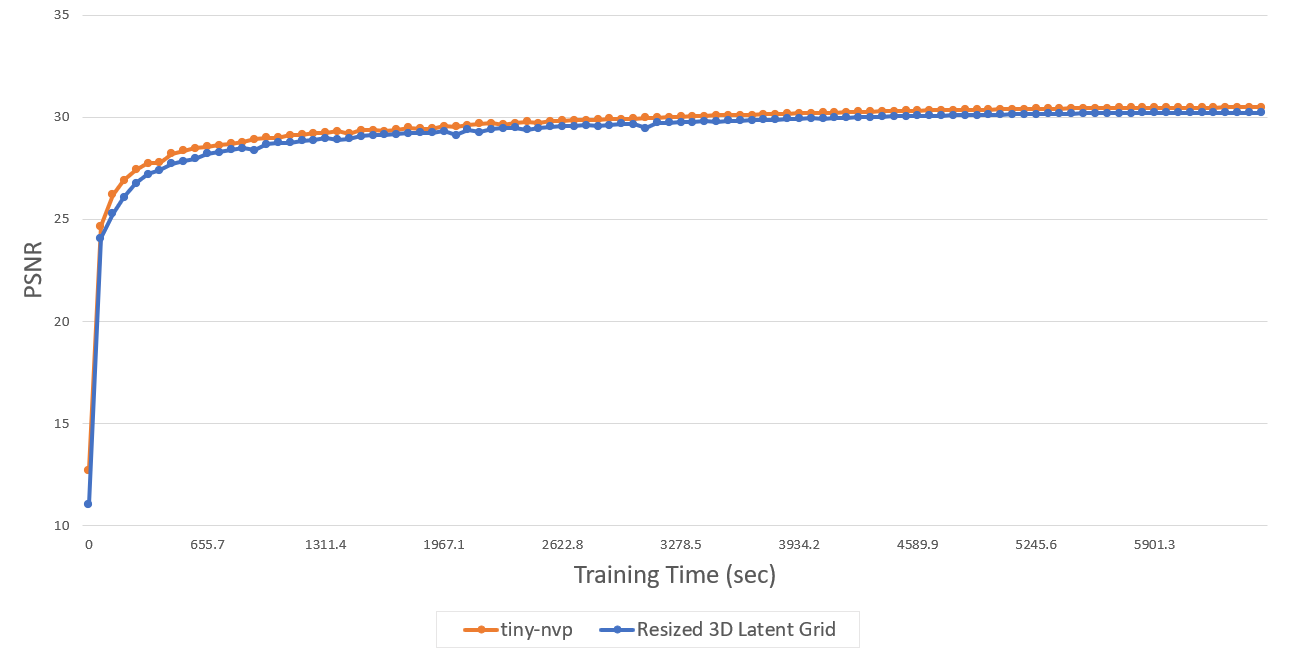
아쉽게도 별다른 성능향상이 나타나진 않았다. 3D latent grid에 대한 resizing이 모델 전체에 미치는 영향이 적은 것 같다.
2. Frame-wise representation의 학습 방식을 접목시켜 기존 1,245,184개의 random points의 batch 단위로 학습시키던 것에서 frame 단위로 입력해준다면 더 빠른 수렴속도를 기대해볼 수 있지 않을까? + Frame-wise representation 논문에서 주로 사용되는 L1+SSIM loss도 사용해보자!
Dataset이 frame 단위로 입력된다면 spatial axis에 대한 정보를 더 빠르게 학습하여 encoding 속도가 향상되지 않을까라는 가설로 세운 아이디어.
학습의 효율성을 위해, 인접한 5개의 frame를 하나의 batch로 설정하여 학습을 진행하였다.
(ex. epoch 1: pixels in 1st~5th frames / epoch 2: pixels in 2nd~6th frames)
따라서 기존엔 1,245,184개의 data point가 batch를 구성해 입력된 것에 비해 수정 후엔 =1,152,000개의 data point가 입력된다.
또한 SSIM+L1 loss로 loss function을 수정하고도 학습을 진행해보았고, 모든 결과는 아래와 같았다.
| Data Type | Frame-wise | +SSIM Loss | mini-NVP (Default) |
|---|---|---|---|
| Encoding duration (1,000 epoch) | 1:19:18 | 1:22:33 | 1:46:01 |
| Decoding duration | 01:39 | 01:46 | 01:19 |
| psnr | 26.91 | 26.27 | 30.63 |
| bpp | 0.735 | 0.735 | 0.735 |
| psnr (w/ codec compression) | 26.70 | 26.11 | 27.84 |
| bpp (w/ codec compression) | 0.174 | 0.189 | 0.259 |
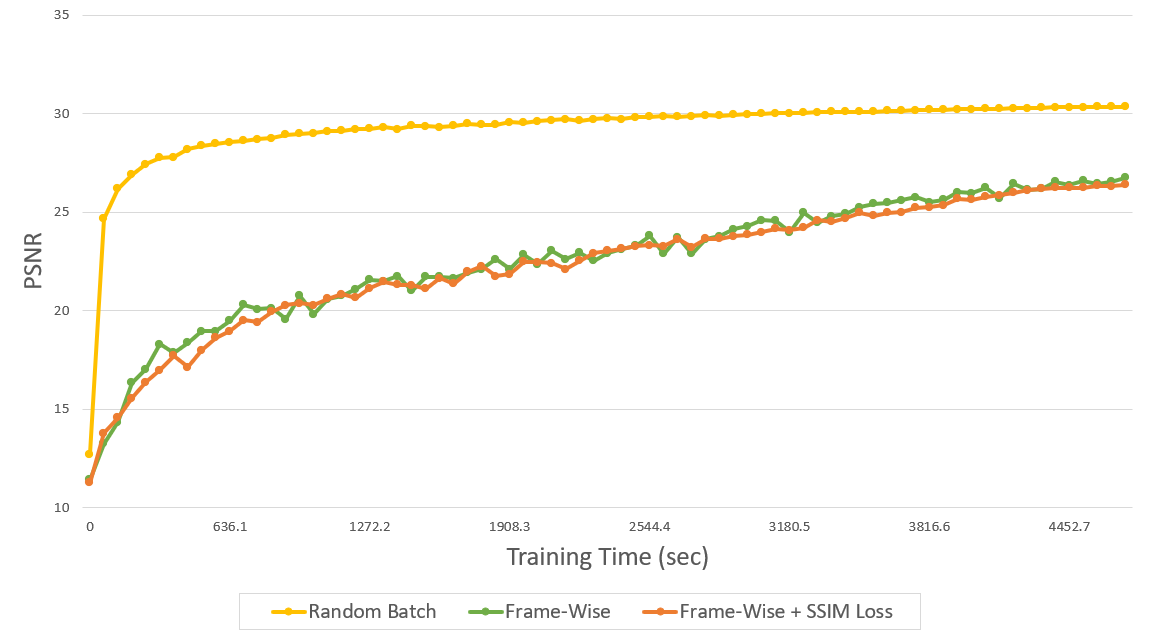
Codec compression 이후의 bpp score 측면에선 유의미한 이점을 보였으나 학습 속도가 오히려 느려졌다. 이는 cross-temporal axis에 대해선 하나의 frame이 다뤄지는 동안 동일한 data가 반복되어 입력되기 때문에 효율이 떨어진 것으로 보인다.
또한, SSIM loss를 적용해보아도 기존의 L2 loss를 사용했을 때에 비해 frame-wise dataset feeding의 이점을 극대화하지는 못하는 모습을 보였다.
3. 2D latent grid를 크게 하나만 정의해두고 latent vector는 해당 grid의 latent code를 선택적으로 사용하여 구한다면 multi-layer로 구성하지 않아도 되지 않을까? 가장 dense하게는 모든 latent code를 사용하고, 그 다음엔 의 grid만, 그 다음은 의 grid만 사용하는 식으로 말이다. 성능이 많이 떨어지려나..?
이 아이디어는 직접 구현하기를 포기했다.. 이유인 즉슨, 본 논문에서도 기존의 cuda_nn 코드를 사용했는데, C++로 구현된 대형 코드라 쉽사리 고치기가 어렵다...
+ 현재 기존의 codec보다 높은 압축 성능을 보이고 있는 FFNeRV에서 제시한 flow-guided frame aggregation을 NVP에 적용해볼 수도 있을 것 같은데 굳이 pixel-wise presentation에 적용하기에는 구조적 한계점이 명확해 보인다.
