
NoSQL Database
:관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소
데이터를 행과 열이 아닌, 체계적인 방식으로 저장함
MongoDB (NoSQL 도큐먼트 데이터베이스)
NoSQL: 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소
1. 비구조적인 대용량의 데이터를 저장하는 경우
: 자유로운 형태로 데이터를 저장할 수 있으므로 필요에 따라서 새로운 데이터 유형을 추가할 수 있음
2. 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
: 데이터베이스를 클라우드 기반으로 쉽게 분리할 수 있도록 지원하여, 저장 공간을 효율적으로 사용함
시스템이 커져 DB를 증설해야 하는 경우 수평적 확장의 형태로 증설하므로, 무한대로 서버를 계속 분산시킬 수 있음(<-> SQL는 수직적 확장)
3. 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
: 스키마를 미리 준비할 필요가 없어서, 개발을 빠르게 해야하는 경우에 매우 적합함
Atlas Cloud
- GUI와 CLI로 데이터를 시각화, 분석, 내보내기, 빌드하는 데에 사용할 수 있음
- 아틀라스 사용자는 클러스터를 배포할 수 있으며, 클러스터는 그룹화된 서버에 데이터를 저장함
- 서버는 레플리카 세트로 구성되어 있으며, 레플리카 세트는 동일한 데이터를 저장하는 몇 개의 연결된 MongoDB 인스턴스의 모음임
(인스턴스: 특정 소프트웨어를 실행하는 로컬 또는 클라우드의 단일 머신, 이경우에선 인스턴스는 클라우드에서 실행되는 MongoDB 데이터베이스) - 도큐먼드나 컬렉션을 변경할 경우, 변경된 데이터의 중복 사본이 레플리카 세트에 저장됨
- 레플리카 세트의 인스턴스 중 하나에 문제가 발생하더라도 데이터는 그대로 유지되며, 레플리카 세트의 애플리케이션에서 나머지 작업을 할 수 있음
(이 과정을 위해 클러스터를 배포하면, 자동으로 레플리카 세트가 구성됨)
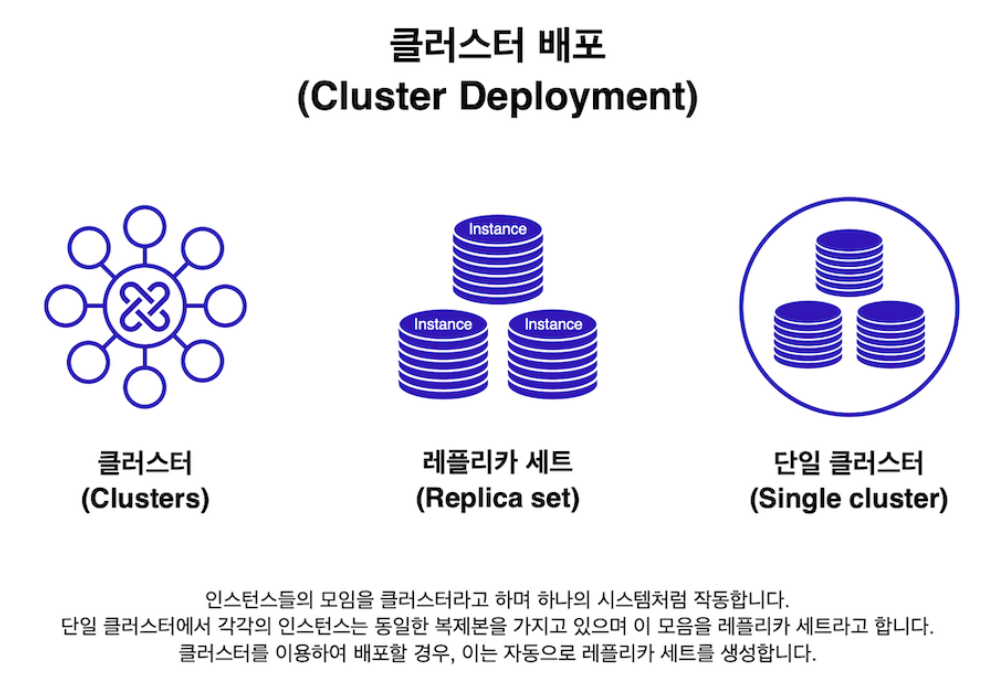
레플리카 세트
: 동일한 데이터를 저장하는 소수의 연결된 머신을 뜻함
레플리카 세트 중 하나에 문제가 발생하더라도, 데이터를 그대로 유지할 수 있음
인스턴스
: 로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스
클러스터
: 데이터를 저장하는 서버 그룹으로 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 단일 컴퓨터처럼 동작하도록 제작한 컴퓨터를 뜻함
Importing & Exporting
Export
mongodump --uri "<Atlas Cluster URI>"
mongoexport --uri "<Atlas Cluster URI>"
--collection=<collection name>
--out=<filename>.jsonImport
mongorestore --uri "<Atlas Cluster URI>"
--drop dump
mongoimport --uri "<Atlas Cluster URI>"
--drop=<filename>.json
MongoDB CRUD
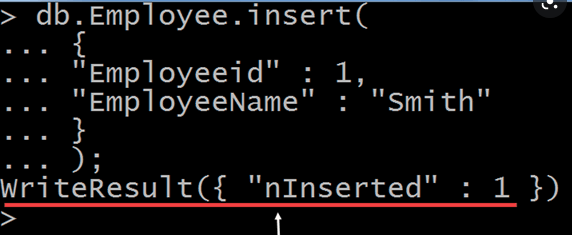
CREATE - insert 명령어
모든 도큐먼트는 고유한 id 값을 가지고 있어야 함
(id값은 보통 ObjectId(12 byte, 24 char))
- 주어진 도큐먼트 배열의 인덱스 순서로 작업이 실행됨
- ordered를 추가하면, 순서와 상관없이 고유한 id를 가진 도큐먼트는 모두 컬렉션에 삽입됨
READ - find 명령어
- show dbs: 데이터베이스 리스트 확인
- use : 데이터베이스 사용
- show collections: 데이터베이스 안의 컬렉션 리스트 확인
- db.collectionname.find(<쿼리문>): 특정 데이터 찾기
ex: db.zips.find({“state” : “NY”, “city” : “ALBANY”})
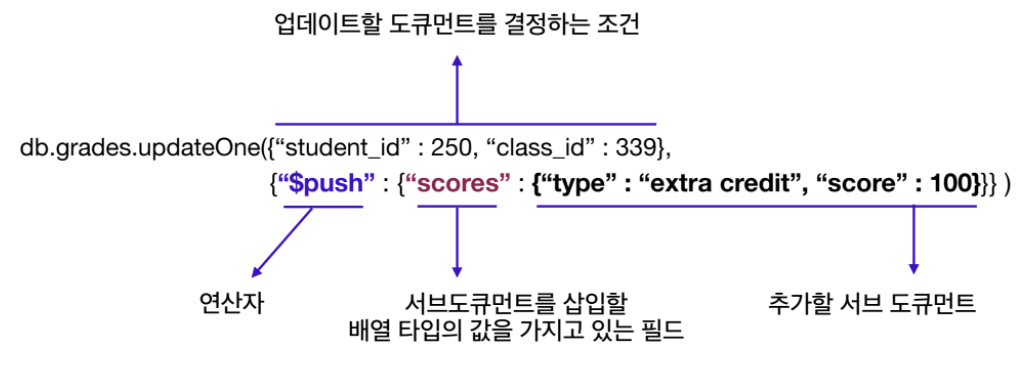
UPDATE
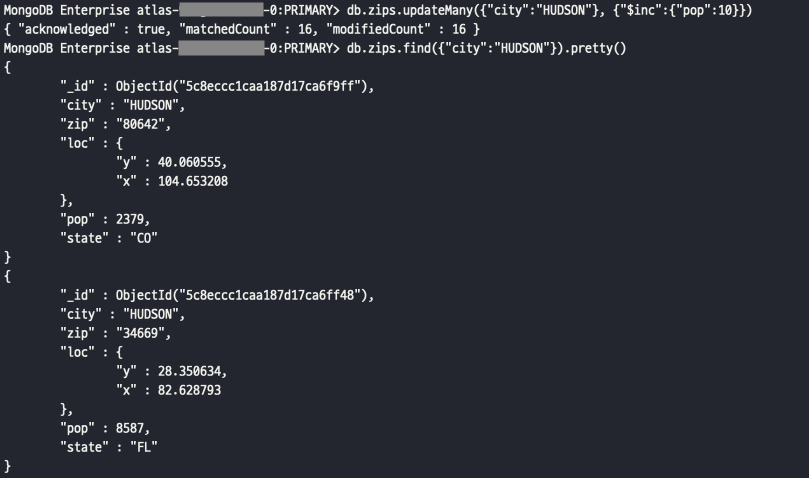
- updateOne: 주어진 기준에 맞는 다수의 도큐먼트 중 첫번째 도큐먼트 하나만 업데이트
- updateMany: 쿼리문과 일치하는 모든 도큐먼트를 업데이트
- $inc 연산자
- set 연산자 {"set" : {"<객체 키>" : <객체 값>}}
- $push
DELETE
- deleteOne: 주어진 기준에 맞는 다수의 도큐먼트 중 첫번째 도큐먼트 하나를 삭제
- deleteMany: 쿼리문과 일치하는 모든 도큐먼트를 삭제
- db.collection_name.drop(): 컬렉션을 삭제
Advanced CRUD
비교 연산자 (특정한 범위 내의 데이터를 찾을 때)
-
$eq는 연산자가 지정되어 있지 않은 경우에 기본 연산자로 사용됨
$eq = equal to $ne = not equal to $gt = greater than $lt = less than $gte = greater than or equal to $lte = less than or equal to 형식 === {<field>:{<operator>:<value>}}
논리 연산자
$and: 주어진 모든 쿼리절과 일치하는가
(연산자가 지정되지 않았을 때, 기본 연산자로 사용)
$or: 주어진 쿼리절 하나라도 일치하는가
$nor: 주어진 모든 쿼리절과 일치하지 않는가
$not: 주어진 쿼리와 일치하지 않는가표현 연산자 (같은 도큐먼트 내의 필드들을 서로 비교할 때)
- {$expr: {<"expression">}}
- $expr (필드값) 를 이용해 변수와 조건문을 사용할 수 있음
{"$expr" :{
"$and": [
{"$gt" :["$tripduration", 1200]},
{"$eq": ["$end station id", "$start station id]}
]
}배열 연산자
$push: 배열의 마지막 위치에 엘리먼트를 넣음
(배열이 아닌 필드에 사용했을 경우, 필드의 타입을 배열로 바꿈)
$all: 배열 요소의 순서와 상관없이 지정한 요소가 있는 모든 도큐먼트를 반환projection (수많은 데이터에서 현재 관심 있는 필드만 가져오고 싶을 때)
db.<collection>.find({<query>},{<projection>})
projection 사용시에는 1 또는 0만 사용하여 작성
<field>:1 -> 지정한 필드를 포함
<field>:0 -> 지정한 필드를 제외
ex) db.<collection>.find({<query>},{<field 1>:1, <field 2>: 1})- $elemMatch: 지정한 배열 필드가 도큐먼트에 존재하고 조건에 맞는 요소가 있는 경우에만 해당 필드를 결과에 포함시킴
{<field>:{"$elemMatch":{<field>:<value>}}}
- 첫번째 인자에서 쓰일 경우: 배열 필드의 서브 도큐먼트 필드가 쿼리와 일치하는 문서를 찾음
- 두번째 인자에서 쓰일 경우: 지정된 기준과 일치하는 요소가 하나 이상있는 배열 요소만 찾음Aggregation Framework (MongoDB에서 데이터를 쿼리하는 가장 간단한 방법)
Aggregation Framework에서는 find 기능을 사용하고 싶을 때 aggregate 명령을 사용함
db.listingsAndReviews.find(
QUERY --> {"amenities":"wifi"},
PROJECTION --> {"price": 1, "address":1, "_id:0}).pretty()
db.listingsAndReviews.aggregate([
QUERY --> {$match:{"amenities": "wifi"}},
PROJECTION --> {$project:{"price": 1, "address":1, "_id":0}} ]).pretty()-
도큐먼트를 필터링 하지 않고 그룹으로 데이터를 집계하거나 데이터를 수정할 수 있음
-
데이터 찾기 및 프로젝션 없이 작업을 수행하거나 계산할 수 있음
-
대괄호를 이용해 배열을 인자로 사용함 (배열 요소의 순서대로 작업 진행)
-Aggregation 파이프 라인의 데이터는 파이프 라인 내에 있기 때문에 본질적으로 원본 데이터를 수정하거나 변경하지 않음$group
:들어온 데이터 스트림을 여러개로 그룹화하는 연산자{$group: { _id:<expression>, <field 1>:{<accumulator 1>:<expression 1>},...}} db.listingsAndReviews.aggregate([ {$project:{"address":1, "_id":0}}, {$group:{_id: "$address.country", "count":{"$sum": 1}}} ])
Index
createIndex(): 인덱스 생성 (오름차순: 1, 내림차순: -1)
db.collection_name.createIndex({<필드명>:1, <속성 property>: true})- Unique: _id필드와 같이 컬렉션에 단 한 개의 값만 존재할 수 있는 속성
- Partial: 도큐먼트의 조건을 정해 일부 도큐먼트에만 인덱스를 적용
- TTL(Time-To-Live): date 타입 혹은 date 배열 타입의 필드에 적용가능함
이 속성을 사용하면 특정시간이 지난 후, 도큐먼트를 컬렉션에서 삭제함
getIndexes: 생성된 인덱스를 조회함
db.collection_name.getIndexes()dropIndex: 생성된 인덱스를 삭제함
db.collection_name.dropIndex(name)