앞선 'NVP2(1) - Ideas proposal on sparse positional features' 글에서 나열한 아이디어를 하나씩 살펴보며 구현 및 실험해보도록 한다.
1. Codec/Tucker-Guided Training
학습과정 중간중간마다 sparse positional features를 codec으로 압축시키고 불러오길 반복하며 학습의 효율과 최종 성능을 측정해 보기! + Tucker decomposition도 마찬가지로 시도해보기.
모델의 학습 과정에서부터 codec compression 혹은 Tucker decomposition의 후처리를 거칠 것이란 전제를 두어 그에 맞게 학습되도록 유도해보려는 시도이다.
우선 기존 144,700번의 epoch로 학습을 시킨 baseline 모델을 성능의 기준점으로 삼는다. 그리고 새로운 모델에 대해, 5,000번의 epoch 단위로 학습을 끊어 그 사이사이마다 parameter를 압축하고 다시 불러오기를 반복하며 parameter가 압축에 적합한 분포로 학습되기를 유도한다. (model_final.pth 파일로 parameter 저장, quantize 및 codec compression, compressed mp4/jpg 파일로부터 model에 parameter load.) 단, 임의의 이미지 및 동영상을 압축한 뒤 불러왔을 때의 일부 손실된 형태는 원본에 비해 압축에 용이한 형태라는 전제를 두도록 한다.
이 때 주의깊게 살펴봐야 할 정보는 학습 과정에서의 loss 값의 추이보단 학습 완료 후 모델 압축까지 진행하였을 때 성능 차이이다. 동일한 epoch로 학습을 시켰을 때, 압축에 대한 guidance를 주었을 때와 그렇지 않은 경우의 성능을 비교해보았다.
*코드 실행의 반복을 notebook 파일로 만들어 돌릴 예정이었지만 codec compression의 경우 'AssertionError: Cannot find installation of real FFmpeg (which comse with ffprobe).' 에러가 반복하여 발생하여 포기.. 반복 단위를 10,000 epoch로 늘려 parameter를 압축하여 불러오기를 14번만 반복하였다. Tucker decomposition의 경우, notebook 파일로 5,000 epoch 단위로 반복 실행하였으며, 그 코드는 아래와 같다.
max_idx = 144700//5000
for compress_idx in range(max_idx):
print(f"== Tucker Decomposition Epoch [{compress_idx+1}] ==")
!CUDA_VISIBLE_DEVICES=1 python experiment_scripts/train_tucker.py --logging_root ./logs_nvp --experiment_name nvp_tucker_guide --dataset ./data/Jockey_rgb --num_frames 600 --config ./config/config_nvp_s.json
last_epoch = 144700%5000
print(f"== The Last Epoch ==")
!CUDA_VISIBLE_DEVICES=1 python experiment_scripts/train_tucker.py --logging_root ./logs_nvp --experiment_name nvp_tucker_guide --num_epochs last_epoch --steps_til_summary 100 --dataset ./data/Jockey_rgb --num_frames 600 --config ./config/config_nvp_s.json
두 압축 방법 각각에 대해 144,700 epoch의 학습을 모두 마친 후 training epoch에 따른 loss plot과 모델의 최종 성능은 다음과 같았다.
우선 codec-friendly training. 144,700 epoch의 학습을 10,000번 단위로 끊어, 학습 과정 중 모델 파라미터에 대해 총 14번의 codec compression/decompression을 수행하였다. 그에 따른 학습 과정에서의 loss 값은 아래와 같았다.
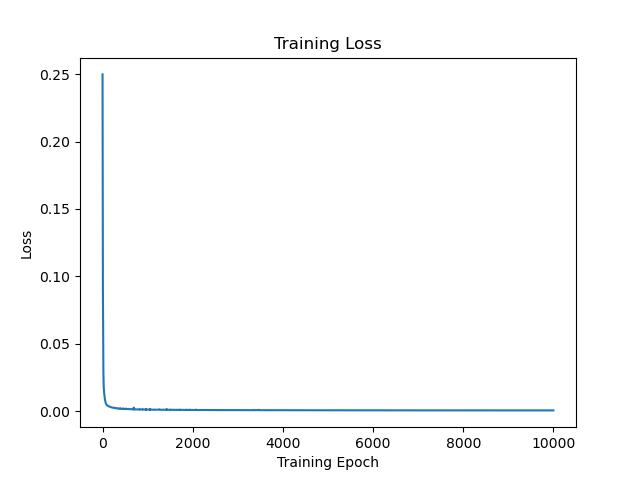
사실 codec compression에 의한 정보의 손실량은 크지 않아 loss 값의 추이엔 큰 변화가 발생하지 않았다.
한편, 학습 과정에서의 모델이 보이는 PSNR 값의 경우, 아래와 같이 파라미터를 압축하고 불러올 때마다 성능이 소폭 하락하였다가 다시 상승하는 모습을 반복하였다. 이를 통해 파라미터를 압축하는 주기를 조절해볼 수도 있을 것 같다.
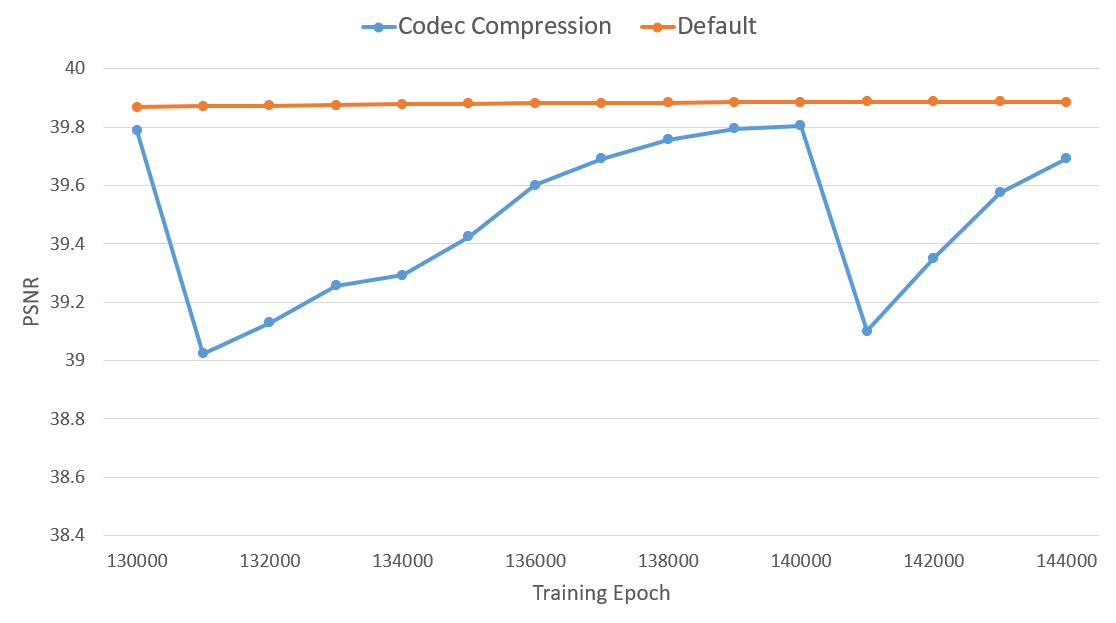
이와 같이 학습된 codec-guided 모델의 최종 파라미터를 다시 압축하여 evaluation을 진행하였더니 아래와 같은 성능을 확인할 수 있었다.
[Codec Compression]
hevc w/o guidance: BPP - 0.1782 / PSNR - 37.01
hevc w/ guidance: BPP - 0.1472 / PSNR - 37.76
흥미롭게도, BPP값은 약 17% 감소한 반면, PSNR 값은 0.75만큼 상승하였음을 확인할 수 있었다. Codec에 대한 guidance가 모델의 성능에 유의미한 영향을 미친 것이다!
한편, Tucker decomposition-guided training의 경우, 우선 지난 실험에 따르면 각 rank 값에 따른 bpp-psnr의 값은 아래와 같았다.
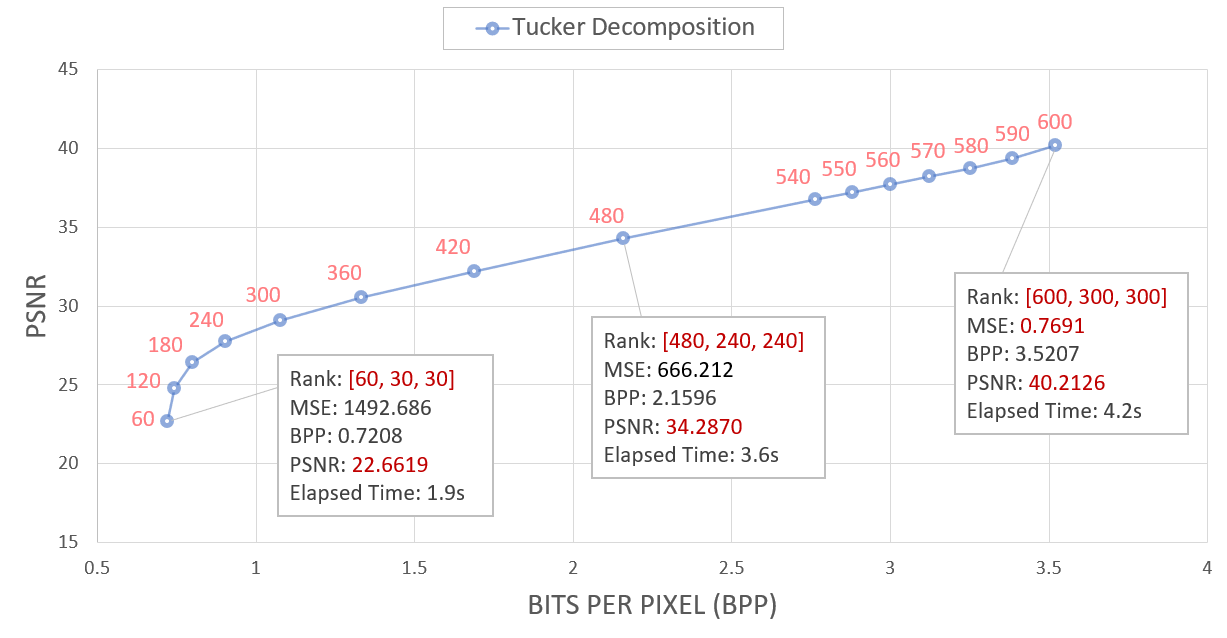
이들 중 중간값인 [480, 240, 240] rank 값에 대해 실험을 진행하였으며, 144,700 epoch의 학습을 5,000번 단위로 끊어, 학습 과정 중 모델 파라미터에 대해 총 28번의 tensor decomposition/composition을 수행하였다. 그에 따른 loss 값은 아래와 같았다.
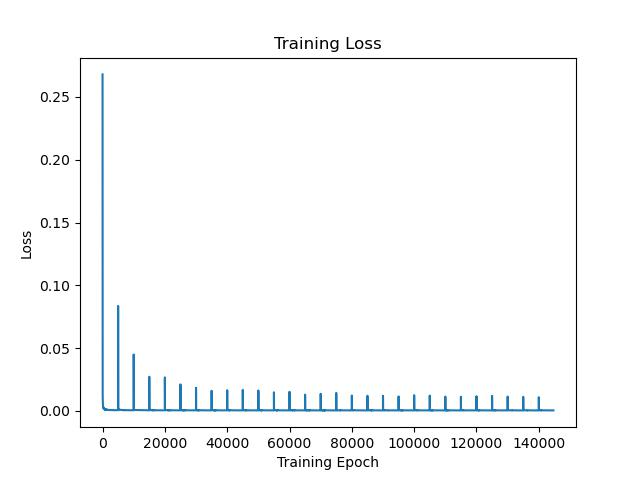
Tucker decomposition을 수행해줄 때마다 loss 값이 크게 증가하였으나, 그 폭이 학습이 진행될수록 점차 줄어들었으며, Tucker decomposition을 적용하였을 때 손실되는 정보량이 점차 줄어들었음을 유추해볼 수 있다.
또한 학습 과정에서 모델에 대한 PSNR 값의 추이를 살펴보면, 마찬가지로 파라미터를 분해하고 합성할 때마다 성능이 소폭 떨어졌다가 다시 회복하기를 반복하는 모습을 확인할 수 있다.
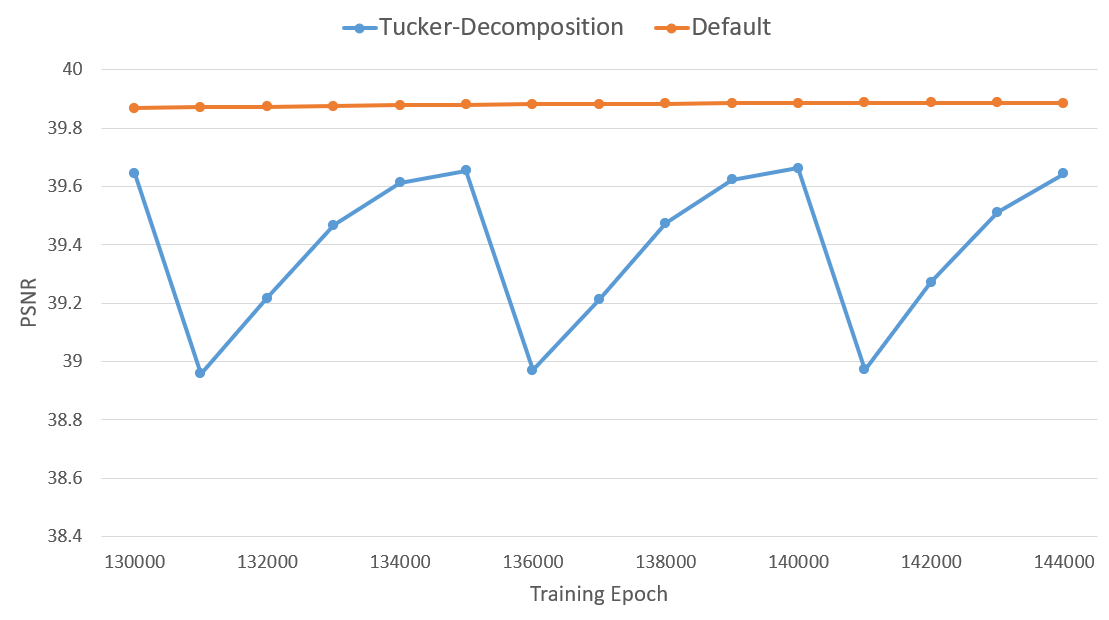
해당 모델에 다시 Tucker decomposition을 적용한 뒤 evaluation을 진행하였더니 아래와 같은 성능을 확인할 수 있었다.
[Tucker Decomposition / Rank: [480, 240, 240]]
Tucker w/o guidance: BPP - 2.1596 / PSNR - 34.2870
Tucker w/ guidance: BPP - 2.1596 / PSNR - 36.4583
학습 과정에서 Tucker decomposition에 대한 guidance가 주어지지 않은 경우에 비해 2.2 정도의 괄목할만한 PSNR 값의 향상을 보여주었다! 역시나 유의미한 결과이다.
2. Tucker Decomposition-Based Initialization
원본 영상에 Tucker decomposition을 적용한 결과로 각 latent grid를 initialize한 뒤 학습 추이 살펴보기!
Tucker decomposition을 적용해 나온 1개의 3D tensor와 3개의 2D tensor를 각각 3D latent grid와 2D latent grid의 초깃값으로 두어 학습 속도를 비교해볼 수 있을 것이다. 또한, 학습 완료 후 Tucker decomposition으로 후처리를 진행한다는 전제 하에, 초깃값과의 차이를 고려한 loss term을 두어 학습 자체부터 Tucker decomposition을 염두에 둔 방향으로 진행되도록 유도해볼 수 있을 것이다.
