input 함수
print 함수
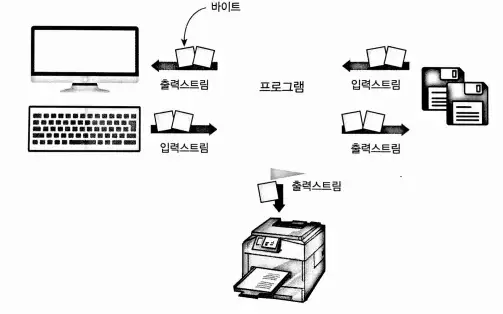
1. 파일입출력
자료형에 있음
1. 데이터 입력
2. 데이터 출력
3. format()와 형식문자
2. 텍스트 파일
링크:텍스트파일
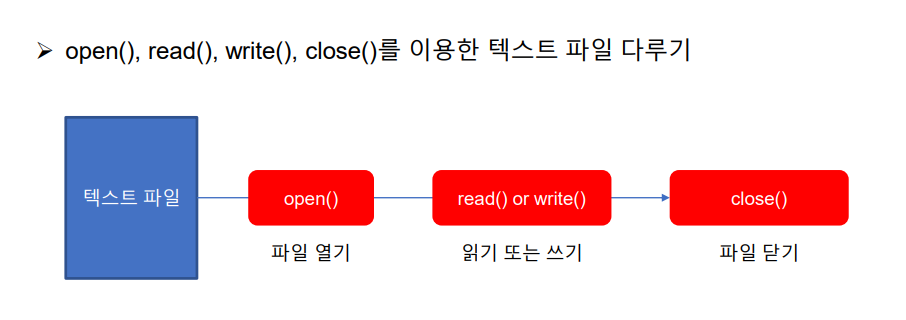
1. 텍스트 파일 쓰기
텍스트 파일을 파이썬으로 다뤄보자!
기본 함수
파일 쓰기
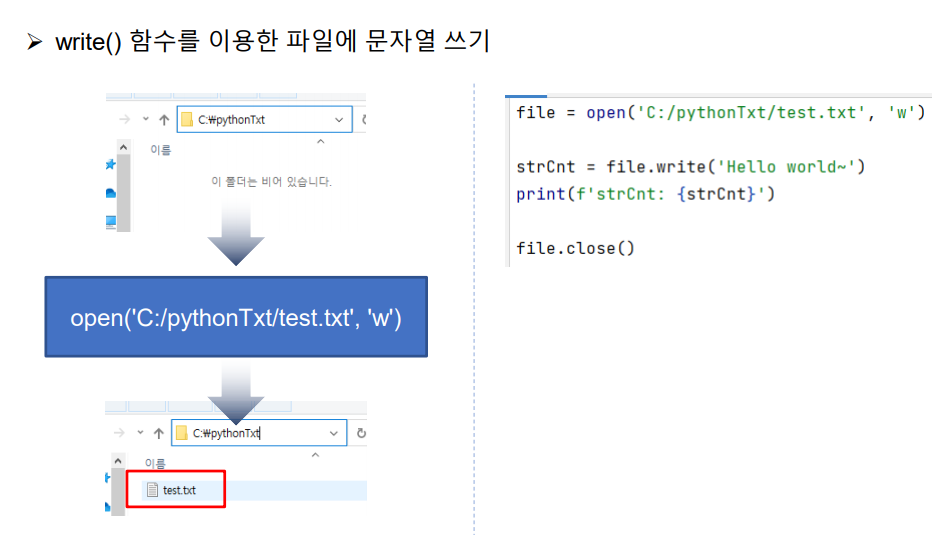
file = open('C:/pythonTxt/test.txt', 'w')
strCnt = file.write('Hello world~')
print(f'strCnt: {strCnt}')
file.close()
file = open('C:/pythonTxt/test.txt', 'w')
strCnt = file.write('Hello python~')
print(f'strCnt: {strCnt}')
file.close()실습
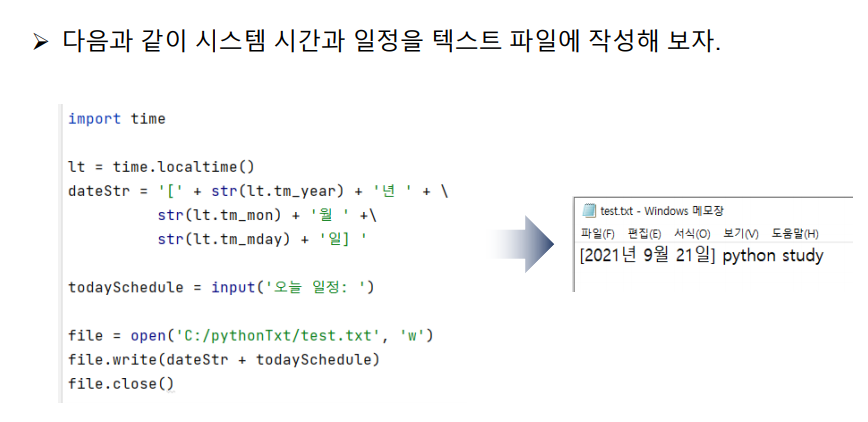
import time
lt = time.localtime()
dateStr = '[' + str(lt.tm_year) + '년 ' + \
str(lt.tm_mon) + '월 ' +\
str(lt.tm_mday) + '일] '
todaySchedule = input('오늘 일정: ')
file = open('C:/pythonTxt/test.txt', 'w')
file.write(dateStr + todaySchedule)
file.close()
#2
import time
lt = time.localtime()
# dateStr = time.strftime('%Y-%m-%d %H:%M:%S %p', lt)
dateStr = '[' + time.strftime('%Y-%m-%d %I:%M:%S %p', lt) + '] '
todaySchedule = input('오늘 일정: ')
file = open('C:/pythonTxt/test.txt', 'w')
file.write(dateStr + todaySchedule)
file.close()
2. 텍스트 파일 읽기
텍스트 파일의 텍스트를 읽어보자!
파일 읽기
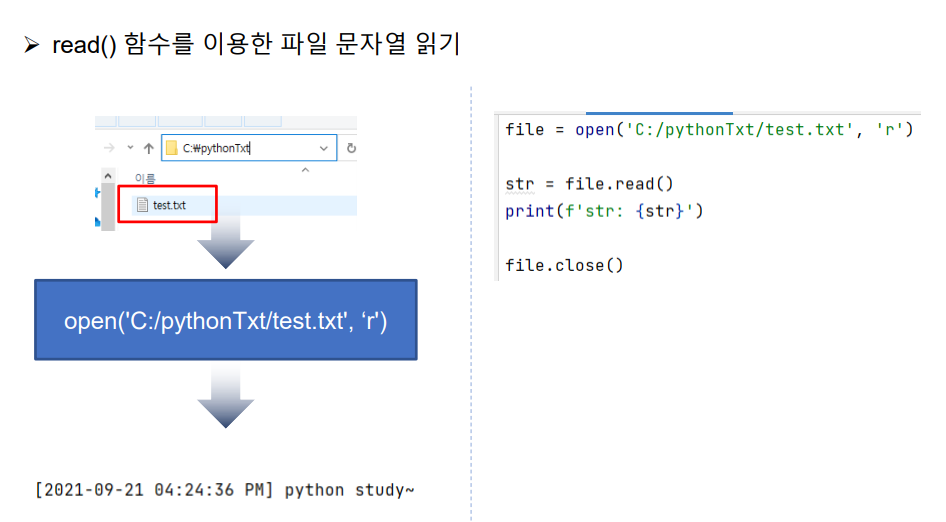
file = open('C:/pythonTxt/test.txt', 'r')
str = file.read()
print(f'str: {str}')
file.close()
실습

file = open('C:/pythonTxt/about_python.txt', 'r')
str = file.read()
print(f'str: {str}')
file.close()
# str = str.replace('Python', '파이썬')
str = str.replace('Python', '파이썬', 2)
print(f'str: {str}')
file = open('C:/pythonTxt/about_python.txt', 'w')
strCnt = file.write(str)
file.close()
3. 텍스트 파일 열기
파일을 다양한 방식으로 open할 수 있다.
파일 모드

uri = 'C:/pythonTxt/'
# 'w' 파일 모드
file = open(uri + 'hello.txt', 'w')
strCnt = file.write('Hello world!!')
print(f'strCnt: {strCnt}')
file.close()
file = open(uri + 'hello.txt', 'w')
strCnt = file.write('Hello Python!!')
print(f'strCnt: {strCnt}')
file.close()
# 'a' 파일 모드
file = open(uri + 'hello.txt', 'a')
file.write('\n')
file.write('Hello data science!!')
file.close()
# 'x' 파일 모드
file = open(uri + 'hello.txt', 'x')
file.write('Nice to meet you!!')
file.close()
# 'r' 파일 모드
file = open(uri + 'hello.txt', 'r')
str = file.read()
print(f'str: {str}')
file.close()
실습
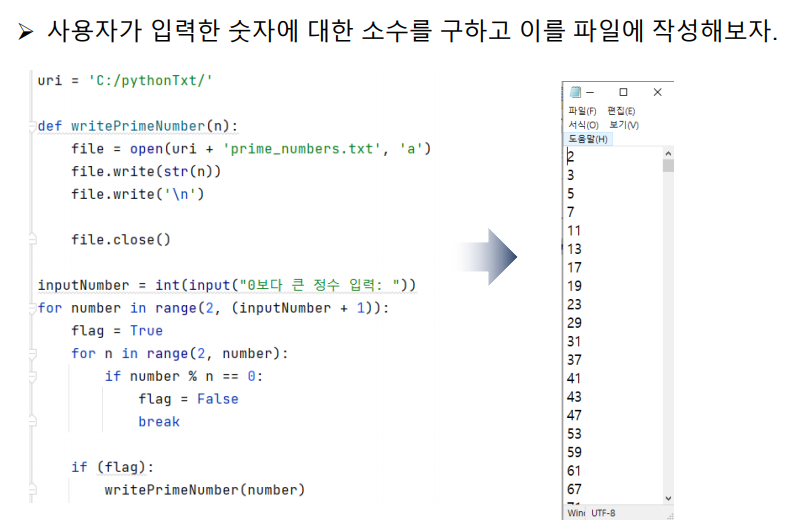
uri = 'C:/pythonTxt/'
def writePrimeNumber(n):
file = open(uri + 'prime_numbers.txt', 'a')
file.write(str(n))
file.write('\n')
file.close()
inputNumber = int(input("0보다 큰 정수 입력: "))
for number in range(2, (inputNumber + 1)):
flag = True
for n in range(2, number):
if number % n == 0:
flag = False
break
if (flag):
writePrimeNumber(number)
4. with ~ as문
파일 닫기(close)를 생략하자!

uri = 'C:/pythonTxt/'
file = open(uri + '5_037.txt', 'a')
file.write('python study!!')
file.close()
file = open(uri + '5_037.txt', 'r')
print(file.read())
file.close()
with open(uri + '5_037.txt', 'a') as f:
f.write('python study!!')
with open(uri + '5_037.txt', 'r') as f:
print(f.read())
실습

import random
uri = 'C:/pythonTxt/'
def writeNumbers(nums):
for idx, num in enumerate(nums):
with open(uri + 'lotto.txt', 'a') as f:
if idx < (len(nums) - 2):
f.write(str(num) + ', ')
elif idx == (len(nums) - 2):
f.write(str(num))
elif idx == (len(nums) - 1):
f.write('\n')
f.write('bonus: ' + str(num))
f.write('\n')
rNums = random.sample(range(1, 46), 7)
print(f'rNums: {rNums}')
writeNumbers(rNums)5. writelines()
반복 가능한 자료형의 데이터를 파일에 쓰자!
writelines()
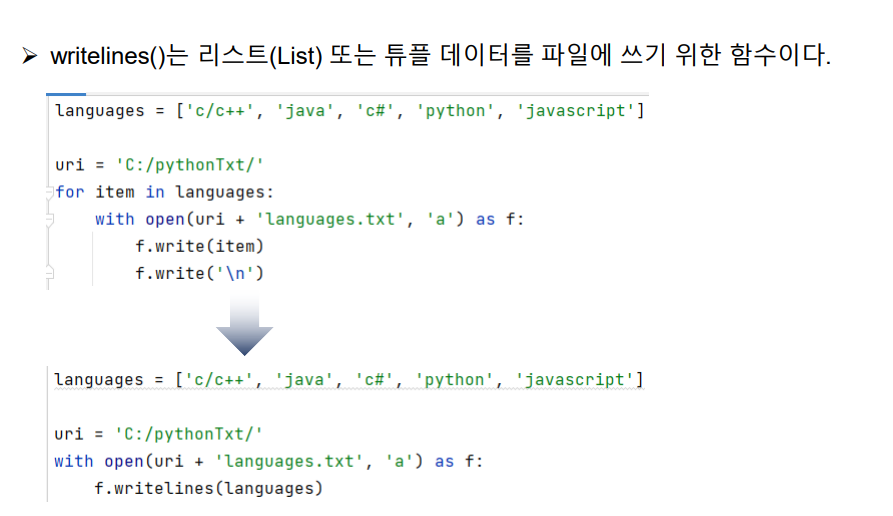
languages = ['c/c++', 'java', 'c#', 'python', 'javascript']
uri = 'C:/pythonTxt/'
for item in languages:
with open(uri + 'languages.txt', 'a') as f:
f.write(item)
f.write('\n')
languages = ('c/c++', 'java', 'c#', 'python', 'javascript')
uri = 'C:/pythonTxt/'
with open(uri + 'languages.txt', 'a') as f:
# f.writelines(languages)
f.writelines(item + '\n' for item in languages)실습
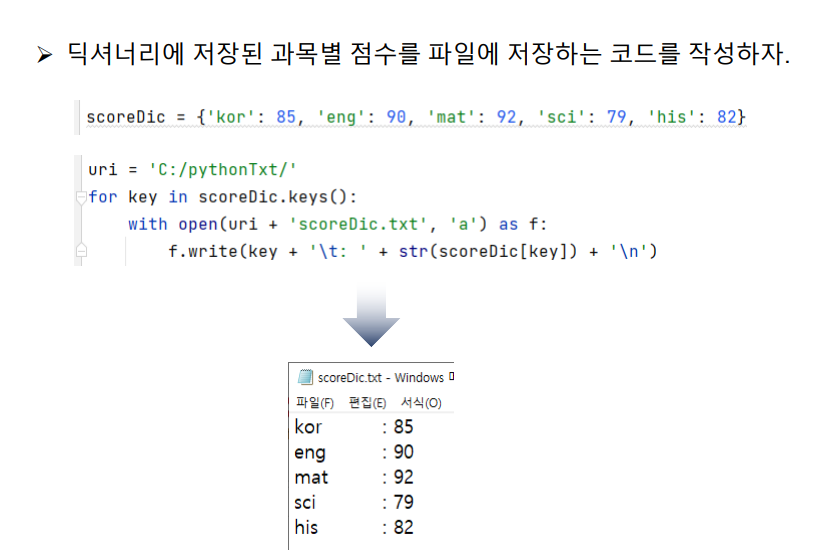
scoreDic = {'kor': 85, 'eng': 90, 'mat': 92, 'sci': 79, 'his': 82}
uri = 'C:/pythonTxt/'
for key in scoreDic.keys():
with open(uri + 'scoreDic.txt', 'a') as f:
f.write(key + '\t: ' + str(scoreDic[key]) + '\n')
dic = {'s1':90, 's2':85, 's3': 95}
list = [90, 85, 95]
uri = 'C:/pythonTxt/'
with open(uri + 'scores.txt', 'a') as f:
print(dic, file=f)
6. readlines(), readline()
여러줄 읽기와 한줄 읽기
readlines()
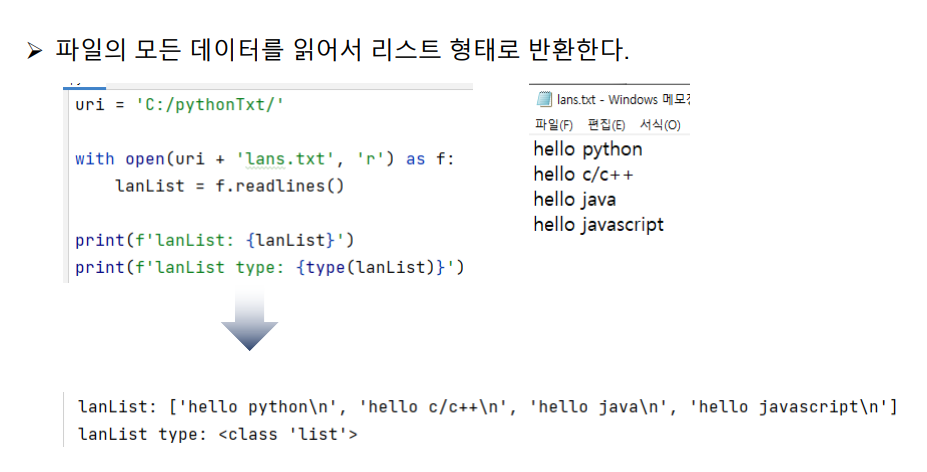
uri = 'C:/pythonTxt/'
with open(uri + 'lans.txt', 'r') as f:
lanList = f.readlines()
print(f'lanList: {lanList}')
print(f'lanList type: {type(lanList)}')readline()
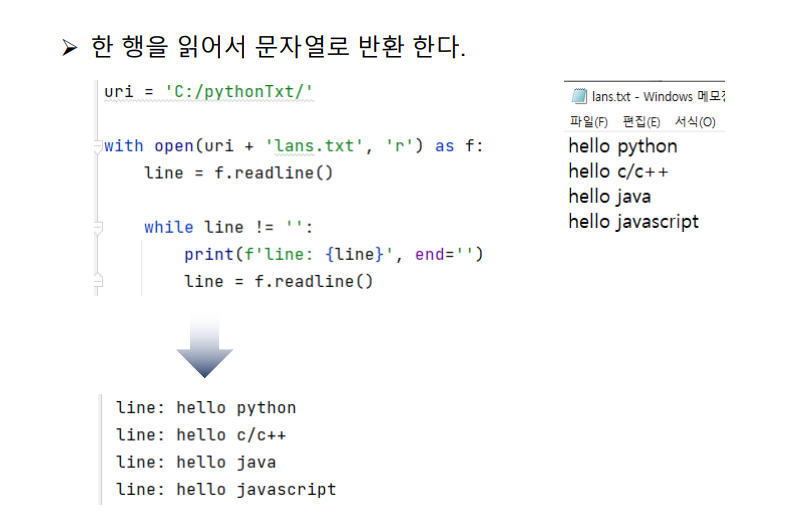
uri = 'C:/pythonTxt/'
with open(uri + 'lans.txt', 'r') as f:
line = f.readline()
while line != '':
print(f'line: {line}', end='')
line = f.readline()실습

scoreDic = {}
uri = 'C:/pythonTxt/'
with open(uri + 'scores.txt', 'r') as f:
line = f.readline()
while line != '':
tempList = line.split(':')
scoreDic[tempList[0]] = int(tempList[1].strip('\n'))
line = f.readline()
print(f'scoreDic: {scoreDic}')# 파일을 엽니다.
file = open("basic.txt", "w")
# 파일에 텍스트를 씁니다.
file.write("Hello Python Programming...!")
# 파일을 닫습니다.
file.close()# 파일을 엽니다.
with open("basic.txt", "r") as file:
# 파일을 읽고 출력합니다.
contents = file.read()
print(contents)with open("info.txt", "r") as file:
for line in file:
# 변수를 선언합니다.
(name, weight, height) = line.strip().split(", ")
# 데이터가 문제없는지 확인합니다: 문제가 있으면 지나감
if (not name) or (not weight) or (not height):
continue
# 결과를 계산합니다.
bmi = int(weight) / ((int(height) / 100) **2)
result = ""
if 25 <= bmi:
result = "과체중"
elif 18.5 <= bmi:
result = "정상 체중"
else:
result = "저체중"
# 출력합니다.
print('\n'.join([
"이름: {}",
"몸무게: {}",
"키: {}",
"BMI: {}",
"결과: {}"
]).format(name, weight, height, bmi, result))
print()
1.텍스트파일
2. 인코딩

<참고사이트>
https://jjeong.tistory.com/696
https://www.urldecoder.org/
https://onlywis.tistory.com/2
https://jeongdowon.medium.com/unicode와-utf-8-간단히-이해하기-b6aa3f7edf96
https://lovefor-you.tistory.com/173
https://dojang.io/mod/page/view.php?id=2462 바이트 어레이, 바이트 코드
글자로 읽을 경우, decode utf-8 설정 : 사람이 읽기 편한(한국어) 글자로 변환(utf8로 디코딩)
response 위코드
response.read()
response_body response.read()했을 때 내용(byte array형식)이 response_body에 담겨있음
print(response_body.decode("utf-8"))
인코딩(encoding): 정보를 부호화/암호화시킨다, (사람이 읽기 편한)문자를 코드로 변환하는 것
디코딩(decoding) : 부호화/암호화를 해제(해독)한다(복호화), 코드를 (사람이 읽기 편한)문자로 변환하는 것
메모장, csv, 엑셀파일, 웹브라우저 등등에서 보기 편하게 보고 있는 것
=> '인코딩된 데이터'가 올바르게 '디코딩'되었기 때문
메모장, csv, 엑셀파일 등 저장하는 것
=> '인코딩'되어 저장 (컴퓨터에 저장하거나 통신할 때 인코딩방식으로 되어있어야 하므로)
-
문자집합: 정보를 표현하는 글자집합(character set) ex> ASCII 코드, 유니코드(UNICODE)
=> 유니코드: 전세계 거의 모든 문자를 2bytes 숫자로 1:1 매핑 시키는 방식 ex> '가'의 유니코드 값이 'AC00'(16진수) -
문자 인코딩 방식 : ex> UTF-8(유니코드를 8bit의 숫자집합으로 표현, 1바이트부터 4바이트까지 가변폭으로 인코딩, 아스키코드와 호환됨), ANSI, EUC-KR, CP949
AC00(16진수)=>44,032(10진수)를 8비트의 단위로 쪼개어 저장
(※https://onlywis.tistory.com/2)인코딩에 대해서
컴퓨터는 모든 글자에 하나씩 일련 번호를 매겨서 인식합니다. 이것을 인코딩(Character Encoding)이라고 합니다.
그런데 각 언어별로 번호 체계가 다릅니다. 가령 한글 윈도우의 메모장으로는 "한글 완성형 텍스트 파일"을 읽을 수 있습니다.
그러나 "일본어 Shift-JIS 텍스트"는 읽을 수가 없습니다. 메모장이 일본어 인코딩을 인식하지 못하기 때문입니다.
https://jeongdowon.medium.com/unicode와-utf-8-간단히-이해하기-b6aa3f7edf96
https://lovefor-you.tistory.com/173
3. 직렬화
4. 바이너리 데이터
이미지 읽고 저장하기
# 모듈을 읽어 들입니다.
from urllib import request
# urlopen() 함수로 구글의 메인 페이지를 읽습니다.
target = request.urlopen("http://www.hanbit.co.kr/images/common/logo_hanbit.png")
output = target.read()
print(output)
# write binary[바이너리 쓰기] 모드로
file = open("output.png", "wb")
file.write(output)
file.close()
